Meta-Meta-Prompting 拆解:Garry Tan 用 gstack + gbrain 打造個人 AI 引擎的真實架構
Y Combinator 執行長 Garry Tan 在 2026 年公開了一個觀念,叫做 Meta-Meta-Prompting:一個會生成新技能的技能(meta-skill that creates skills)。這不是抽象哲學;它對應他每天凌晨兩點還在寫程式、同時管理 YC 全職工作的真實工作流;他把整套系統用 MIT License 開源,一個叫 gstack(截至 2026 年 5 月,GitHub 約 9.4 萬星、1.39 萬 fork),一個叫 gbrain(約 1.49 萬星)。他在公開文章裡用「fat skills, fat code, thin harness」總結了這個架構的核心。
如果你關注 Claude Code 或 OpenClaw 的演進,這篇值得讀完。原因不在於 VC 又在吹捧 AI;它代表目前能找到最完整的一個人加 AI Agent 等同於一支工程團隊的工程方法論。
為什麼 Meta-Meta-Prompting 是現在最重要的概念
Garry Tan 講了一個具體例子。他讀 Pema Chödrön 的《When Things Fall Apart》——藏傳佛教談痛苦、放下、不安定感的經典,22 章、162 頁。他叫他的 AI Agent 跑一個叫 book-mirror 的技能,做了三件事:把全書 22 章抽取出來,為每一章開一個 sub-agent 同時跑,左欄寫作者觀點、右欄映射到他自己的真實人生。
40 分鐘後,他拿到一份 3 萬字的腦圖,每一章都連結到他的具體經歷:某次跟創辦人凌晨對話、某次治療師指出的模式、某個週四跟弟弟散步時冒出的想法。如果換成時薪 300 美元(約新台幣 9,600 元)的治療師讀這本書、再應用到他的生活,40 個小時也做不完,原因是治療師沒辦法存取 Garry 過去一年的會議筆記、創辦人關係圖譜、閱讀紀錄。
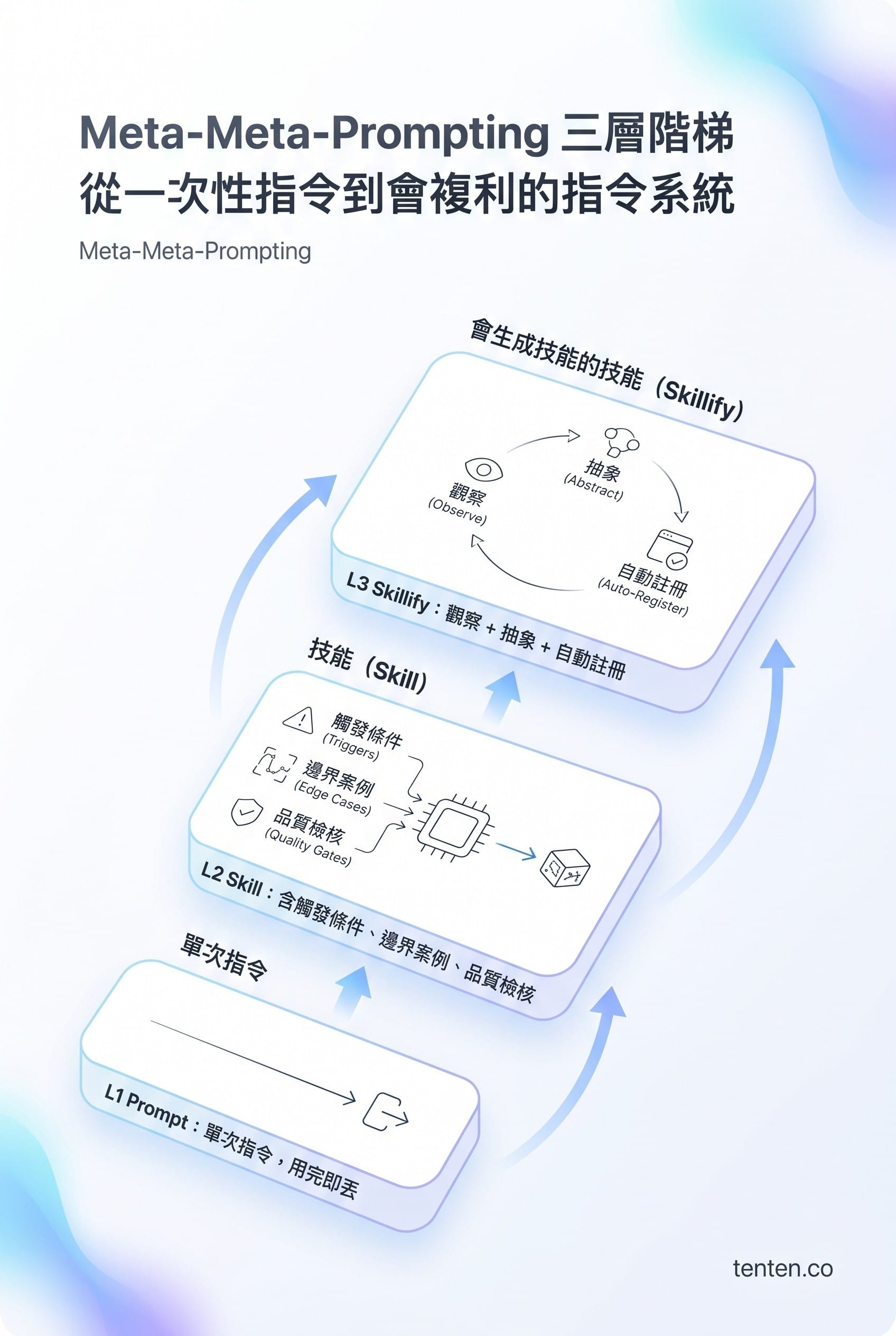
這就是 Meta-Meta-Prompting 的價值層級:
| 層級 | 名稱 | 例子 |
|---|---|---|
| L1 | Prompt | 「幫我摘要這本書」 |
| L2 | Meta-prompt(Skill) | book-mirror 技能:22 章拆解 + 雙欄映射 + 來源引用 |
| L3 | Meta-meta-prompt(Skillify) | /skillify 指令:把剛剛做的事情抽象成可重複技能 |
第一次做 book-mirror 時,輸出有三個關於 Garry 家庭的事實錯誤。他爸爸來自香港和新加坡、媽媽來自緬甸,但 AI 寫成父母離異、在香港長大。他加了強制性的事實核查步驟,把 Claude Opus 4.7(負責抓出精確錯誤)、GPT-5.5(負責補缺失脈絡)和 DeepSeek V4-Pro(負責標出太過泛泛的描述)跨模型評分。然後他做了關鍵的一步:跑 /skillify,把整個流程包成一個含觸發條件、邊界案例和品質檢核的技能檔,註冊到 resolver 裡。
接下來他做的每一本書鏡像(20 多本,包括 Bertrand Russell 的自傳、Hermann Hesse 的《流浪者之歌》、Hamming 的《The Art of Doing Science and Engineering》)都自動受益於這個累積。第二本書鏡像知道第一本,第二十本知道前面所有。
「fat skills, fat code, thin harness」的工程結構
Garry 反覆強調的架構觀念,跟一般人想像的 AI 工具完全相反:
| 元件 | 角色 | 厚度 |
|---|---|---|
| Harness(執行核心) | OpenClaw runtime;接收訊息、決定哪個技能該被叫用、分派任務 | 薄,只有幾千行路由邏輯 |
| Skills(技能) | 100 多個 markdown 檔,每個是一個自足的工作流 | 厚,每個技能都是一份詳細指令 |
| Data(資料層) | 約 10 萬頁結構化知識庫(人物、公司、會議、書本、想法) | 厚,每天成長 |
| Code(程式碼) | 100+ 個 cron job 每天跑(社群、Slack、email 抓取) | 厚,但意義不在程式碼本身 |
| Models(模型層) | Opus 4.7 跑精確、GPT-5.5 跑回想、DeepSeek 跑創意、Groq + Llama 跑速度 | 可互換,由技能決定該叫哪個 |
這對市場上多數 AI 工具的設計哲學是直接挑戰。傳統做法是把智能包進框架本身,LangChain 是最明顯的例子。Garry 的主張是:智能應該存在於技能裡,runtime 只是路由器。當技能愈來愈厚、資料愈累積、技能之間互相呼叫(book-mirror 會去呼叫 brain-ops、enrich、cross-modal-eval、pdf-generation),整個系統就會自己加速。
實際使用上,他寫的技能包括:
meeting-ingestion:每場會議結束後抓逐字稿、產出結構化摘要,再走一遍會議裡提到的每個人和公司,把討論內容更新到那些 brain page 上。會議摘要不是終點;實體傳播(entity propagation)回填到每個人物頁、公司頁,才是真正的價值。enrich:給一個人名,它從五個來源抓資料、合併成一份含職涯軌跡、聯絡資訊、會議歷史、關係脈絡的 brain page,每個事實都有出處。media-ingest:處理影片、音訊、PDF、截圖、GitHub repo。轉錄、抽取實體、歸檔到 brain 對應位置。perplexity-research:腦增強網路研究。先查 brain 已知什麼,再去 Perplexity 補新資訊,避免重複捕捉已有的知識。
他每天跑 100 多個 cron job:社群媒體、Slack、email、行事曆,凡是他會關注的,OpenClaw 和 Hermes Agent 也會關注。
gbrain:能複利的知識結構
gbrain 是這套架構裡最特別的一塊。它不是向量資料庫,也不是傳統的 RAG。每一頁的結構如下:
- 頂部:compiled truth(編譯真相),當前最好理解的事實,會被覆寫
- 中段:append-only timeline(只能追加的時間線),按時序排列的事件,不能編輯
- 底層:raw data sidecars(原始資料側檔),來源材料
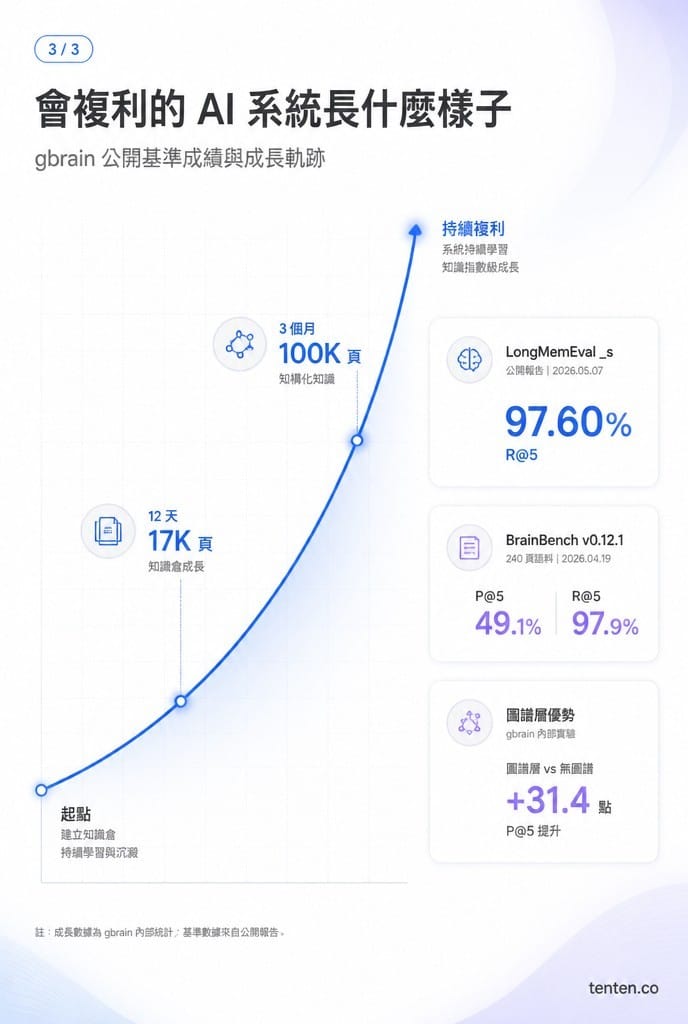
根據 gbrain 開發團隊公開的 BrainBench 評測(2026 年 5 月 7 日),gbrain-hybrid 在 LongMemEval _s 的 500 題公開基準上跑出 97.60% R@5,比 MemPalace 公開的 baseline 高 1.0 個百分點,而且整個檢索流程裡完全沒有 LLM 參與。他們自家的 240 頁 BrainBench 上 P@5 達 49.1%、R@5 達 97.9%,比關掉知識圖譜層的版本高 31.4 個百分點。
每次 brain page 被寫入時,會抽取實體引用、自動建立帶型別的連結(attended、works_at、invested_in、founded、advises),全程零 LLM 呼叫。這個圖譜層是性能的關鍵。
舉個例子說明它怎麼複利。Garry 在 office hours 見一位創辦人。系統做這些事:建立或更新這位創辦人的 person page、公司 page、交叉引用會議筆記、檢查他之前有沒有見過、浮出上次討論內容、查 YC 申請資料、抓最新指標、判斷他現有的投資組合公司或人脈裡有沒有人能幫上對方。等他走進下一場跟同一位創辦人的會議時,系統已經備好完整的 context pack。
兩者的差別:檔案櫃儲存東西,神經系統連結東西、標記變化、浮出對當下相關的內容。
對用戶意味著什麼
我們最常聽到的反對意見有兩種。第一種:「這是 VC 圈的炫技,跟真實業務無關。」第二種:「我們公司不可能讓員工把資料放到自己的 Git 倉。」
第一種反對其實是錯的。把 Garry 的系統拆開看,真正在動的工程觀念是:技能可組合、資料層獨立於模型、系統能透過使用而自己變強。這三點對任何認真做 AI 導入的企業都成立,只是大多數人卡在還在用 ChatGPT 當聊天視窗的階段。
第二種反對成立。答案是建一個符合企業內控規範的版本。Tenten 自己內部用 OpenClaw 部署,所有腦資料在內網的 Git 倉裡,搜尋層用 pgvector 加 hybrid search,敏感性 person page 用 ACL 控制存取。本質和 Garry 的架構一樣,只是合規層比較厚。
比較:gstack/gbrain vs. 其他個人 AI 框架
| 框架 | 定位 | GitHub 星數(2026 年 5 月) | 設計重心 |
|---|---|---|---|
| gstack | Claude Code 技能包,CEO/設計師/工程經理/QA 角色 | 約 9.4 萬 | 編碼工作流 |
| gbrain | OpenClaw/Hermes Agent 的長期記憶層 | 約 1.49 萬 | 個人知識圖譜 |
| OpenClaw | AI Agent 執行 runtime | 約 24.7 萬 | 通用 Agent runtime |
| LangChain | LLM 應用框架 | 約 11 萬 | 把智能包進框架 |
| Mem0 / Zep / Letta | 多租戶記憶層 | 各約 2-3 萬 | SaaS 級記憶服務 |
關鍵差異在於 gbrain 要解決的問題不在多租戶記憶層那一塊,跟 Mem0 或 Letta 是不同象限。它對齊的是 Vannevar Bush 1945 年提出的 Memex:一個個人擁有、Agent 操作、純文字 markdown 為主、可 diff、可分支、可版本控管、人類可讀的知識倉。
為什麼這對開發者來說是分水嶺
Garry 在文章裡引述 Andrej Karpathy 在 No Priors podcast 上 2026 年 3 月講的一句話:「我大概從去年 12 月開始就沒打過一行程式碼了。」這不是修辭,是字面意義。
技術社群正在分化成兩種人:把 AI 當聊天視窗的人,和把 AI 當作業系統的人。後者建技能、建腦、建 cron job、建跨模型評分,所有日常工作流被吸進一個會複利的系統。每場會議讓 brain 變厚一點,每讀一本書讓 context 變豐富,每寫一個技能讓下次工作流更快。兩個月後系統強度十倍,再兩個月再十倍。
這跟用 ChatGPT 訂閱費 20 美元換來的生產力小幅提升不是同一件事。同樣的 AI 模型,落在不同架構上,產出差距可能是百倍級。
常見問題
Meta-Meta-Prompting 到底跟一般 Prompt Engineering 差在哪?
傳統 prompt engineering 是寫單次指令給 LLM,輸出用完即丟。Meta-Meta-Prompting 寫的是會生成新指令的指令;/skillify 觀察使用者剛剛做了什麼,抽取可重複的模式,寫成含觸發條件、邊界案例和品質檢核的技能檔,註冊到 resolver。下次相似任務出現時,技能會自動觸發。差別在於它會複利。
gstack 和 gbrain 必須一起用嗎?
不必。gstack 是 Claude Code 的技能包,主要服務寫程式工作流;gbrain 是 OpenClaw 或 Hermes Agent 的記憶層,主要服務知識管理。兩者透過 hosts/gbrain.ts 整合,但可以分別獨立使用。如果你目前主要需求是寫程式,先裝 gstack;如果你想建個人知識系統,先裝 gbrain。
一般中小企業有沒有可能採用這套架構?
可以。關鍵不是工具本身,是觀念:技能優先(不是 prompt)、資料層獨立於模型、系統能透過使用而變強。Tenten 自己用 OpenClaw 加 Claude Skills 為客戶建內部知識系統,3-4 人團隊就能跑起來。資安要求高的客戶用本地部署,搭配 ACL 控制。
90 天後,知識倉裡會有多少資料?
按 Garry 公開的數據,他的 brain 在 12 天內累積到 1.7 萬頁,三個月達 10 萬頁。一般使用者的成長曲線會慢一些,但只要把會議逐字稿、email 摘要、閱讀筆記、社群擷取自動化跑進來,幾週內就會有幾千頁的累積。重點不是頁數,是頁面之間的連結密度,後者才是知識圖譜複利的真正來源。
我該如何開始建自己的個人 AI 系統?
四個步驟:第一,挑一個 harness(gstack、Claude Code、OpenClaw、或從 Anthropic SDK 自建),保持薄。第二,開一個 brain,gbrain 一個指令就裝好。第三,做一件你真的在意的事,例如寫一份報告、研究某個人、分析投資組合,用 Agent 跑完並跑到滿意為止。第四,跑 /skillify,把這次的流程抽成可重複技能。然後重複。六個月後你會有一個沒有 chatbot 能複製的東西,因為價值不在模型,在你教給系統的關於你自己生活、工作和判斷的東西。
Author Insight
我最大的觀察是:開始的人和沒開始的人,差距不是線性,是指數的。前後我們接觸過十多家金融、製造、媒體、消費品產業的客戶,這個觀察反覆出現。
具體一點。一位金融業客戶的 CTO 三月時花了大概 6 小時做完 gbrain 初始安裝、把過去 12 個月的會議逐字稿匯入。我五月再跟他聊,他說團隊每週省下大約 8 小時找上次討論的時間,但更重要的是會議品質變了。進會議前 Agent 已經把對方的所有歷史、爭議點、未完成議題備好。團隊不需要在會議上重新熱身。
另一個觀察:技能可組合性的價值被嚴重低估。我們幫客戶建第三個技能時,會發現它能呼叫前兩個;建第十個時,前面九個都成了它的工具。這是工程觀念的勝利,不是 AI 模型的勝利。任何認真做 DevOps 或 microservice 的人都會直覺認同這套設計,差別只是把同樣的觀念搬到 LLM 工作流上。
最後一個觀察我想老實說。半夜兩三點,整個城市都安靜下來的時候,我們的 Agent 還在跑,抓逐字稿、解析 email、更新 person page。我看著 Slack 跳出今天 Agent 寫好的 PR、明天會議的 context pack、上週投資組合公司的指標變化警報。這讓人有點毛,不是科幻片那種毛,是發現自己已經回不去手動模式的那種毛。但我也說不上來該怎麼形容那種複利在你身上發生的感覺。
Garry 在他的文章裡寫得直白:未來屬於建立會複利 AI 系統的個人,而不是使用公司中心化 AI 工具的個人。這句話如果在 2024 年講會像 VC 推銷話術;在 2026 年 5 月講,它已經是工程現實。
引用來源
- GitHub — garrytan/gstack 完整 README 與 23 種技能說明
- GitHub — garrytan/gbrain Agent Brain 架構文件
- GitHub — garrytan/gbrain-evals 公開基準測試 LongMemEval _s 報告
- TechCrunch — Why Garry Tan's Claude Code setup has gotten so much love, and hate
- Y Combinator Startup Library — Inside Garry Tan's AI Coding Setup
- Augment Code — Garry Tan's gstack hits 89.7K stars: what developers should know







