AI 編碼助手最大的痛點是失憶——每次對話重來,上一輪學到的程式架構、踩過的坑、做過的決定全部歸零。一位開發者用 Obsidian 筆記庫、自建 MCP Server 和多 Agent 調度器「Daniel」,把 Claude.ai、Claude Code 跟 Codex 串成了同一個大腦,月成本大約 USD 60。 這套系統的原始碼已經在 GitHub 上以 MIT 授權公開,任何人都可以 fork 回去改。截至 2026 年 3 月,Google 也在 GoogleCloudPlatform/generative-ai repo 裡發布了類似概念的「Always-On Memory Agent」,用 Gemini 3.1 Flash-Lite 和 SQLite 做持久記憶,不需要向量資料庫。兩個專案共同指向一個方向:AI Agent 的記憶層正從「可有可無」變成「基礎建設」。
問題出在哪:AI 的每日失憶症
用 Claude Code 或 Codex 寫過幾個月程式的人大概都碰過這件事:昨天花 45 分鐘搞清楚的認證流程,今天開新 session 又得從頭解釋。上次決定用 JWT 而不用 session cookie 的理由?AI 不記得。三天前找到的 ORM lazy loading 的 bug?也忘了。
這個問題的根源是 LLM 的 context window 機制。每次對話結束,除非你手動把資訊貼回去,否則下一輪對話看不到上一輪的內容。Claude.ai 內建的 Memory 功能雖然會記住一些偏好和事實,但粒度不夠細——它不會幫你記住某個 codebase 裡哪個模組的邊界條件容易出問題。
EchoVault 的作者 Muhammad Raza 在 2026 年 2 月的文章裡寫得很直白:「這就像跟一個每天晚上都失憶的天才同事工作。」
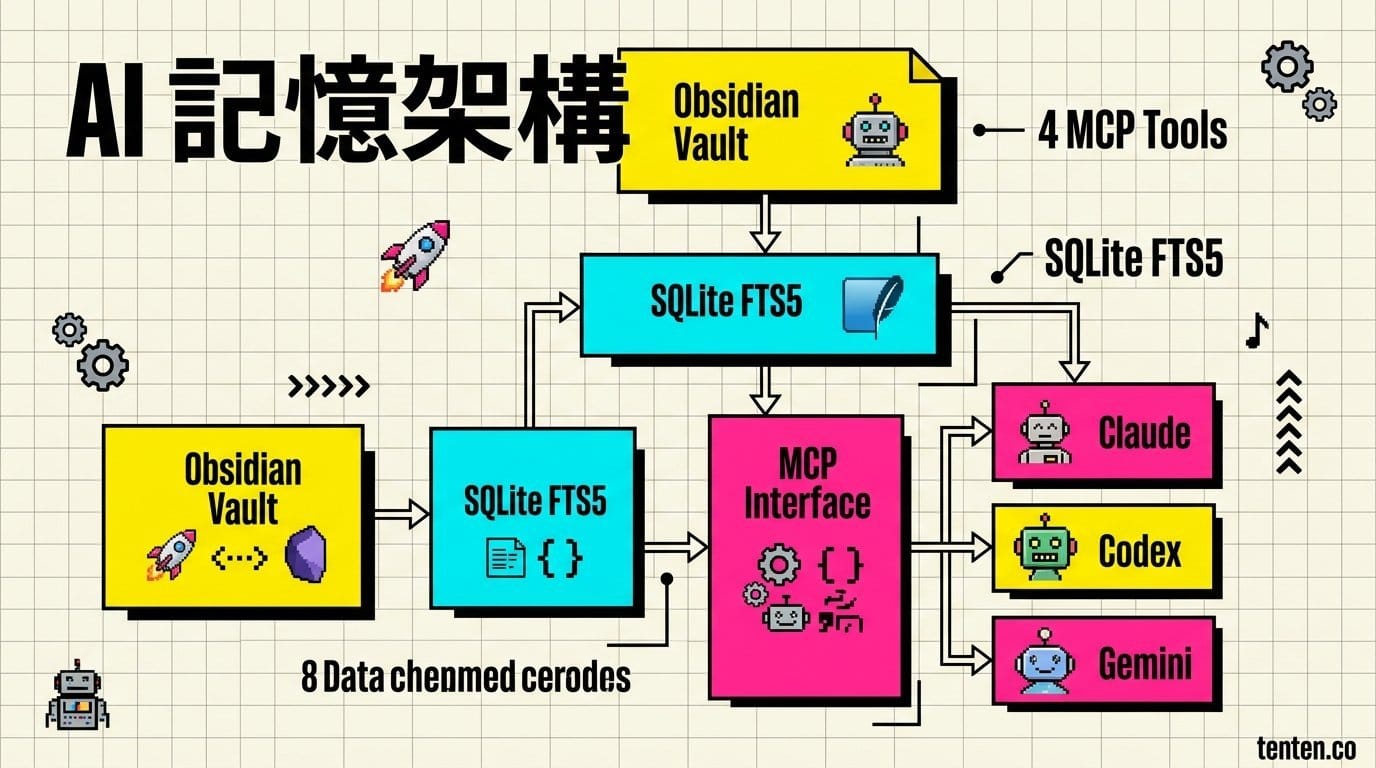
解法架構:Obsidian → SQLite FTS5 → MCP → 多個 AI Agent
開發者 willynikes2 把整套系統拆成兩個開源專案:
Knowledge Base Server(知識庫伺服器)
GitHub: github.com/willynikes2/knowledge-base-server
核心做的事很單純:把 Obsidian 筆記庫的 Markdown 檔案餵進 SQLite 資料庫,用 FTS5(Full-Text Search 5)做全文檢索,再透過 MCP(Model Context Protocol)介面讓 AI Agent 查詢。
技術堆疊:
| 元件 | 技術選擇 | 為什麼這樣選 |
|---|---|---|
| 儲存 | SQLite FTS5 | 不需要獨立的資料庫服務,單檔即部署 |
| 介面 | MCP + Express HTTP | MCP 讓 Claude Code 原生接入;HTTP 讓其他 Agent 也能用 |
| 筆記源 | Obsidian Vault Sync | Obsidian 是 Markdown,不綁格式,人可以直接編輯 |
| 搜尋工具 | kb_search, kb_list, kb_read, kb_ingest | 4 個 MCP tool,覆蓋搜尋、瀏覽、讀取、匯入 |
| 部署 | 自架 VPS | 不依賴雲端服務,USD 60/月跑三個 AI Agent |
這裡有一個刻意的設計取捨:不用向量資料庫(vector database)。作者認為在他的使用場景裡,FTS5 的關鍵字搜尋加上 token 優化就夠用了。Google 的 Always-On Memory Agent 也做了一樣的取捨,用 SQLite 直接存結構化記憶,不走 embedding pipeline。
Agent Orchestrator「Daniel」
GitHub: github.com/willynikes2/agent-orchestrator
這是一個多 Agent 調度器,把 Claude、Codex 和 Gemini 的 CLI 包在一起,三個 Agent 共享同一個知識庫。實際作用:
- 當 Claude Code 觸發速率限制或服務中斷時,自動把工作交給 Codex 或 Gemini,context 不中斷
- 每個 session 結束後,AI 自動更新自己的指令檔(CLAUDE.md),記錄這次學到了什麼、哪些模式有用
- 經過 100 多個 session 之後,AI 對特定 codebase 的理解深到可以一次寫出乾淨的程式碼
作者形容的「self-learning loop」本質上就是 Context Engineering 的實踐:每一輪對話產出的知識不會消失,而是累積成下一輪的 context。
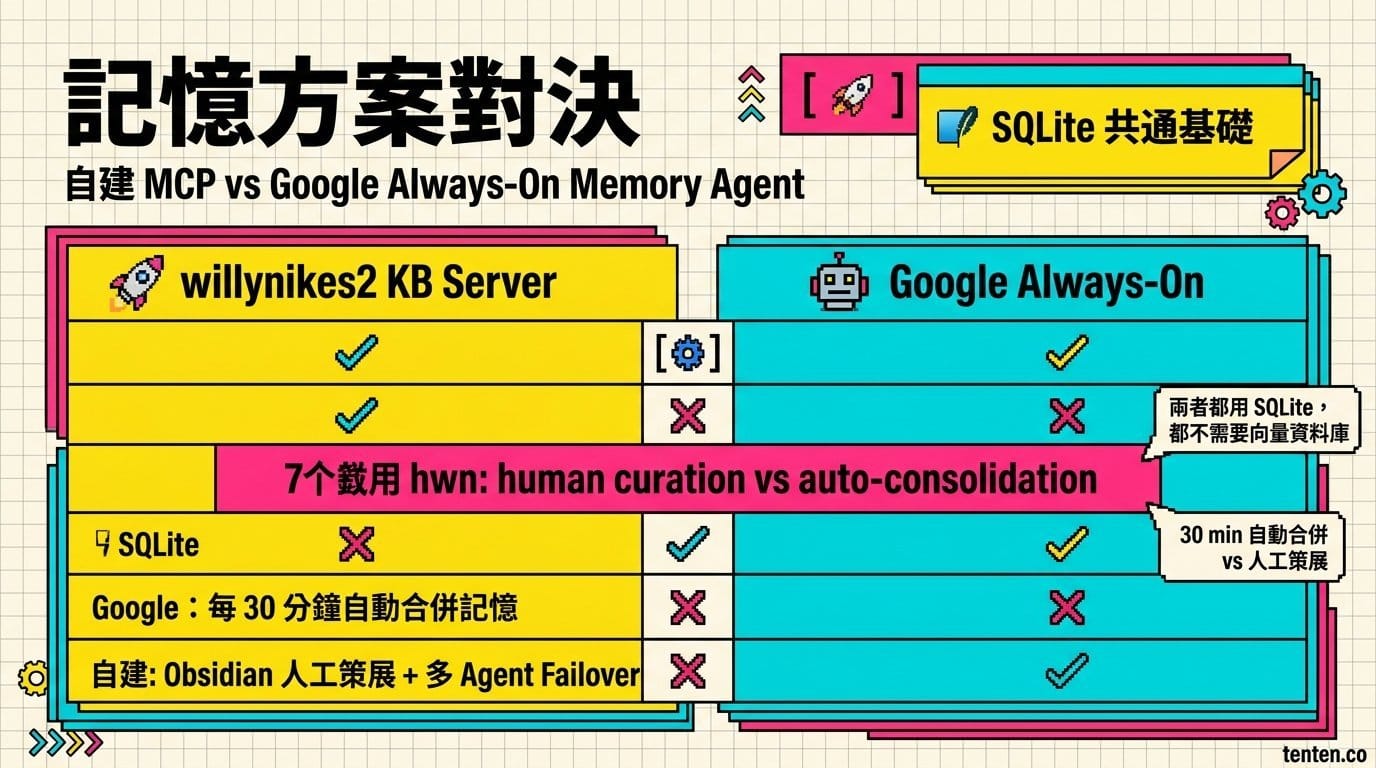
同一個方向:Google Always-On Memory Agent
2026 年 3 月 3 日,Google 的 Shubham Saboo 在 GoogleCloudPlatform/generative-ai repo 裡提交了 Always-On Memory Agent,MIT 授權。VentureBeat 在 3 月初報導了這個發布。
架構跟 willynikes2 的系統有很高的相似度:
| 比較維度 | willynikes2 Knowledge Base Server | Google Always-On Memory Agent |
|---|---|---|
| 儲存 | SQLite FTS5 | SQLite(memories, consolidations, processed_files 三張表) |
| 向量搜尋 | 不用 | 不用 |
| 記憶整理 | 人工透過 Obsidian 策展 | Agent 每 30 分鐘自動合併、去重 |
| 多模態 | 文字為主 | 文字 + 圖片 + 音訊 + 影片 + PDF(27 種檔案格式) |
| LLM | Claude / Codex / Gemini(外部) | Gemini 3.1 Flash-Lite(內建) |
| 多 Agent | 有,Daniel 調度器 | 內部有 IngestAgent / ConsolidateAgent / QueryAgent,但不跨獨立 Agent |
| 人工策展 | 有(Obsidian 是人可以直接編輯的) | 無 |
| 開源授權 | MIT | MIT |
| 星數(截至 2026/03) | 0 | 隨 GoogleCloudPlatform repo |
兩個專案最關鍵的共同點是:都選了 SQLite,都跳過了向量資料庫。
Google 那邊的邏輯是讓 LLM 自己讀、想、寫結構化記憶,省掉 embedding model、chunking strategy、index 同步這些基礎設施。VentureBeat 引述的分析也指出,這個取捨把效能問題從「向量搜尋的延遲」移到了「模型推理的延遲和長期行為穩定性」。
willynikes2 的系統則多了一層人工策展——Obsidian 筆記庫是人可以直接打開、編輯、組織的,AI 不會在背景偷偷合併或刪除記憶。這個差異在企業場景裡很重要:誰有權寫入記憶?合併規則是什麼?記憶漂移(memory drift)怎麼控制?
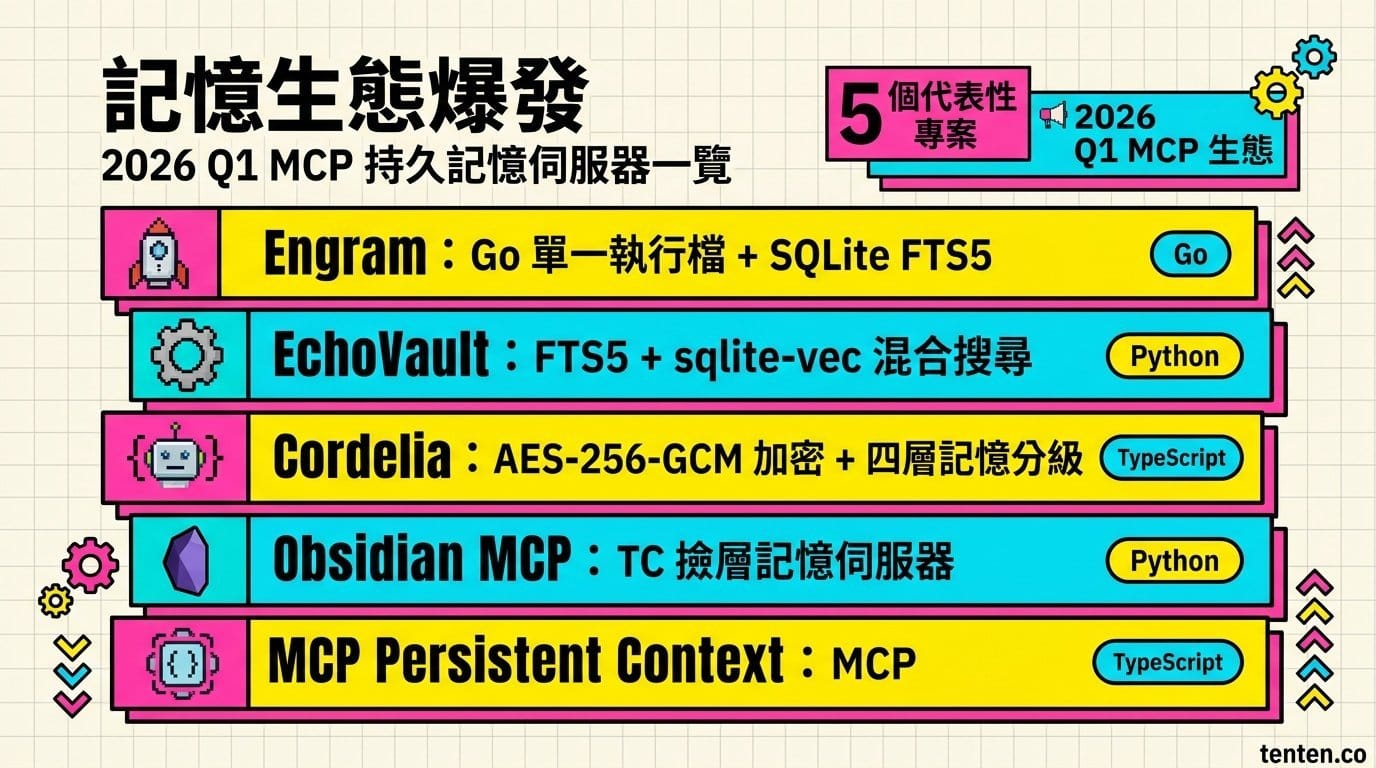
MCP 記憶伺服器的生態正在爆發
這兩個專案不是孤例。2026 年第一季,MCP 生態裡跟持久記憶有關的伺服器大量湧現:
Engram:Go 語言寫的單一執行檔,SQLite + FTS5,支援 Claude Code、Gemini CLI、Codex 等所有 MCP 相容 Agent。不需要 Node.js 或 Python。
EchoVault:Python 寫的本地記憶系統,Markdown 筆記 + SQLite,可以直接用 Obsidian 瀏覽 Agent 的記憶。FTS5 做關鍵字搜尋,sqlite-vec 做語意搜尋,兩路混合。
Cordelia Proxy:TypeScript MCP proxy,SQLite 儲存,AES-256-GCM 加密。記憶分四層:Session Buffer(即時)、Hot Context(session 開始載入)、Warm Index(按需搜尋)、Cold Archive(壓縮歸檔)。
Obsidian MCP Server(cyanheads 版):讓 AI Agent 直接讀寫 Obsidian 筆記庫,包含搜尋、tag 管理、frontmatter 處理。走 Obsidian Local REST API。
MCP Persistent Context:輕量型記憶層,4 個 tool,大約 600 schema tokens。適合不需要知識圖譜但需要跨 session 記住 context 的場景。
這些工具的共同特徵:本地部署、SQLite 為主、透過 MCP 接入、不依賴雲端向量資料庫。這跟 2024-2025 年 RAG 生態裡「Pinecone + embedding model + chunking pipeline」的主流架構形成對比。
實作指引:怎麼開始
如果你想複製 willynikes2 的架構,大致步驟如下:
基本需求: 一台 VPS(或任何 Linux 環境)、Node.js、Obsidian(本地或同步到 VPS)、至少一個 AI Agent 的 API access(Claude Code、Codex 或 Gemini CLI)。
Step 1:部署 Knowledge Base Server
Clone github.com/willynikes2/knowledge-base-server,跑 npm install,設定 .env 指向你的 Obsidian vault 路徑。用 kb start 啟動服務,kb ingest 把筆記匯入 SQLite。
Step 2:設定 MCP 連線
在 Claude Desktop 或 Claude Code 的 MCP 設定裡加入 Knowledge Base Server 的 endpoint。設定好之後,Claude 就可以用 kb_search、kb_read 等 tool 查你的筆記庫。
Step 3(選配):設定 Agent Orchestrator
如果你需要多 Agent failover,clone github.com/willynikes2/agent-orchestrator,設定 Claude、Codex、Gemini 的 API key。Daniel 會自動偵測哪個 Agent 可用、分配工作。
Step 4:建立自學習循環
在 Obsidian 裡建一個資料夾放 AI 的指令檔(像 CLAUDE.md),每次 session 結束後讓 AI 更新這份檔案。下次 session 開始時,AI 會先讀這份檔案,累積的 context 就不會丟失。
作者提到的 EXTENDING.md 是專門寫給 AI Agent 讀的文件——你可以叫你的 Agent「讀 EXTENDING.md 然後根據我的環境客製化設定」,AI 會自己處理剩下的。
限制和風險
這套系統有幾個明確的邊界:
搜尋精度的天花板。 FTS5 是關鍵字搜尋,不是語意搜尋。「authentication」不會自動匹配到「JWT token setup」。EchoVault 的做法是加 sqlite-vec 做混合搜尋,但這會增加複雜度。
記憶治理。 Google 的 Always-On Memory Agent 每 30 分鐘自動合併記憶,聽起來很方便,但 VentureBeat 的報導也指出這帶來治理問題:AI 在背景「做夢」合併記憶,如果沒有明確規則,會變成合規噩夢。willynikes2 的系統靠人工策展(Obsidian)來控制,但這也意味著你得花時間整理。
規模。 SQLite 單檔方案適合個人或小團隊。當記憶量大到需要語意搜尋大量語料庫或嚴格的 retrieval 保證時,向量資料庫還是有存在價值。Google 的 repo 文件也明確說「這不適合百萬級事實記憶」。
安全。 知識庫裡可能包含敏感的程式碼、API key、內部架構資訊。部署在 VPS 上時要確保存取控制。Cordelia Proxy 用 AES-256-GCM 加密是一個值得參考的做法。
什麼是 MCP(Model Context Protocol)?
MCP 是 Anthropic 在 2024 年底發布的開放標準,讓 AI 應用可以透過標準化介面連接外部資料來源和工具。你可以把它想成 AI 世界的 USB——不管什麼裝置(AI Agent),只要支援 MCP,就可以接上任何 MCP Server 提供的資料或功能。目前 Claude Code、Claude Desktop、Gemini CLI、Codex、VS Code Copilot 都支援 MCP。
Obsidian 筆記庫當 AI 記憶源有什麼好處?
Obsidian 的筆記是純 Markdown 檔案,不綁特定格式或平台。AI 可以透過 MCP Server 搜尋和讀取這些檔案,人也可以直接在 Obsidian 裡編輯、組織、加 tag。這種「人機共同策展」的模式讓你控制 AI 記住什麼、忘記什麼,避免記憶漂移的問題。
Google 的 Always-On Memory Agent 跟自建 MCP 記憶伺服器差在哪?
Google 的方案是「全自動」——Agent 自己吞資料、自己整理、自己回答,適合快速原型和個人使用。自建 MCP 方案(如 willynikes2 的架構)多了人工策展層和多 Agent failover,適合需要治理控制的團隊。兩者都用 SQLite、都不需要向量資料庫。
自建 MCP 記憶伺服器的月成本大概多少?
作者報告的成本大約是 USD 60/月(約 NTD 1,920,000),包含 VPS 費用加上三個 AI Agent(Claude、Codex、Gemini)的 API 使用量。實際金額會因 Agent 使用頻率和 VPS 規格而不同。
這套系統適合企業使用嗎?
目前這些專案更接近「工程範本」而非「企業產品」。VentureBeat 對 Google Always-On Memory Agent 的評估也是如此:缺乏確定性的策略邊界、保留保證、隔離規則和正式審計工作流。企業要用的話,需要在上面加權限控制、記憶保留策略和審計日誌。
引用來源
- GitHub — willynikes2/knowledge-base-server
- GitHub — willynikes2/agent-orchestrator
- GitHub — Gentleman-Programming/engram
- GitHub — cyanheads/obsidian-mcp-server
- Muhammad Raza — I Built Local Memory for Coding Agents
關於作者
Erik (EKC),Tenten.co 數位策略總監。
我們從 2025 年中期開始大量使用 Claude Code 搭配自建 MCP Server 做內容生產和客戶專案開發。實際經驗是:MCP 記憶層的價值不在「AI 變聰明了」,而在「人不用重複解釋了」。我們替客戶規劃技術架構時,累積的 context——哪些 API 有地雷、哪些模組的邊界條件容易出問題、上次跑測試的結果——這些東西如果每次都要重新講一遍,時間成本比 AI 的 token 費用高得多。
持久記憶的真正瓶頸不是技術(SQLite + MCP 很成熟),而是策展——誰負責整理、什麼該記、什麼該忘、合併規則是什麼。這跟管理公司的知識庫是同一個問題,只是速度快了十倍。
如果你的團隊正在評估 AI 編碼助手或 Agent 工作流的導入策略,歡迎跟 Tenten 團隊預約諮詢,我們可以根據你的技術堆疊和團隊規模,討論哪種記憶架構最務實。