網路將在 3 年內徹底死亡?Profound CEO 揭開「死網理論」與品牌求生指南
「死亡網路」這個說法,2026 年 4 月再度引發討論。提出警告的不是末日論者,而是手握全球 12% 財星 500 大企業行銷數據的 Profound CEO James Cadwallader。他在紅杉資本《Training Data》Podcast 第 83 集公開表示,三年內出現「dead internet outcome」是有可能的——但他自己也補了一句:「不一定會發生。」
這篇文章拆解他這條推論的完整邏輯:消費者為什麼悄悄被 agent 取代、廣告經濟為什麼會斷掉、內容創作者的誘因會怎麼歸零,以及在這場變遷裡,品牌跟創作者還能怎麼活。
Profound 是誰,為什麼這個警告值得認真看
Profound 2024 年 8 月以 350 萬美元種子輪起步,2026 年 2 月 24 日宣布完成 9,600 萬美元 C 輪融資,估值 10 億美元,由 Lightspeed Venture Partners 領投,Sequoia Capital、Kleiner Perkins、Saga VC、South Park Commons、Evantic 跟投。從種子輪到獨角獸,花了 18 個月,總募資超過 1.55 億美元。
這家紐約公司做的事很明確:幫品牌看清楚自己在 ChatGPT、Gemini、Claude、Perplexity 這些 AI 模型的回答裡長什麼樣子。客戶名單包括 Target、Walmart、Figma、DocuSign、Chime、Plaid、Wayfair、Brex、LG,總計超過 700 家企業。Cadwallader 在 Sonya Huang 主持的訪談裡親口說:「現在大概 12% 的財星 500 大公司在用 Profound。」
他每天盯著的數據,是這個地球上規模最大的一批品牌在 AI 模型回答中的能見度報告。與其把他的話當預測,不如當趨勢線延伸的觀察紀錄。

第一步:消費者已經被 agent 取代了,只是大家還沒意識到
Cadwallader 用一句話概括:「不是網路的大門變了,是走進這扇門的人變了。」
過去的 SEO 邏輯是:人類對著 Google 搜尋,看到藍色連結,點進網站,網站賺廣告費或轉換率。這個機制有個前提:點擊行為發生在人類身上。
Cadwallader 拿自己的經驗打破這個前提。三、四個月前,他想幫紐約公寓換蓮蓬頭,問了 ChatGPT。AI 回答之前,掃了 65 個不同網頁。他反問:「真的有人會為了買蓮蓬頭看 65 個網頁嗎?」
主持人 Sonya Huang 半開玩笑回了一句:「我大概會,這是很重要的採購。」這回應恰好凸顯 Cadwallader 的論點。人類受限於認知能量、時間、耐心,95% 的搜尋價值集中在前四到五條藍色連結。Agent 沒這個限制,它可以無痛消化整條長尾。
這不是漸進式變化。當 agent 用 65 個頁面回答一個人類用 4 個頁面就放棄的問題,內容產業面對的不是流量重新分配,是流量接收對象整個換了一輪。
第二步:廣告經濟跟著斷裂
瀏覽行為從人類轉到 agent,廣告經濟的循環就破了一個洞。
Cadwallader 的推論順序如下。
絕大部分內容網站靠廣告收入撐著。廣告計價的核心邏輯是「人類眼球曝光」:CPM、CTR、轉換率,每個指標背後都假設廣告會被一個有信用卡、有購買意圖的人看到。當人類不再點進網頁、改由 agent 進去抓資訊,廣告的曝光對象就從消費者變成程式碼。Agent 不會被廣告打動,也不會點擊。
廣告主沒理由再付錢給這些網站。網站收入崩盤之後,「為什麼還要寫文章」就會浮上來。發文章是為了吸引人類;如果讀者改用 ChatGPT 直接拿答案,發文者拿不到流量、拿不到曝光、拿不到廣告分潤,品牌名聲也累積不起來。Cadwallader 在訪談中大意是說:「人類用 AI 把好東西吸走,重新混合,文章底下也許留個小小的引用,但沒人會點,誰在乎?」
經濟模型整個壞掉。內容生產的誘因歸零。
不過 Cadwallader 自己給這個劇本打了保留:「我覺得有可能,但不一定會發生。」這個措辭重要。他不是斷言三年內網路會死,而是說這是一個值得認真討論的可能性。原始中文翻譯版本省略了這層保留,語氣比 Cadwallader 本人說的更斷然。

第三步:「AI 寫的就是垃圾」這個共識,已經站不住了
過去兩年的安慰劑是:就算 agent 接管瀏覽,人類至少還是內容生產者,因為「AI 寫的東西品質不行」。
2026 年 3 月,《紐約時報》一個盲測把這層安慰拆掉了。
科技記者 Kevin Roose 跟 Stuart A. Thompson 設計的測驗在 3 月 9 日上線,5 組文字配對,題材橫跨文學小說、奇幻、科普、歷史小說、詩。86,000 多名讀者在不知道作者身分的情況下,從每組挑出他們覺得寫得比較好的那段。
結果:54% 的讀者選了 AI 寫的版本。其中一組 AI 對人類的偏好比是 67% 比 33%。Cadwallader 在訪談中說成 53%,差距不大,但要引用就用《紐約時報》原始數據比較準。
54% 跟 50% 之間的差距,真正讓人不安的地方在於「AI 等於 slop(垃圾)」這個論述基礎裂了。AI 變強只是表象。Cadwallader 直接說:「slop 是個誤導。AI 完全有能力寫出高品質內容、高品質行銷。」
這拉開一個更難迴避的問題:如果連《紐約時報》的讀者都分不出來,「人類創作」這個職業類別的差異化護城河,到底還剩什麼?
三條路徑的交叉口:dead internet outcome 為什麼是個系統性風險
把上面三步串起來:
| 觀察點 | 過去(人類使用網路) | 現在(agent 使用網路) |
|---|---|---|
| 流量發送對象 | 人類使用者 | AI agent |
| 內容消費深度 | 前 4–5 條藍色連結 | 65+ 頁面長尾 |
| 廣告曝光對象 | 人類眼球 | 沒人看到的程式抓取 |
| 內容生產誘因 | 流量、廣告分潤、名聲 | 引用標記,無流量回饋 |
| 內容品質判定 | 人類創作 = 真實感 | 54% 讀者選 AI(NYT 盲測,2026 年 3 月) |
四條線同時往同一個方向走,dead internet 就從聳動標題升級成系統性風險。四個獨立趨勢在交匯。
Cadwallader 預測的第二序效應:每一家 AI 實驗室最終會跟一個社群網路垂直整合。Grok 跟 X 已經做了,Grok 從 X 的即時內容撈第一手資訊。OpenAI 跟 Reddit 簽了內容授權協議。他自己丟了個推測:「我一直有個理論,OpenAI 可能會收購 Reddit。」
邏輯很直接:當公開網路的內容生產誘因歸零,AI 模型會缺乏即時的人類資料來理解現實。社群網路是這筆資料最後的來源,而且因為 Meta、X、Reddit 積極反 bot,這些平台會變成「人類資料保護區」。Cadwallader 用了一個帶生物學意涵的詞「biozone」,可以理解成人類資料的保育區。
「人是現實跟網路之間肉做的 API」是什麼意思
Cadwallader 在訪談中拋出一個比喻:「humans are this kind of fleshy API between reality and the internet」,翻成中文就是「人是現實跟網路之間肉做的 API」。
拆開來看:API 的角色是把一個系統的資訊翻譯成另一個系統能懂的格式。在 AI agent 之前,人類負責把現實世界的觀察、感受、對話、商業洞察編碼成數位內容,餵給網路。網路再餵給其他人,或餵給搜尋引擎。
當 agent 接管「讀」這個動作,下一步就是接管「寫」。如果五千萬個機器人開始替代人類去採集現實——買菜、開會、看比賽、評測商品——那「肉做的 API」就被繞過去了。AI 不需要透過人類來理解現實,它可以直接派出各種形式的 agent 到現實裡採集第一手資料。
Cadwallader 認為這是 AI 公司會推動的方向,因為這解決了「人類資料來源即將枯竭」的問題。他不認為這是科幻。
對品牌跟創作者的具體含義:什麼留得住,什麼留不住
Cadwallader 在訪談中對行銷人的建議拆成兩層。
能見度層:必須清楚自己在 ChatGPT、Gemini、Claude、Perplexity 各模型裡長什麼樣子,被引用的來源是哪些,被推薦的競品是誰。這跟過去的 SEO 排名追蹤本質上是同一件事,介面換了而已。Profound 自己的產品就在做這件事。
內容層:這層比較反直覺。過去的 SEO 邏輯是「寫得好、結構清楚、關鍵字布局漂亮」就能排名上升。在 agent 時代,這套邏輯天花板很低——agent 把整個網際網路掃過了,你寫的東西它早就看過類似版本。
Cadwallader 給的方法叫「first-principle marketing」,意思是告訴超級智能它不知道的事。具體拆解:
| 內容類型 | agent 時代的價值 | 原因 |
|---|---|---|
| 整理型內容(懶人包、清單) | 低 | agent 自己會整理 |
| 教學型內容(how-to) | 中低 | agent 已經學會了 |
| 翻譯/改寫型內容 | 趨近於零 | agent 直接生成 |
| 第一手實測(你自己跑出來的數據) | 高 | agent 沒有 |
| 第一手訪談(你自己訪到的人) | 高 | agent 拿不到 |
| 反共識洞察(基於你獨有的觀察) | 高 | agent 缺這種視角 |
這個重新分類解釋了為什麼 ChatGPT、Gemini、Claude 在引用內容時,偏好不同來源:
- Gemini 大量引用 YouTube(Google 自家平台)
- ChatGPT 偏好 Reddit(消費議題)跟 LinkedIn(B2B)
- Claude 過去主要靠預訓練資料,4.5、4.6 版本之後分類器更敏銳,網頁查詢比例上升
對臺灣的內容創作者跟品牌來說,這代表幾個具體動作。
第一,停止生產可被 AI 替代的內容類型。整理型、翻譯型、改寫型內容的市場價格會繼續下滑,供給端會被 AI 自動化。
第二,把資源投到第一手資料。自己跑實測產出原始數據、訪問業內人士拿獨家觀點、累積自有的客戶案例庫、寫只有經歷過特定情境才寫得出來的觀察。
第三,重新理解社群媒體的策略意義。如果 Cadwallader 預測的「AI 實驗室垂直整合社群網路」成真,經營 LinkedIn、Threads、Instagram、X 的價值不再只是引流,而是在 AI 的訓練資料源頭裡留下你的聲音。這也是 GEO 與 AEO 生存法則的核心邏輯。
第四,廣告預算要重新分配。展示型廣告、SEO 廣告,該逐步轉到 AI 平台廣告。OpenAI 已經在 ChatGPT 上投放廣告,Cadwallader 預測下一代的廣告單位會是「給 AI 的 system prompt」——廣告主提供品牌資訊跟調性指引,AI 在對話的合適時機自然帶入。
在 ChatGPT、Claude、Gemini 上被引用的具體做法
Cadwallader 訪談中提了一個有趣觀察:agent 為了省力,會偏好已經做完比較工作的內容,也就是「比較型清單文(comparative listicle)」。比方說,你寫一篇「矽谷十大創投」並把自己(如果你是創投)放在第一名,弱的競爭對手列第二到第五,強的對手不列入。這種自利型內容對 agent 引用率出乎意料地有效。
他自己補了免責:「我不建議大家這樣做,但我們確實看到很有效。隨著模型進化,這招會被懲罰。」
這個觀察解釋了為什麼 GEO/AEO 領域有大量「Top 10 X 工具比較」類型的內容冒出來。它們的閱讀對象是 agent,不是人類讀者。
更穩健的長期做法是 Cadwallader 講的「legibility」——讓品牌跟產品對 agent 可讀。具體實作包括:
- 在自家網站放結構化的產品資料(FAQ schema、Product schema、Review schema)
- 在 Wikipedia、Reddit、LinkedIn、YouTube 等 AI 偏好引用的來源累積一致的品牌敘事
- 對 B2B 軟體來說,文件的可讀性、API 的互通性、Claude Code 等工具能不能順利調用,直接影響開發者選型
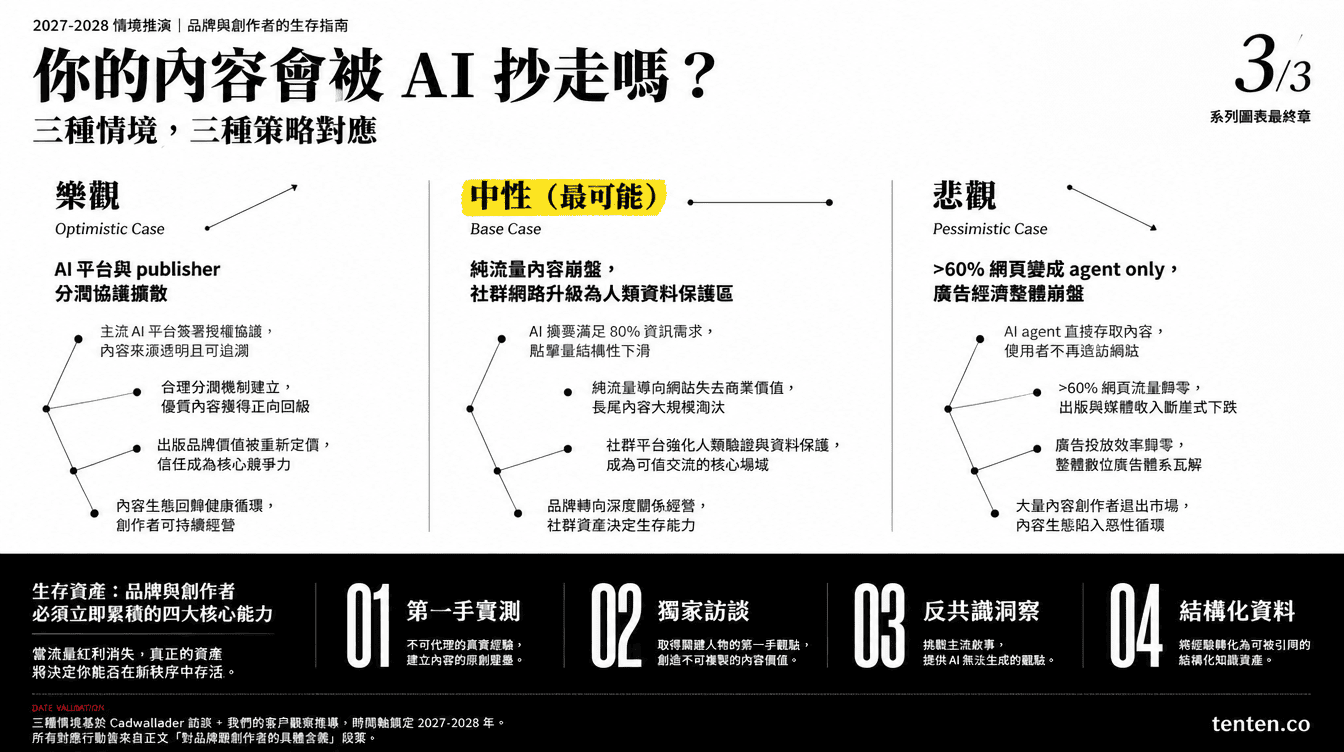
三年內會死掉嗎?比較合理的時間軸
把 Cadwallader 的「三年內可能但不一定」放回他的客戶數據脈絡裡,可以拆成三個情境。
樂觀情境(內容平台撐得住):AI 平台主動跟內容生產者分潤(類似 Reddit 跟 OpenAI 的協議擴散到更多平台),廣告模式從展示型轉成 agent 內嵌型,內容創作者轉型成「第一手洞察供應商」。網路結構會調整但不會死。
中性情境(部分內容平台斷裂):純流量導向的內容農場、SEO blog、聯盟行銷站收入崩盤。社群網路(Reddit、LinkedIn、X、Instagram)變成人類資料保護區,價值上升。傳統出版兩極分化——擁有第一手資料的(《紐約時報》、《華爾街日報》、《彭博》)能跟 AI 公司簽授權,沒有的萎縮。
悲觀情境(接近 dead internet outcome):超過 60% 的網頁變成 agent only 流量,廣告經濟整體崩盤,多數內容創作者退出公開網路、退守付費電子報跟社群。AI agent 為了補資料缺口,開始派機器人(含人形機器人)直接採集現實。
Cadwallader 自己對悲觀情境的機率描述是「possible, maybe not likely」。把他的客戶資料當輸入訊號,比較合理的判斷是中性情境最有可能在 2027 到 2028 年之間部分實現。悲觀情境需要 AI 模型成本繼續快速下降,同時人形機器人量產到位,兩件事同步發生。
筆者觀察
協助臺灣品牌把行銷預算從傳統 SEO 拆到 AEO/GEO 跟 AI 平台廣告的過程裡,我注意到一個有趣的反差:客戶最容易被 dead internet 這種敘事嚇到,可是他們真正要做的決策藏在後面一層——在還有時間的窗口期,把可被 AI 取代的內容生產線關掉、把不可被取代的資產擴大。第一手實測、獨家訪談、客戶案例,這些東西的邊際報酬正在拉高。
Cadwallader 的數據看起來嚇人,但他自己把可能性壓在「possible, maybe not likely」是有道理的。內容生產的經濟模型不會一夜崩塌,會在三到五年內逐步重構。對 B2B 品牌來說,現在最關鍵的決策已經跳過「要不要進 AEO」這個入門題,進入「我們公司有哪些資產是 AI 抄不走的」。員工內部知識、客戶實際使用數據、產業內幕對話、獨家供應鏈關係——這些東西要怎麼系統化地轉成可被 AI 引用的內容,才是真正要回答的問題。
最近我們在協助金融、製造、SaaS 客戶做的就是這類盤點:哪些內容該停產、哪些該加碼、哪些該轉到社群上累積品牌資料指紋。如果你也在思考這些問題,歡迎跟 Tenten 團隊預約諮詢,我們可以一起拆解你的內容資產組合該怎麼往 agent-led 時代調整。
常見問題 FAQ
James Cadwallader 說「dead internet」三年內會發生,這個說法可信嗎?
Cadwallader 在紅杉《Training Data》Podcast 第 83 集的原話是「I think it's possible, maybe not likely」,可能但不一定會發生。原始中文翻譯版本省略了「不一定」這層保留,語氣比本人的講法更強。他的論點建立在三個趨勢上:agent 取代人類瀏覽、廣告經濟斷裂、《紐約時報》54% 讀者偏好 AI 寫作的盲測。三個趨勢都是真實的,但加起來會走到 dead internet 還是中性重構,目前仍是開放問題。
Profound 是哪一家公司?為什麼他們的觀點有可信度?
Profound 是 2024 年 8 月在紐約成立的 AI 行銷分析平台,由 James Cadwallader 跟 Dylan Babbs 創辦。2026 年 2 月完成 9,600 萬美元 C 輪融資,估值 10 億美元。客戶包含 Target、Walmart、Figma、DocuSign 等超過 700 家企業,涵蓋約 12% 的財星 500 大公司。核心產品幫品牌追蹤自己在 ChatGPT、Gemini、Claude、Perplexity 等模型回答中的能見度跟引用來源。
對中小型品牌來說,現在該停掉 SEO 嗎?
不該。SEO 跟 AEO/GEO 在內容資產層大量重疊,停掉 SEO 等於把已有的資產丟掉。比較合理的做法是:把資源從「衝排名」的內容(純流量導向、聯盟連結型)轉到「可被 AI 引用」的內容(結構化資料、原創觀點、第一手實測)。同一篇文章可以同時對 Google SEO 跟 ChatGPT 引用做優化。
創作者怎麼判斷自己的內容會不會被 AI 取代?
問三件事。第一,這個內容靠純整理就能寫出來嗎?如果是,AI 做得到。第二,這個內容有沒有只有你能拿到的資料源?員工關係、獨家訪談、自家產品實測數據都算。第三,內容的價值來自資訊本身,還是來自你獨有的詮釋?前兩題答「沒有」、第三題答「資訊本身」的內容,被 AI 取代的速度最快。
「AI 實驗室垂直整合社群網路」是什麼意思?
Cadwallader 預測每家 AI 實驗室最終會跟某個社群網路綁在一起,因為公開網路的人類資料來源會枯竭,社群網路是最後的即時人類資料來源。已經發生的案例:xAI 的 Grok 跟 X、OpenAI 跟 Reddit 簽資料授權協議。他個人推測 OpenAI 可能直接收購 Reddit。對品牌來說,這代表社群媒體經營從引流工具升級成「在 AI 訓練資料源頭裡刻下品牌指紋」。
延伸閱讀與參考資料
- Sequoia Capital — From SEO to Agent-Led Growth: Profound's James Cadwallader(Episode 83 完整逐字稿)
- Profound 官方公告 — Profound raises $96M Series C at $1B valuation
- The New York Times — Who's a Better Writer: AI or Humans?(Kevin Roose & Stuart A. Thompson, March 9, 2026)
- a16z — The GEO Report: Search is changing
- 同主題延伸:a16z 的 GEO 報告:SEO 已死,生成式引擎優化重新定義搜尋、你的品牌正在被 AI 淘汰?2026 年必懂的 GEO 與 AEO 生存法則、AI 搜尋體驗崛起:傳統 SEO 已死?、Google Analytics 追蹤 AI 流量的終極指南、AI 升級!紅杉峰會 150 創始人