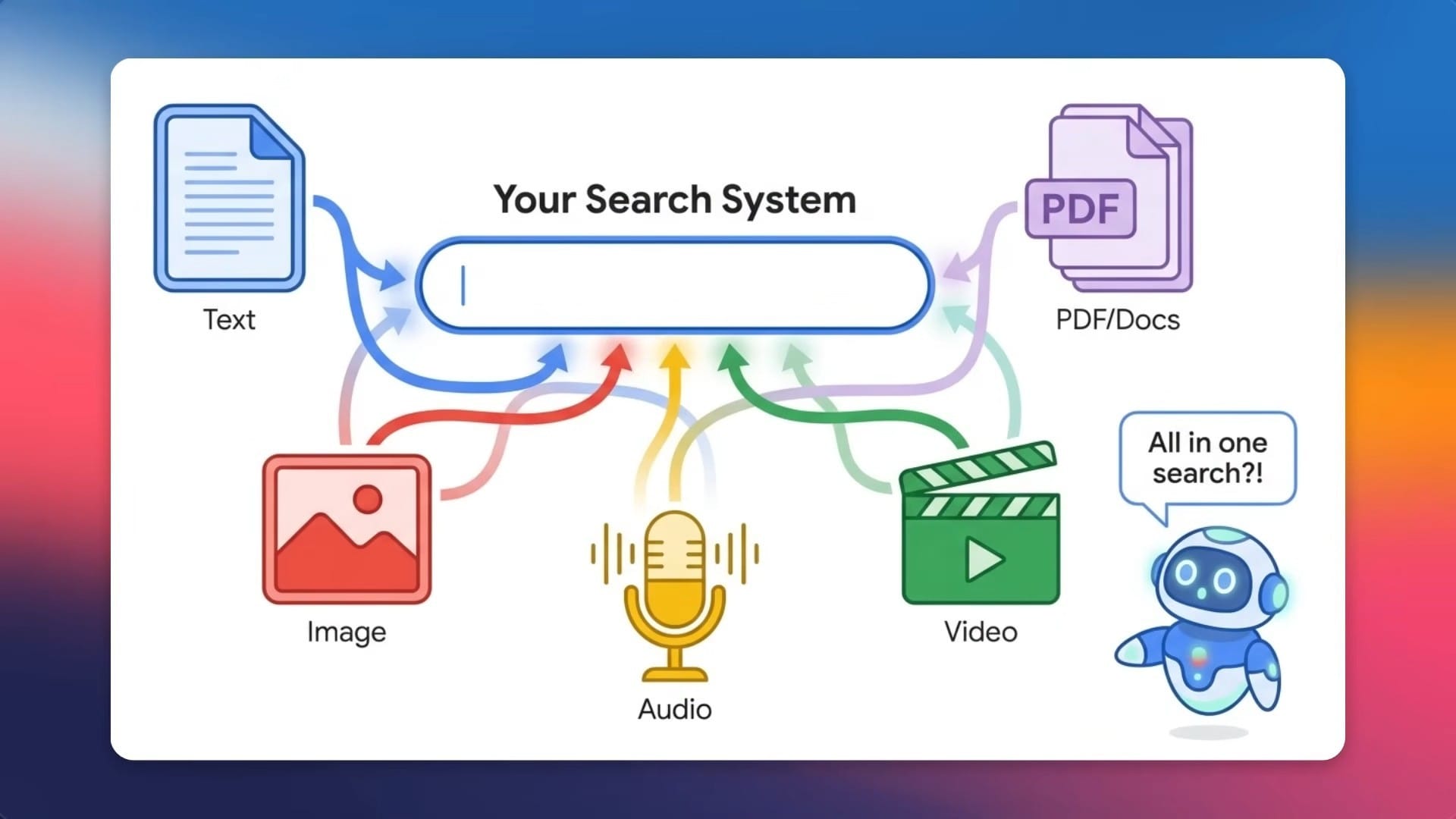
Gemini Embedding 2 在 2026 年 3 月 10 日進入公開預覽,是 Google DeepMind 第一個基於 Gemini 架構、原生支援五種媒體類型的嵌入模型。 它把文字、圖片、影片、音訊和 PDF 文件全部映射到同一個 3,072 維向量空間,開發者不再需要串接 OCR、語音轉文字、CLIP 等多個模型才能做跨模態檢索。在 MTEB 英文排行榜上,Gemini Embedding 2 以 68.32 分佔據榜首,領先第二名 5.09 分;在影片檢索基準(Vatex、MSR-VTT、Youcook2)上拿到 68.8 分,Amazon Nova 2 只有 60.3 分,Voyage Multimodal 3.5 更低到 55.2 分。
為什麼「原生多模態」跟「拼接多模態」是兩件事
過去做多模態嵌入的標準做法是 CLIP 家族的雙編碼器架構:一個視覺編碼器處理圖片,一個文字編碼器處理文字,兩邊各自產出向量後再用對比學習(contrastive learning)對齊。這個方法的根本限制在於,兩個編碼器只在最終輸出層對齊,中間層的跨模態互動幾乎為零。音訊和影片?CLIP 不處理,你得額外接 Whisper 做語音轉文字再嵌入。
Gemini Embedding 2 的做法不同:它直接用 Gemini 基礎模型的共享 Transformer 架構,五種模態在網路中間層就開始交互。根據 Google Cloud 工程師 Karl Weinmeister 在 Medium 的技術解析,這種「深度跨模態連結」是雙編碼器架構做不到的,因為語義融合發生在模型的隱藏層而不是輸出層。
實際差異是什麼?你可以在單一 API 請求裡同時送一張老爺車照片加上「這台車的引擎型號是什麼?」的文字,模型把它們當成一個完整的語義概念處理,不是先分開理解再拼起來。
技術規格與輸入限制
| 模態 | 上限 | 格式 |
|---|---|---|
| 文字 | 8,192 tokens(前代 gemini-embedding-001 的 4 倍) | — |
| 圖片 | 每次請求最多 6 張 | PNG、JPEG |
| 影片 | 最長 120–128 秒 | MP4、MOV |
| 音訊 | 最長 80 秒 | MP3、WAV |
| 最多 6 頁 | — |
向量維度採用 Matryoshka Representation Learning(MRL),預設輸出 3,072 維,可以截斷到 1,536 或 768 維。Google 官方建議生產環境用 768 維,品質接近 3,072 維但儲存成本只要四分之一。簡單算一下:100 萬個 3,072 維向量(float32)大約佔 12 GB,降到 768 維後只要 3 GB 左右。
3,072 維的輸出是預先正規化的,但截斷到較小維度後需要手動正規化。
基準測試:數字說話
Google 自己公布的基準比較(對手是 Amazon Nova 2 Multimodal Embeddings 和 Voyage Multimodal 3.5):
| 基準項目 | Gemini Embedding 2 | Amazon Nova 2 | Voyage Multimodal 3.5 |
|---|---|---|---|
| MTEB 英文(文字) | 68.32 | — | — |
| MTEB 多語言 | 69.9 | — | — |
| MTEB 程式碼 | 74.66–84.0 | — | — |
| 文字-圖片檢索 | 93.4 | 84.0 | — |
| 影片檢索(Vatex 等) | 68.8 | 60.3 | 55.2 |
需要注意:這些是 Google 自己的數字,獨立基準測試結果可能有差異。但差距不算小——影片檢索領先 Amazon 超過 8 分、領先 Voyage 超過 13 分。在 MTEB 英文排行榜上,Gemini Embedding 001 本來就以 68.32 分居首,而 Gemini Embedding 2 在維持文字效能的同時擴展到多模態,沒有出現「加了模態就犧牲文字品質」的典型取捨。
對純文字任務而言,OpenAI 的 text-embedding-3-large 和 Cohere Embed v4 在某些特定領域仍然有競爭力。Gemini Embedding 2 真正拉開差距的是跨模態檢索——目前沒有其他商業 API 能原生處理影片和音訊嵌入。
定價與競品比較
| 模型 | 價格(每百萬 tokens) | 模態覆蓋 | MTEB 英文 |
|---|---|---|---|
| Gemini Embedding 2 | USD 0.20(約 NTD 6) / 批次 API USD 0.10 | 文字+圖片+影片+音訊+PDF | 68.32 |
| OpenAI text-embedding-3-small | USD 0.02(約 NTD 1) | 僅文字 | 62.26 |
| OpenAI text-embedding-3-large | USD 0.13(約 NTD 4) | 僅文字 | 64.6 |
| Cohere Embed v4 | USD 0.12(約 NTD 4) | 文字+圖片 | 65.2 |
| Voyage 3.5 | USD 0.06(約 NTD 2) | 文字 | — |
| Mistral Embed | USD 0.01(約 NTD 0.3) | 文字 | — |
單看文字嵌入的價格,OpenAI 的小模型便宜 10 倍。但這是拿蘋果比橘子——如果你需要跨模態檢索,替代方案是自己串 CLIP(圖片)+ Whisper(音訊)+ 文字嵌入模型,然後想辦法對齊三個不同的向量空間。把工程複雜度和維運成本算進去,Gemini Embedding 2 的 USD 0.20 其實不貴。
批次 API 半價(USD 0.10/M tokens)適合不需要即時回應的批量索引任務。粗算一下:100 萬份文件,每份平均 500 tokens,總計 5 億 tokens。用批次 API 的話大約 USD 50(約 NTD 1,600)。
早期採用者的實際成效
Gemini Embedding 2 的早期存取夥伴已經回報了生產環境的改善數據:
創作者平台 Sparkonomy 用 Gemini Embedding 2 取代原本串接的三模型管線後,延遲降低了 70%。法律科技公司 Everlaw 在訴訟發現(litigation discovery)流程中,跨異質法律文件的搜尋召回率提升了 20%。AI 郵件助理 Poke 的記憶檢索和郵件上下文增強速度比先前方案快了 90.4%。心理健康 AI 平台 Mindlid 在對話歷史理解任務上達到 87% 準確率,對比 Voyage 的 84% 和 OpenAI 的 73%。開發者工具 Roo Code 用它做程式碼庫語義搜尋,即使查詢措辭不精確也能回傳高度相關的結果。
這些案例的共同模式是:管線簡化帶來的延遲降低,以及統一向量空間帶來的跨模態搜尋品質提升。
三個改變工作流程的實際場景
場景一:工業監控影片的語義搜尋
傳統做法是先用視覺模型辨識物件(紅衣服、快遞、拿走動作),轉成文字索引再搜文字。Gemini Embedding 2 直接把 120 秒影片段落嵌入為向量。搜尋「有人拿走包裹的畫面」時,模型在向量空間裡匹配影片的動態特徵,不需要中間的文字轉換。影片超過 128 秒的話,切成段落分別嵌入,建立一條可搜尋的「語義時間軸」。
場景二:圖文混合研報的 RAG 管線
PDF 裡的折線圖和餅圖一直是 RAG 的痛點。以前的做法是 OCR 抓文字、另一個模型分析圖表,然後用工程膠水把結果黏起來。Gemini Embedding 2 直接把 PDF 頁面(圖文交錯)一次性嵌入。問「去年第三季研發支出佔營收比例是多少?」時,模型同時理解文字描述和餅圖裡的視覺比例,直接定位答案。資訊在多模型之間流轉的「翻譯損耗」被消除了。
場景三:跨模態電商搜尋
用戶上傳一張跑車照片,你想推薦這台車的引擎聲音片段。因為音訊和圖片都在同一個向量空間,圖片的向量可以直接匹配頻率特徵相似的音訊向量。反過來也行——用一段引擎聲搜尋對應的車款圖片。這打破了以往模態隔離的限制,做到真正的「全感官」索引。
遷移注意事項:向量空間不相容
從 gemini-embedding-001 升級到 gemini-embedding-2-preview,最重要的一件事:兩個模型的向量空間完全不相容。你不能把舊模型產生的向量跟新模型的向量放在同一個索引裡比較,距離度量會完全失準。
升級意味著重新嵌入整個資料集。對已有生產級搜尋系統的團隊,建議的做法是:
- 平行建立影子索引(shadow index)——生產系統繼續跑 embedding-001,背景跑一個 re-embedding 任務把語料庫用新模型重新嵌入
- 重新校準相似度閾值——每個嵌入模型在潛在空間的向量分佈不同,你的 RAG 管線依賴的 cosine similarity 過濾閾值會漂移(例如從 0.6 變成 0.7),需要對著評估資料做 A/B 測試
- 確認新索引品質後再切換
EmbeddingGemma:開源端側嵌入的互補方案
Google 同時推出了 EmbeddingGemma,一個 308M 參數的開源文字嵌入模型,基於 Gemma 3 架構。它的定位跟 Gemini Embedding 2 完全不同:小到可以在手機上跑,量化後記憶體佔用不到 200 MB,在 EdgeTPU 上推論只要 22 毫秒以下。
EmbeddingGemma 是 MTEB 排行榜上 500M 參數以下最強的開源多語言文字嵌入模型,支援 100+ 語言,MRL 維度從 768 到 128 可調。它的上下文窗口只有 2,048 tokens(Gemini Embedding 2 是 8,192),不支援多模態——定位就是端側離線場景,像是本地檔案搜尋、行動裝置 RAG 管線、隱私敏感的對話系統。
策略邏輯很清楚:EmbeddingGemma 降低進入 Google 嵌入生態的門檻,等開發者需要多模態或更大規模時,自然升級到 Gemini Embedding 2 的雲端 API。
嵌入模型的生態位:看不見但決定一切的基礎層
嵌入模型從來不是社群媒體上的熱門話題,但它決定了你每天用的 AI 應用能不能正常運作。語義搜尋之所以像讀心術、RAG 之所以不會頻繁出錯,靠的就是嵌入品質。
當越來越多開發者在 RAG 管線上面建產品——而這是目前企業 AI 的主流形態——嵌入模型就成了這些產品依賴的地基。在 Gemini Embedding 2 上建搜尋基礎設施的開發者,實際上就是進入了 Google 的 AI 生態系。搭配 LangChain、LlamaIndex、Haystack、Weaviate、QDrant、ChromaDB 的原生整合,遷移門檻被降到很低。
對已經有文字嵌入基礎設施的團隊,我的建議是:即使第一階段只索引文字,選 Gemini Embedding 2 也能在未來不改架構的情況下直接加入圖片、音訊、影片和 PDF。這種前向相容性,省下的是一次完整的架構遷移。
Gemini Embedding 2 跟 OpenAI 的嵌入模型有什麼差別?
最核心的差異在模態覆蓋。OpenAI 目前的嵌入 API(text-embedding-3 系列)只支援文字。如果你需要圖片檢索,要另外用 CLIP 家族模型;音訊和影片則需要先轉文字再嵌入。Gemini Embedding 2 把五種模態放在同一個向量空間,一個 API 呼叫搞定。純文字效能上,Gemini 在 MTEB 英文排行榜領先,但 OpenAI 的價格是它的十分之一(USD 0.02 vs USD 0.20 每百萬 tokens)。選哪個取決於你的管線是否需要跨模態。
Gemini Embedding 2 適合什麼樣的企業使用?
需要跨模態搜尋(用文字搜影片、用圖片搜文件)、現有管線串接了三個以上專用模型、需要 100+ 語言支援、或者要把會議錄音、產品圖和文件放在同一個搜尋索引裡的企業。如果你的管線只處理文字而且短期內沒有多模態計畫,OpenAI 的 text-embedding-3-small(USD 0.02/M)成本效益更高。
從舊版 embedding-001 升級要注意什麼?
兩個模型的向量空間完全不相容,不能混用。升級代表你要重新嵌入整個語料庫。建議先建影子索引平行測試,重新校準 cosine similarity 閾值,確認品質後再切換。資料量大的話,用批次 API(USD 0.10/M tokens,半價)能省不少。
768 維跟 3,072 維的品質差多少?
根據 Google 文件和 MTEB 測試,768 維的品質接近 3,072 維的峰值,但儲存只要四分之一。Google 官方建議生產環境用 768 維作為品質和成本的平衡點。100 萬向量在 3,072 維約佔 12 GB,768 維只要約 3 GB。
Gemini Embedding 2 可以處理超長影片嗎?
單次請求上限是 120–128 秒影片。超過的話,開發者需要自行把影片切成段落分別嵌入,建立一條可搜尋的語義時間軸。音訊上限是 80 秒,PDF 上限是 6 頁。超過這些限制的內容都需要先做分段處理。
引用來源
- Google Blog — Gemini Embedding 2: Our first natively multimodal embedding model
- Google Cloud Documentation — Gemini Embedding 2 on Vertex AI
- Gemini API Embeddings Documentation
關於作者
Erik|數位策略總監 @ Tenten.co
我們在替企業建置 AI 工作流時,一個反覆出現的問題是:團隊往往在建系統時只考慮文字檢索,等到半年後要加圖片或影片搜尋時才發現向量空間不相容、需要整個重建。Gemini Embedding 2 的價值,對我來說不在於它今天的基準分數領先多少,而在於它提供了一條「先文字、後多模態」的無痛擴展路徑。對正在規劃 RAG 基礎設施的團隊,這是選型時值得優先考慮的因素。
我們最近協助金融科技和法律科技客戶做嵌入模型的評估與遷移,從雙編碼器方案切換到統一向量空間後,管線複雜度和維運成本都明顯下降。如果你正在評估企業級 AI 搜尋或 RAG 架構,歡迎跟 Tenten 團隊預約諮詢。










