
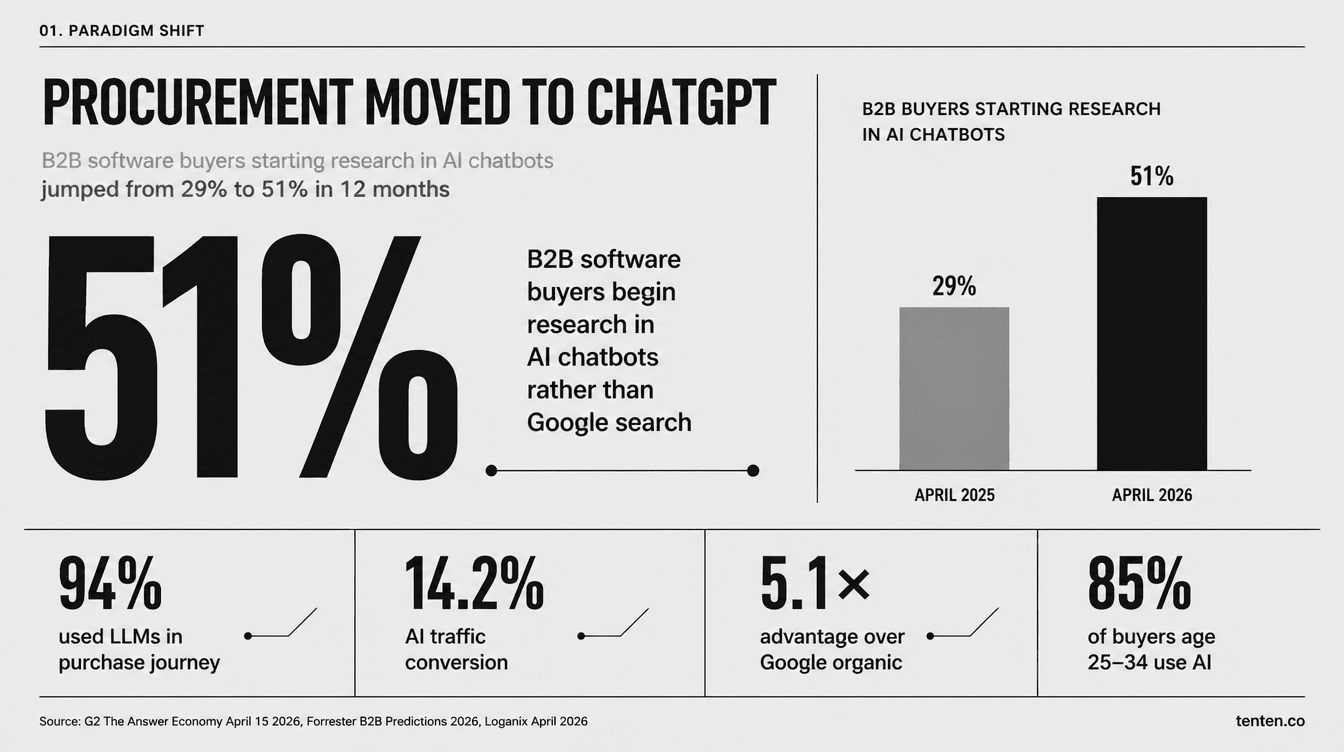
台灣半導體與工業電腦廠商的 AI 轉型,要從把 PDF 規格表搬出來、改寫成結構化資料開始。G2 在 2026 年 4 月 15 日發布的《Answer Economy》報告指出,全球 51% 的 B2B 軟體採購者,現在會在 AI 聊天機器人裡開始採購研究,而不是 Google;這個比例 2025 年中才 29%。對掌握全球 41% 工業電腦市佔的研華、市佔合計近 30% 的研華加凌華加 AAEON 集團,以及背後支撐起台灣 92% 全球先進晶片產能的整條供應鏈來說,這件事的時間表已經很緊了:潛在客戶在採購流程最前端,已經改用 ChatGPT、Claude、Perplexity 列短名單,而這些 AI 工具,根本不會打開你網站下載區裡的 PDF datasheet。
這篇文章談的不是「AI 行銷的未來」,是已經發生在每一張採購單最前面的事。Forrester 2026 B2B Predictions 顯示,94% 的 B2B 決策者在採購流程中至少用過一次 LLM;6sense 同期報告指出,B2B 買家在接觸供應商前平均已完成 70% 的決策旅程,而這 70% 的研究幾乎全都在 AI 工具裡跑。如果你的產品線是 Box IPC、嵌入式模組、AI 推論盒、半導體製程設備或工廠自動化系統,下一代採購者只會看到 AI 願意回答的那幾個廠牌;沒被 AI 列名的,等同不存在。
採購行為已經發生了什麼變化
G2 的 2026 年 3 月調查涵蓋了北美、EMEA 與 APAC 共 1,076 位 B2B 採購決策者。三組數字值得細看:71% 的買家現在會在採購流程的某個環節使用 AI 聊天機器人,比七個月前的約 60% 又往上跳了一段;69% 的買家因為 AI 提供的資訊,最終選了一家原本不在計畫內的供應商;33% 直接買了一家自己在 AI 推薦前完全沒聽過的廠商。同一份報告裡,ChatGPT 在 B2B 軟體研究的 AI 工具市佔達到 63%,剩下的份額由 Perplexity、Claude、Gemini、Copilot 分食。
行為層面的轉變更明顯。Magenta Associates 2025 年的英國調查發現,25 至 34 歲的 B2B 決策者有 85% 用 AI 工具研究供應商,55 至 64 歲的群組則只有 23%。這代表未來十年的主力採購人員,也就是現在剛升上採購經理、資深工程師、供應鏈主管的這一代,會把 AI 當作預設的供應商發現管道。Loganix 在 2026 年 4 月綜合六份獨立研究後得出的數字更直接:B2B 領域整體已有 73% 的買家在採購研究中使用 AI 工具,而從 ChatGPT、Claude、Perplexity 過來的流量轉換率是 14.2%,傳統 Google organic 只有 2.8%,差距 5.1 倍。
這就是為什麼這件事跟台灣半導體與 IPC 廠特別相關。一位德國慕尼黑的採購經理在 ChatGPT 裡輸入「Recommend ISO-certified precision die casting suppliers in Asia with automotive experience」,AI 回傳五家供應商,三家中國、一家韓國、一家日本。你的台中廠房有 IATF 16949 認證、有二十年汽車零件經驗、設備等級不輸任何人,但你不在那五個名單裡。沒有未接來電,沒有掉進垃圾信件夾的詢價,沒有錯過的展會對話。整單訂單在你不知道有機會的情況下,已經分配給了你的競爭對手。
為什麼 PDF 規格表會讓你被 AI 跳過
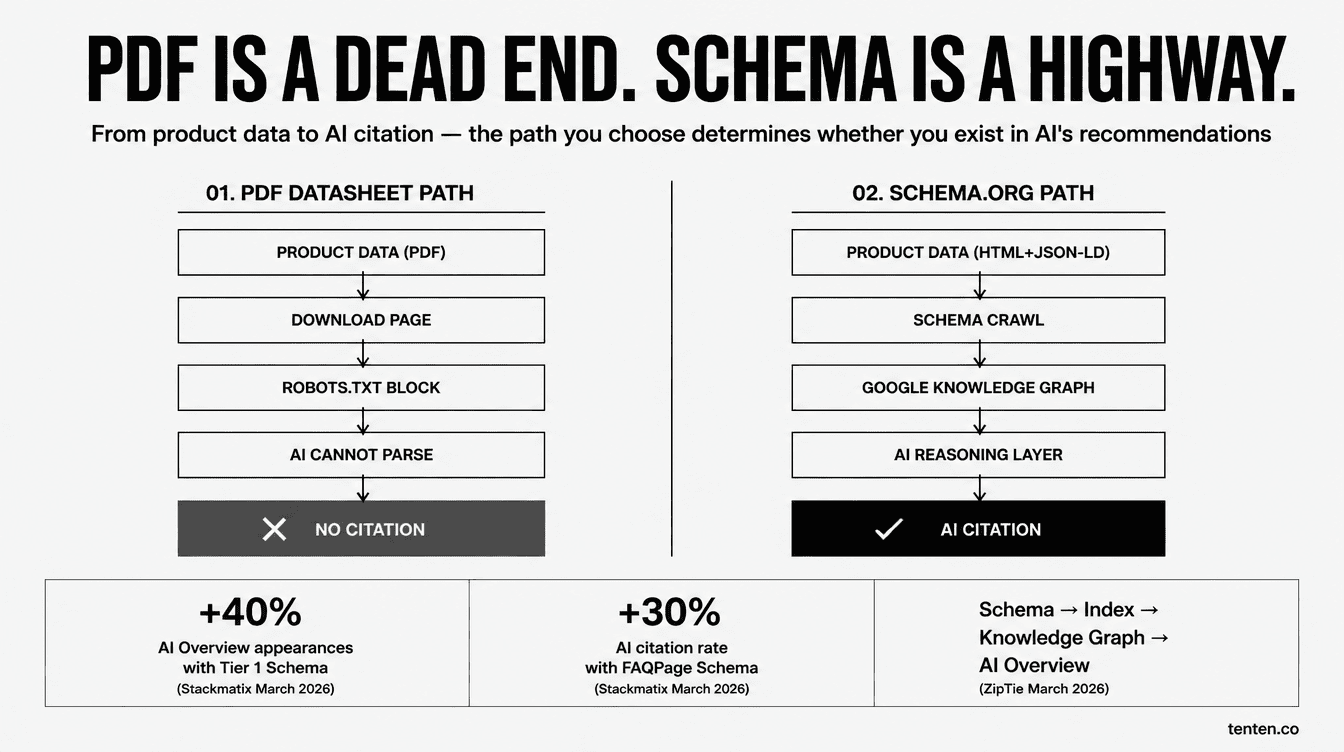
問題的根源在資料格式。AI 推薦引擎背後的運作邏輯,跟 Google 過去二十年累積的索引邏輯完全不一樣。BrightEdge 在 2026 年的研究指出,能在 Google AI Overview 裡取得高引用率的網頁,幾乎都有完整的 schema.org 結構化資料;ZipTie 在 2026 年 3 月的分析則拆解了完整路徑:Schema → Google Knowledge Graph → AI Overview citation。AI 系統不是即時讀你的網頁去理解,而是透過搜尋引擎已經「翻譯」好的結構化資料庫去取用。Google 與 Microsoft 都已公開確認 schema markup 在 AI 內容理解中扮演的角色:Microsoft Bing 的 Fabrice Canel 在 2025 年 3 月確認 schema markup 幫助 Microsoft 的 LLMs 理解 Copilot 的內容;Google Search 團隊同年 4 月也表示,結構化資料能在搜尋結果中提供優勢。
PDF 在這個鏈條裡幾乎完全被排除。AI 爬蟲的設計目標是高效率擷取,爬完一頁 HTML 後立刻去下一頁,不會停下來解析一份 50 頁的 datasheet 圖片。即使 GPTBot、ClaudeBot、PerplexityBot 確實能讀懂 PDF 文字,問題在三個層面:第一,多數工業電腦規格表是用截圖或掃描格式產生的,AI 拿到的是無法擷取的圖層;第二,下載連結通常被 robots.txt 或閘道頁面擋掉;第三也是最關鍵的,PDF 沒有 schema 標記,AI 拿到一段「Intel Atom x6425E、4 GB DDR4、IP65」也不知道這代表什麼產品的什麼規格。
對比之下,schema.org 的 ProductModel 類型本來就是為這種情況設計的。它的官方說明白寫:「ProductModel gives a datasheet or vendor specification of a product (in the sense of a prototypical description). Use this type when you are describing a product datasheet rather than an actual product, e.g. if you are the manufacturer of the product.」用 JSON-LD 把產品名稱、料號(mpn)、製造商、應用領域、operating temperature range、認證、I/O 規格全部結構化標記,AI 拿到的不再是一張看不懂的 PDF,而是可以直接組合進回答的乾淨資料欄位。
台灣 IPC 廠商的競爭結構壓力
這個問題的緊迫性,來自台灣在這個產業的市場地位。研華(Advantech)在自家 2024 公司簡介裡明確標示「No.1 Worldwide Industrial PC with 41% WW Market Share」,PitchBook 在 2026 年 3 月的資料則顯示研華 trailing 12-month 營收達 22.7 億美元。Verified Market Research 2025 年的報告把全球嵌入式工業電腦市場估在 75 億美元,預估 2033 年達 128 億美元,CAGR 6.8%。這個市場前八大玩家是研華、Kontron、AAEON、ADLINK、DFI、IEI、Avalue、NEXCOM,其中六家是台灣公司。
但這個結構正在被新型態的競爭分化。Semiconductor Insight 2026 年 1 月的單板電腦市場報告指出,研華、AAEON、ADLINK 三家合計市佔不到 30%,意思是另外 70% 的市場由超過 25 家廠商分食,定價戰打得很兇,200 美元以下級距尤其慘烈。這代表二三線台灣 IPC 廠商的壓力會比研華更大:研華有 41% 市佔、有品牌、在 27 個國家設有分公司、研發投入足以撐住 premium 定位;但年營收新台幣 10 億到 50 億這個級距的台灣 IPC 廠,原本就在價格與技術差異化中間夾層生存,現在又要面對 AI 推薦把訂單導去更早建好結構化資料的對手,時間窗口很短。
更深一層的問題是 LLM citation 的「贏家通吃」效應。BrightEdge 與 Amsive 的 2025 年聯合研究發現,AI 平台平均每個回答只引用 3 至 4 個品牌,而前 20 個域名拿走全部 AI citation 的 66%。一旦 LLM 把研華、Kontron、ADLINK 學成「Industrial PC for AI inference」的標準答案,後進者要打進這個 citation slot 的難度,會比過去做傳統 SEO 還難,因為 AI 模型會強化它已經學會的東西,而這個學習過程在 2026 年的這幾個月正在發生。
五個必須馬上動的結構化資料工程
接下來是執行細節。台灣半導體與 IPC 廠商如果要在 2026 年下半年前把 GEO 基礎建起來,有五個層次的工程要動。第一個是 Organization schema 與 sameAs 連結網,這是品牌實體在 AI Knowledge Graph 中的根節點。Stackmatix 2026 年 3 月發布的研究指出,完整實作 Tier 1 schema 的網站,AI Overview 出現次數最多增加 40%。Organization schema 必須包含 name、url、logo、address、contactPoint、description,還要把 sameAs 連到 LinkedIn、Crunchbase、Bloomberg profile、維基百科條目(如果有)、Wikidata Q-number。對研華這種規模的公司來說,Wikipedia 條目存在但常常沒被連回自家網站;對中型 IPC 廠來說,Wikidata 條目通常根本不存在,這些都是要主動建立的實體錨點。
第二個是把每一個產品 SKU 變成 ProductModel 結構化資料。這不是工程選項,是標準動作。每張產品頁要包含 name、mpn、gtin、manufacturer、image、description、additionalProperty(用來放 operating temperature、power consumption、I/O ports、certifications 等規格),以及 offers(即使 B2B 不公開零售價,也可以用 PriceSpecification 標 RFQ-only),加上 isAccessoryOrSparePartFor 把配件對應到主機。Schema.org 在 ProductModel 的官方建議裡明確寫了:「Try to provide identifiers (gtin13, gtin14, gtin8, mpn properties) and link to you as the manufacturer (manufacturer property) so that search engines can use your data to enrich offers of your products found elsewhere.」對工業電腦來說 mpn 就是料號(例如 ARK-1124H-S6A1),這個欄位是 AI 區別產品變體的關鍵。
第三是 FAQPage schema。Stackmatix 同份研究指出 FAQPage schema 平均能讓 AI 引用率提升 30%。對工業電腦廠來說,每個產品頁面下都應該有一組「這台機器能不能在 -40°C 環境啟動」「IP rating 是 IP65 還是 IP67」「支援哪幾種作業系統」「最大 PoE 輸出是多少」的 Q&A 區,回答控制在 40 到 60 字、每組問答自足可獨立引用,FAQPage JSON-LD 要包進完整的 <script type="application/ld+json"> 標籤。這個改動對研發部門來說工作量極小,技術文件本來就有這些問答,只是要從工程師的內部 wiki 搬到公開網站並加上 schema。
第四是把 PDF datasheet 變成 HTML 加 schema 並行。這是工程量最大的一步,但也是最關鍵的差異化。多數台灣 IPC 廠的網站架構是「產品頁→下載 PDF」,PDF 裡藏著完整規格、應用示意圖、訂購指南、配件清單。把這些內容拆出來,改寫成 HTML 頁面,每個 spec table 用 PropertyValue schema 標記,每個應用範例用 HowTo 或 CreativeWork 標記,每個認證用 hasCertification(schema.org 在 2024 年新增的屬性)標記。這個工程預估每個 SKU 要 2 到 4 小時,但這是讓 AI 真正讀懂你產品的唯一路徑。
第五是 Article schema 加上 author 完整 E-E-A-T 訊號。AI 推薦引擎特別重視來源作者的可信度。每篇技術文章要標 Article schema,author 要連到一個有完整資料的 Person schema(包含 jobTitle、affiliation、sameAs LinkedIn、knowsAbout 等屬性)。這個對台灣廠商來說很反直覺:多數亞洲廠商習慣用「研華技術部」或匿名發文,但 AI 模型偏好個人化、可驗證的作者實體。設一個 Chief Technologist persona,把他的 LinkedIn 整理好,所有技術白皮書都掛他的名字並用 schema 標記,這個品牌信任工程在 6 至 12 個月內會看到 citation rate 的差異。
三組關鍵供應商與工具實作對照表
執行這五個層次的工程,工具選擇會決定可維護性。下面這張表整理了不同階段的工具選項:
| 工程階段 | 推薦工具/方法 | 適用對象 | 預期產出 |
|---|---|---|---|
| Organization 加 sameAs | Schema App / Yoast SEO Premium / 手動 JSON-LD | 全公司一次性 | Knowledge Graph entity 確立 |
| ProductModel 大量產出 | InLinks / WordLift / 自製 schema generator with API | 200 個 SKU 以上廠商 | 每 SKU 完整結構化頁面 |
| FAQPage 自動化 | RankMath FAQ block / Schema App FAQ | 技術支援與行銷協作 | 每產品 5 至 10 組 FAQ |
| HTML datasheet 轉換 | 內建 CMS template 加 DAM 整合 | 工程文件部與網站開發 | PDF 與 HTML 加 schema 雙軌 |
| AI citation 監測 | Profound / Otterly / Ahrefs Brand Radar / Evertune | 行銷分析 | 週報式 citation report |
Ahrefs Brand Radar 對中型廠商的成本壓力比較小,可以先從這裡開始建測量基礎;如果預算足夠,Profound 對 B2B 領域的 ChatGPT、Claude、Perplexity 引用率追蹤更精細。Evertune 在 2026 年 1 月的研究說,B2B 公司用 schema 來定義專業領域,目的是讓 AI 系統理解品牌解決的問題;電商公司用 product schema 馬上就能讓 AI 顯示價格、可用性、評分;這個區隔在工業電腦領域同樣成立。
90 天執行路徑
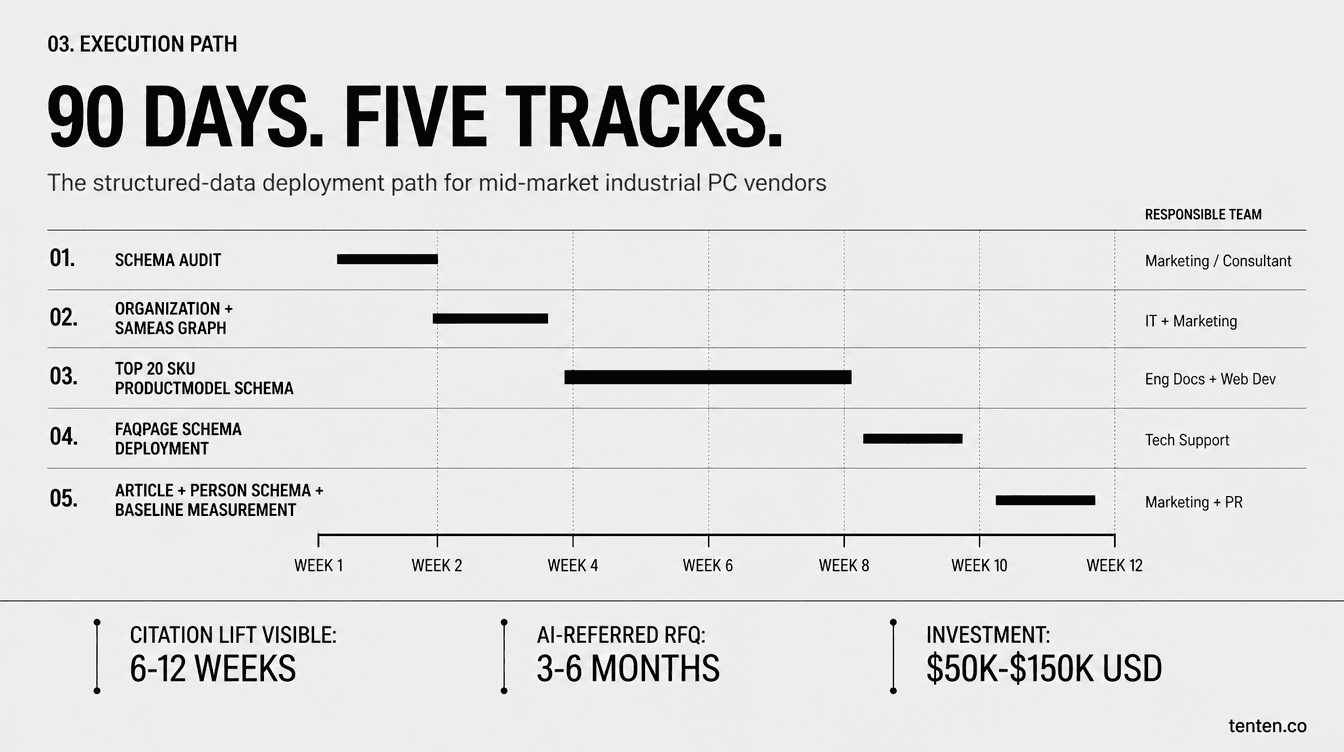
對營收新台幣 10 億到 100 億級距、SKU 數 50 到 500 之間的台灣 IPC 廠來說,90 天可以做完哪些事,這份時程比較實際:
| 週次 | 工作項目 | 主責部門 |
|---|---|---|
| Week 1-2 | 既有網站 schema 稽核(Rich Results Test 加 Schema Markup Validator) | 數位行銷/外部顧問 |
| Week 3-4 | Organization schema 加 sameAs 網路建置;提交 llms.txt 給 GSC | IT/行銷 |
| Week 5-8 | Top 20 SKU 全套 ProductModel schema;HTML datasheet 改寫 | 工程文件加網站開發 |
| Week 9-10 | 每 SKU 加 FAQPage schema(含完整 <script> 標籤) |
技術支援整理問答 |
| Week 11-12 | Article schema 加 Person schema for 技術部主管;AI citation baseline 量測 | 行銷加 PR |
這份時程的成本結構,外包顧問加內部人力大約落在新台幣 150 萬到 500 萬之間,比一場大型展會的攤位加出國團費還便宜,但時間窗口已經很緊。
跟主流 SEO/GEO 觀點的分歧
這裡要誠實處理一個產業內部的爭議。Search Engine Land 在 2025 年 11 月用自家網站做了 llms.txt 實驗:從 8 月中到 10 月底,llms.txt 頁面收到的 Google-Extended、GPTbot、PerplexityBot、ClaudeBot 訪問次數是 0。OtterlyAI 的 90 天測試結果更慘,62,100 次 AI bot requests 裡只有 84 次去到 llms.txt,0.1%。這代表 llms.txt 本身不是 GEO 的解方,主要 AI 廠商目前還是透過 robots.txt 控制爬蟲、透過正常 HTML 解析取得內容。但 dev5310 在 2026 年 2 月的反例顯示,把 llms.txt 直接提交到 Google Search Console 後,Google 當天爬取,隔天 AI Mode 開始引用。所以結論是 llms.txt 不是萬靈丹,但作為「品牌身分摘要」(brand identity layer)放在固定路徑,配合 Search Console 主動提交,對中大型台灣廠商還是值得投入的低成本動作。
更重要的爭議是 schema 對 LLM 引用的直接影響。Search/Atlas 在 2024 年 12 月的研究指出,schema markup coverage 跟 citation rate 之間沒有直接相關性,這跟 BrightEdge 的結論看似衝突。實際上兩邊都對:schema 不是直接跟 LLM 講話,schema 是把資料餵進 Google Knowledge Graph 跟 Bing index,這些 index 才是 ChatGPT search、Google AI Overview、Perplexity 抓資料的地方。所以正確的心智模型不是「裝了 schema → AI 馬上引用我」,而是「裝了 schema → 我的實體在 Knowledge Graph 裡更清楚 → AI 在生成回答時更可能拿到我的資料 → 引用率上升」。對台灣 IPC 廠來說,這個間接路徑反而是優勢,因為 Knowledge Graph 是長期資產,建好之後即使 AI 平台換代也不會歸零。
常見問題
我們是 OEM/ODM 廠,產品都用客戶品牌出貨,做 GEO 還有意義嗎?
有,但策略要轉向「能力(capability)加認證(certification)加應用場景(use case)」三個實體。OEM/ODM 廠不能用 ProductModel 突顯自家產品,但可以用 Service schema、Organization schema 加上 hasCredential、makesOffer,標註你的製程能力(surface mount、wave soldering、specific test capabilities)、認證(IATF 16949、ISO 13485、UL)、產業經驗(automotive、medical、aerospace)。當外國採購在 ChatGPT 問「Find me a Taiwan EMS partner with IATF 16949 and 10+ years automotive experience」,AI 用的就是這些 schema 欄位。
我們的研發資料是商業機密,全都搬上網不會出問題嗎?
要分層。產品的功能規格、認證、適用環境條件本來就會出現在公開 datasheet,這些對應 schema 化沒問題;研發架構、製程參數、生產良率、客戶名單這些屬於商業機密的,繼續放在 NDA 後面、用閘道頁面控制。GEO 要曝光的是「能解決什麼問題」,不是「怎麼解決」。
我們的網站是十年前用 ASP 寫的,加 schema 工程量很大,有沒有快速版?
有。優先順序是:(1) 在 home page、about page、contact page 加 Organization schema,這個一週可以做完;(2) Top 20 暢銷 SKU 手動加 ProductModel schema,一個 SKU 約 2 小時;(3) 每個產品頁加 5 組 FAQPage schema,半天可以做完一個產品;(4) 把產品 datasheet HTML 化是長期工程,可以分季完成。前三項做完,AI citation rate 通常在 6 到 12 週之間會看到首次提升。
中文網站跟英文網站要怎麼分工?
英文版優先。B2B 海外採購對台灣廠商的詢問流量幾乎全部用英文,ChatGPT、Claude 對英文 schema 內容的處理也比繁中精細。建議結構是英文站做完整 schema 加完整內容深度,繁中站作為國內市場的鏡像,schema 用相同結構但語言切到 zh-Hant,hreflang 標記做好。
投資 GEO 多久會看到訂單轉換?
第一輪 schema 部署後,6 到 12 週會看到 AI citation 出現的頻率變化,這是領先指標。實際 AI referral traffic 進入網站、轉換成詢價,根據業界經驗一般在 3 到 6 個月看到變化。但這個轉換率本身比 Google organic 高出 5.1 倍(Exposure Ninja 2026 年 3 月分析),所以 ROI 計算要看的是「每筆 AI referral 詢價的價值」,不是「總流量」。
延伸閱讀
對結構化資料的基本概念不熟的人,可以先看 SEO 結構標記六種類型 跟 Featured Snippets 與 Structured data。GEO 與 AEO 的整體框架可以從 AI 搜尋優化 GEO/AEO 全新演進、2026 年 GEO 終極清單 入門。要追蹤 AI Overview 的引用情況,7 套 AI Overview 引用追蹤工具 跟 GA4 追蹤 AI 流量設定 是必備工具。對台灣工業電腦業 AI 轉型有興趣的,工業電腦 B2B 企業的 AI 轉型指南 跟 台灣工業電腦品牌如何利用 Shopify Plus 打造國際級 B2B 銷售平台 兩篇可以對照看;半導體產業視角可以參考 AI 半導體:人工智慧時代的核心推手 跟 台積電技術革新從 N3 到 1.4 奈米。
實戰案例上,GEO 優化實戰:AI 搜尋引擎如何在 3 天內為電商帶來 1,500 筆訂單 跟 用 GEO 把 Shopify 變成 AI 會推薦的商店 雖然是電商案例,但結構化資料的工程邏輯跟 IPC 廠完全一致。要進一步了解 ChatGPT、Gemini、Perplexity 三家 AI 引擎的索引差異,讓 ChatGPT、Gemini、Perplexity 認識你的網站 把細節寫得很清楚。
權威來源
- G2 — The Answer Economy: How AI Search Is Rewiring B2B Software Buying (April 2026)
- PRNewswire — New G2 Research: Half of B2B Software Buyers Now Start Their Research With AI Chatbots
- Loganix 2026 B2B AI Buying Behavior Analysis (Yahoo Finance)
- Schema.org — ProductModel official specification
- Search Engine Land — How schema markup fits into AI search
- LeadScale — AI Search and AI Agents in B2B Buying: Answers Before Clicks
- DigiTimes — Advantech tops US$635 million in 1Q26 revenue on edge AI demand surge
- U.S. Trade.gov — Taiwan Semiconductors including chip design for AI
Author Insight
過去半年我們協助一家年營收約新台幣 30 億的中型工業電腦廠商重整網站結構化資料,最初的 baseline 是 ChatGPT 在 30 個產業相關 prompt 裡只引用了這家公司一次。第一階段做完 Organization schema 與 Top 20 SKU 的 ProductModel schema(約六週工程),第八週開始看到 ChatGPT 引用率上升到 7/30,Perplexity 從零變成 4/30。最有意思的觀察不是流量數字,是業務團隊回報的詢價內容變化:AI referral 帶進來的英文詢價,平均寫得比過去 organic 詢價更具體,會直接寫出料號、operating temp、I/O 數量這些規格細節,因為買家是被 AI 用結構化方式 onboard 過來的。這代表 schema 不只是 SEO 工程,它在實質改變買家進入銷售漏斗時的資訊密度。
對工業電腦廠來說,PDF 規格表本身不是問題,問題是 PDF 是「產品資料的終點」而不是「起點」。把 PDF 當作對工程師展示用的最終形式 OK,但同樣的資料必須在 HTML 加 schema 的版本裡先存在,AI 才有辦法把你列進供應商短名單。十年前 mobile-first indexing 改變了台灣 B2B 廠的思維(從桌機優先到響應式優先),這次 AI-first indexing 是更大的典範轉移,但時間窗口比 mobile 那次更短。
跟 Tenten 預約諮詢
我們最近協助台灣半導體設備、工業電腦、自動化系統三個垂直領域的 B2B 客戶執行 schema 部署建立 PIM 服務層與 GEO 監測,從 baseline 量測、Top 20 SKU 結構化資料工程到 AI citation 監測 dashboard 設置,平均 12 週看到首次 AI 引用率提升。如果你想討論 GEO 在你的產品線怎麼落實,歡迎跟 Tenten 團隊預約諮詢,我們可以先做一次免費的網站 schema 稽核,告訴你目前在 ChatGPT、Claude、Perplexity 三個平台的 baseline 引用率長什麼樣子。
- Is AI Erasing Your Brand? The 2026 GEO & AEO Survival Guide | by Ewan Mak
- 半導體供應商的 AI-Native 電商轉型:Akeneo PIM CE + Shopify Plus + Claude Code MCP 完整架構拆解
- 台灣單車外銷不能只看美國:關稅壁壘下的市場分散策略與歐亞成長機會
- 用 AI 內容系統,從零做到百萬觀看數 - 打造內容生產線
- 你的品牌正在被 AI 淘汰?2026 年必懂的 GEO 與 AEO 生存法則
- AI 時代流量密碼!GEO 場景覆蓋策略讓你的品牌被瘋狂推薦
- 讓 AI 瘋狂推薦你的品牌!GEO 場景覆蓋策略全攻略
- 台灣製造業警訊!B2B採購全靠ChatGPT,你的PDF規格表正把百萬訂單推走?
- Reddit 的 AI 增長密碼:AI 翻譯如何重塑全球搜尋版圖
- Google AI Mode 排名攻略:利用概念連結與品牌聲量佔領搜尋新戰場
- 沒人告訴你的 2026 SEO 真相 🤫 品牌權威 > 關鍵字











