深入解析 OpenAI 最新推出的 GPT-4.1 模型,不僅是對 AI 發展趨勢的觀察,也是對開發者與終端用戶需求的回應。GPT-4.1 這個關鍵字,近期在 Reddit、Hacker News 及開發者社群中討論度極高。本文將從技術亮點、實際應用、與 Reddit 社群的第一手回饋三大面向,帶你全面掌握 GPT-4.1 的現況與未來潛力。
GPT-4.1 技術亮點與升級
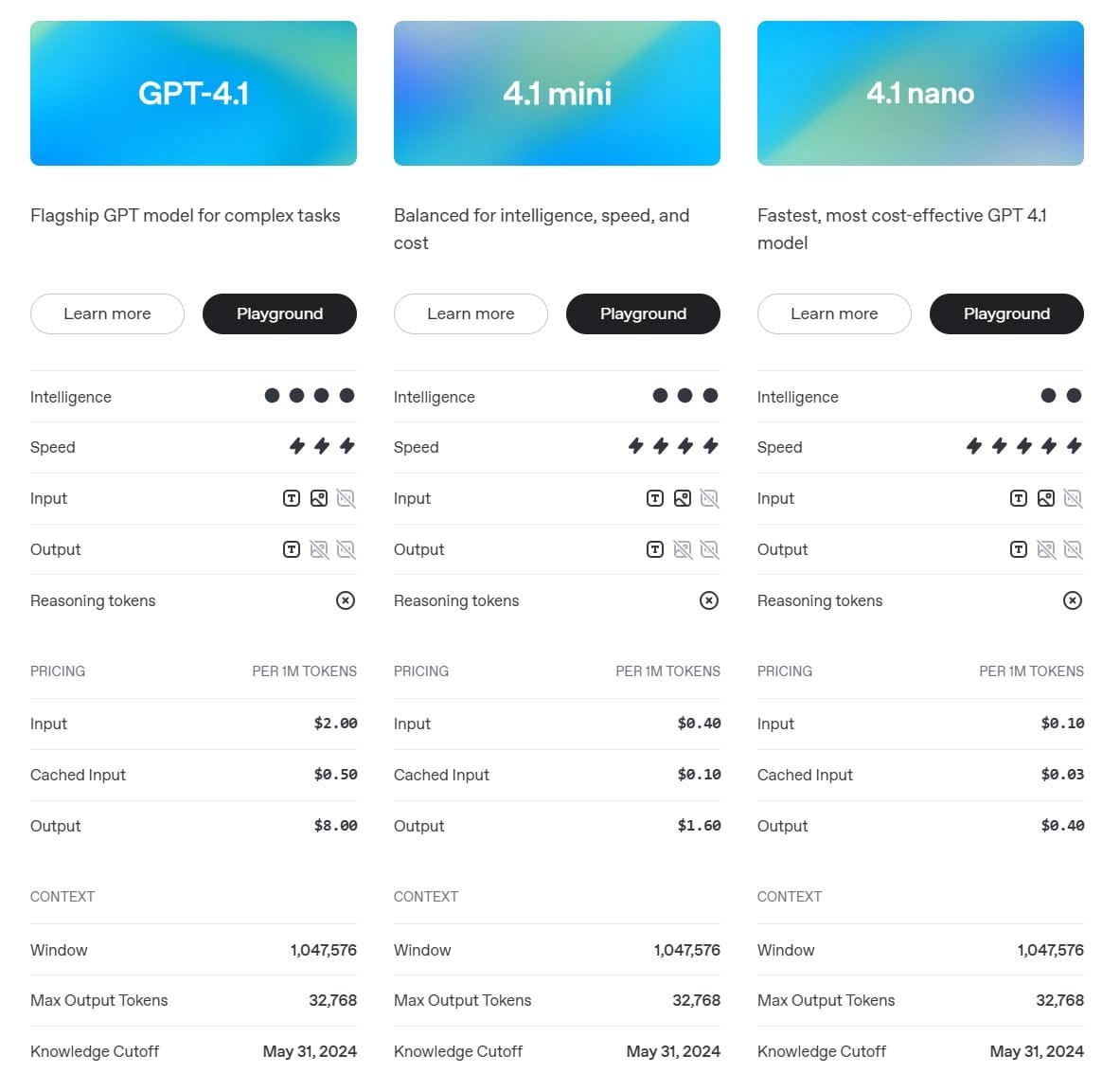
GPT-4.1 是 OpenAI 於 2025 年 4 月正式發布的語言模型家族,包含標準版、Mini 版與 Nano 版,均支援高達 100 萬 tokens 的超長上下文視窗,遠超過前代 GPT-4o 的 128K 限制。這意味著開發者與企業用戶可以一次處理完整的代碼庫、法律文件、或多份長篇資料,無需再進行繁瑣的分段與彙總。
在核心能力上,GPT-4.1 對比 GPT-4o 與 GPT-4.5,於多項基準測試表現出色:
- 軟體工程(SWE-bench):GPT-4.1 準確率達 54.6%,比 GPT-4o 提升 21 點。
- 指令遵循(MultiChallenge):提升 10.5 點,展現更可靠的多步驟指令執行能力。
- 長上下文推理(Graphwalks):多跳推理能力提升至 61.7%,顯著優於 GPT-4o 的 42%。
- 結構化輸出與格式遵循:在 XML、YAML、Markdown 等結構化任務中更精準,減少後續人工修正。
此外,GPT-4.1 Mini 與 Nano 版本針對不同場景進行優化,Mini 版兼具速度與智能,Nano 版則主打極速與低成本,適合分類、補全等輕量應用。

安全性與用戶體驗
根據 OpenAI 官方說明,GPT-4.1 在安全性評估上與 GPT-4o 持平,並未引入新的風險點。這意味著即便模型能力提升,對於敏感資訊的處理與回應依然受到嚴格控管。
Johannes Heidecke(OpenAI 安全系統主管)在 X 平台強調:「GPT-4.1 沒有新增互動方式,也未超越 o3 在智能上的表現,但在安全性與專業領域能力上有明顯進步」。
Reddit 社群真實回饋
Reddit 上的討論展現出 GPT-4.1 的多元評價,既有高度肯定,也有理性批評:
- 正面回饋
多數用戶認為 GPT-4.1 在解釋概念、上下文理解、與代碼生成方面明顯優於 4.0,且語言表達更精煉,減少過度冗長的標點與敘述。有開發者表示,GPT-4.1 已成為其主要工作模型,尤其在 API 端表現突出。 - 中立與建設性批評
部分用戶指出,GPT-4.1 在遵循指令時過於謹慎,經常反覆請求用戶確認,導致流程變慢,尤其在自動化編輯或多步驟任務時顯得「太守規矩」。這種「過度合規」的行為雖然減少出錯,但也影響了使用體驗。 - 負面與比較意見
有 AI 顧問分享,GPT-4.1 在某些企業級任務(如 PDF 擷取、代理任務、分類器等)表現不如預期,甚至略遜於 4.0,且與 Gemini 2.5 Pro、Claude 3.7 等競品相比,複雜任務能力仍有差距。但也有用戶回應,4.1 在資料分析、代碼與溝通寫作上表現優異,顯示不同場景下的體驗差異。

專業觀點與未來展望
GPT-4.1 的最大突破在於「超長上下文」與「更可靠的指令遵循」。這對於需要處理大規模文本、跨文件推理的企業用戶與開發者來說,是一大福音。Mini 與 Nano 版本則讓 AI 更貼近日常應用與低成本部署。
但從 Reddit 社群的討論可見,模型在「過度守規則」與「複雜任務處理」上仍有優化空間。作為一名科技專欄作家,我認為 GPT-4.1 的定位更像是「專業輔助型」而非「全能型」AI。它在結構化、規則明確的任務上表現出色,但在開放式創意或多層次規劃上,仍需結合其他模型或人類專業。
結論
GPT-4.1 以「1 百萬 tokens 上下文」、「更強指令遵循」與「高效代碼生成」為核心賣點,成為開發者與企業用戶的新寵。Reddit 社群普遍給予正面評價,但也不乏理性批判。未來,隨著更多實際應用與用戶回饋,GPT-4.1 勢必會持續優化,成為 AI 生態系中不可或缺的關鍵角色。

GPT-4.1 與 GPT-4.5 的實戰應用對比:企業與開發者如何選擇?
GPT-4.1 與 GPT-4.5 是 OpenAI 針對不同場景優化的兩大模型,前者聚焦效率與結構化任務,後者強調語言流暢與創意。以下從五大關鍵維度解析兩者在實際應用中的表現:
1. 上下文處理與大規模資料分析
- GPT-4.1:支援 100 萬 tokens 超長上下文,可一次性處理完整代碼庫、法律文件或長篇財務報告,無需分段彙總。在 Thomson Reuters 的測試中,多文件法律分析準確率提升 17%,Carlyle 集團的財務資料擷取效率提高 50%。
- GPT-4.5:僅 128K tokens 上下文,適合一般對話與短文本創作,但面對跨文件推理或長程資料關聯時能力受限。
2. 程式開發與結構化輸出
- GPT-4.1:
- SWE-bench 軟體工程測試:解決真實代碼問題的準確率達 54.6%,超越 GPT-4o 的 33.2% 與 GPT-4.5 的 38%。
- 代碼差異比對:在 Aider 的 polyglot diff 測試中準確率 52.9%,比 GPT-4o 提升 2 倍,且冗餘代碼編輯從 9% 降至 2%。
- 前端開發實測:人類評測員在構建閃卡應用時,80% 更偏好 GPT-4.1 的輸出。
- GPT-4.5:專注於自然語言生成,在代碼任務上表現遜於 GPT-4.1,Reddit 用戶指出其邏輯推理與多步驟問題解決能力較弱。
3. 成本與部署效率
| 維度 | GPT-4.1 | GPT-4.5 |
|---|---|---|
| 輸入成本 | $2.0 / 百萬 tokens | $75 / 百萬 tokens |
| 輸出成本 | $8.0 / 百萬 tokens | $150 / 百萬 tokens |
| 延遲 | 與 GPT-4o 相當 | 較高 |
| 適用場景 | 高頻率 API 調用、生產環境 | 創意內容、情緒化互動 |
GPT-4.1 的 Mini 與 Nano 版本進一步優化成本,後者專為分類、補全等輕量任務設計,延遲低至 200ms。
4. 指令遵循與格式控制
- GPT-4.1:
- 嚴格遵循指令:在 MultiChallenge 測試中得分 38.3%,比 GPT-4o 高 10.5 點,能可靠執行多步驟指令與格式要求(如 XML、Markdown)。
- 減少人工修正:Hex 的 SQL 評估顯示,GPT-4.1 在選擇正確資料表的準確率提升近 2 倍。
- GPT-4.5:傾向壓縮或跳過次要步驟,需更多提示工程確保輸出符合要求。
5. 創意寫作與對話體驗
- GPT-4.5:
- 情感深度:在 Reddit 測試中,情緒辨識與語調調整能力優於 GPT-4.1,適合客服與故事創作。
- 語言流暢度:生成的文章結構更精緻,過渡自然,尤其在行銷文案與社群貼文上表現突出。
- GPT-4.1:輸出偏向簡潔直述,雖可靠但缺乏情感層次,適合技術文件與資料報告。
結論:應用場景決勝負
- 選擇 GPT-4.1:若需求為代碼開發、大規模資料分析、結構化輸出,或需低成本高頻率調用(如日誌處理、法律合約審查)。
- 選擇 GPT-4.5:若目標是創意內容生成、情感化對話(如品牌社群經營、故事寫作),且能接受較高成本與較慢回應。
OpenAI 已宣布將逐步淘汰 GPT-4.5,反映其戰略重心轉向實用性與生產力導向的 GPT-4.1。對於企業而言,GPT-4.1 的性價比與可靠度,使其成為整合至業務流程的首選。
GPT-4.1 與 GPT-4.5 大規模專案成本對比:企業如何節省 97% 預算?
GPT-4.1 的定價策略徹底改變大型 AI 專案的經濟效益,其成本僅為 GPT-4.5 的 3%-5%。以下從四大關鍵指標解析兩者差異:
1. 基礎定價差距
| 計費項目 | GPT-4.1 | GPT-4.5 | 節省比例 |
|---|---|---|---|
| 輸入 tokens | $2.0 / 百萬 | $75 / 百萬 | 97.3% |
| 輸出 tokens | $8.0 / 百萬 | $150 / 百萬 | 94.7% |
以處理 10 億 tokens 的典型大專案計算(輸入:輸出 = 3:1):
- GPT-4.1 總成本:
(750M × $2) + (250M × $8) = $1,500 + $2,000 = $3,500 - GPT-4.5 總成本:
(750M × $75) + (250M × $150) = $56,250 + $37,500 = $93,750
成本差距達 26.8 倍
2. 分級模型策略
GPT-4.1 提供三種規格,進一步優化成本結構:
| 模型 | 輸入成本 | 輸出成本 | 適用場景 |
|---|---|---|---|
| GPT-4.1 | $2.0 / 百萬 | $8.0 / 百萬 | 複雜代碼與長上下文分析 |
| GPT-4.1 Mini | $0.4 / 百萬 | $1.6 / 百萬 | 中等複雜任務 |
| GPT-4.1 Nano | $0.1 / 百萬 | $0.4 / 百萬 | 分類與自動補全 |
若專案包含 50% 簡單任務(使用 Nano)、30% 中等任務(Mini)、20% 複雜任務(標準版),總成本可再降低 62%。
3. 上下文視窗效率
- GPT-4.1:支援 100 萬 tokens 超長上下文,單次處理完整文件,減少 API 調用次數。
- GPT-4.5:僅 128K tokens,處理同等資料量需 7.8 倍 API 請求,隱形成本增加。
實測顯示,處理 50 萬 tokens 法律文件時,GPT-4.1 因無需分段處理,總 token 消耗減少 18%,回應時間縮短 40%。
六大 AI 模型橫向評比:GPT-4.1 與競品關鍵指標全解析
從上下文視窗到商業應用成本,本文以開發者與企業視角整理最新頂尖語言模型規格對照表,助您快速掌握技術差異與選型策略。
核心功能對照表
| 維度 | GPT-4.1 | GPT-o3 | Claude 3.7 Sonnet | Grok-3 | Gemini 2.5 Pro | DeepSeek V3 |
|---|---|---|---|---|---|---|
| 上下文視窗 | 1M tokens | 200K tokens | N/A | 128K tokens | 1M→2M tokens | 128K tokens |
| 核心優勢 | 代碼生成/長文件分析 | 數學推理/深度思考 | 混合推理/編程任務 | 即時數據/複雜問題拆解 | 多模態處理/超長上下文 | 成本效益/MoE 架構 |
| 輸入成本 | $2.0/百萬 tokens | $75/百萬 tokens | 免費層可用 | N/A | N/A | 業界最低 |
| 編程能力 | SWE-bench 54.6% | SWE-bench 71.7% | 業界頂尖 | 代碼準確率 +20% | 進階推理能力 | 高效能代碼生成 |
| 數學表現 | 未公開 | AIME 2024 96.7% | 未公開 | Big Brain 模式增強 | AIME 0.8 正確率 | 未公開 |
| 特殊功能 | 快取輸入 75% 折扣 | 三段式推理強度調節 | 可視化思考鏈 | DeepSearch 即時搜尋 | 支援音頻/影像輸入 | 多 Token 同步預測 |
| 發布時間 | 2025/04 | 2025/04 | 2025/02 | 2025/02 | 2025/03 | 2025/02 |
應用場景推薦
選擇 GPT-4.1:
- 需處理 百萬級法律文件/完整代碼庫 的企業
- 高頻 API 調用且重視 每 token 成本 的開發者
選擇 GPT-o3:
- 數學建模/科學計算等 深度推理任務
- 願意支付高價換取 AIME 96.7% 頂尖表現
選擇 Claude 3.7 Sonnet:
- 需要 可解釋性思考過程 的教學/審計場景
- 平衡 對話速度與複雜任務 的客服系統
選擇 Grok-3:
- 整合 X 平台即時數據 的社群分析
- 需 Big Brain 模式 處理多層次科研問題
選擇 Gemini 2.5 Pro:
- 多媒體內容生成與分析
- 即將擴充至 200 萬 tokens 的超長文件處理
選擇 DeepSeek V3:
- 預算有限的新創公司/個人開發者
- 需 修改開源模型 的客製化 AI 應用
技術亮點解析
- 成本革命:GPT-4.1 輸入成本僅 GPT-o3 的 2.6%,開啟 AI 大規模商用新紀元
- 架構創新:DeepSeek V3 的 MoE 架構實現 3 倍推理速度提升,適合邊緣運算
- 多模態競逐:Gemini 2.5 Pro 支援 音頻直接輸入,拓寬應用場景邊界
- 即時數據整合:Grok-3 的 DeepSearch 可直接調用 X 平台 最新社群趨勢
(本比較表依據各廠商公開資料與第三方評測整理,實際表現可能因使用場景而異)
FAQ
1. GPT-4.1 與 GPT-4.0 有哪些技術升級?
GPT-4.1 支援高達 100 萬 tokens 的超長上下文,是過去 GPT-4.0 的八倍。它在多步指令執行、代碼生成和結構化格式輸出方面有所提升,例如 XML 和 Markdown 的準確性明顯增強。
2. GPT-4.1 與 GPT-4.5 該如何選擇?
若需處理長文件(如法律文件或完整代碼庫),且重視操作成本,建議選擇 GPT-4.1;但若以創意寫作和情緒化對話為主,可考慮具有更高語言流暢度的 GPT-4.5。
3. GPT-4.1 對企業用戶的最大價值是什麼?
GPT-4.1 能一次處理百萬級的長文本,例如完整代碼庫或多文件分析,特別適合範疇為法律、財務和技術文件的應用。同時,它的成本較其它競品更具經濟效益,節約至 97%。
4. GPT-4.1 Mini 和 Nano 版本有什麼用途?
GPT-4.1 Mini 是速度與智能的平衡選擇,適合中等複雜的任務;Nano 版主打極速與低成本,適合輕量應用,如分類任務或補全操作。
5. 使用 GPT-4.1 是否需注意安全性問題?
GPT-4.1 保持與 GPT-4.0 同等的安全機制,在敏感訊息的處理上受控嚴格,避免處理過程中引入新的風險點。
- OpenAI - Tenten AI: 探索人工智慧的無限可能,科技新聞深度解析
- 性能的真相:OpenAI O3 與 O4 Mini 模型深度評測
- Gemini 2.5 Pro 與 ChatGPT-03 全面評測:誰是真正的AI王者?
- AI 的定義正在改變:迎接 OpenAI 的 o3 模型時代
- 領先 AI 模型評比 (2025/04):市場最強技術解析
- 解讀 OpenAI 思考模型 O3、O4 Mini、O4 Mini High 的核心秘密
- 告別 GPT-4: OpenAI 的前瞻視野
- GPT-5將要來了!AI要進化到什麼程度?

需要專業人士協助規劃和實施您的 AI 解決方案?Tenten 是一家 AI-First Agency,擁有豐富的 AI 整合經驗,可以幫助您評估不同模型優缺點,並為您的業務設計最優方案。無論您是需要高效的代碼分析、長文件處理還是客製化 AI 應用,我們都能提供符合您預算與需求的專業服務。立即預約諮詢,讓我們協助您駕馭 AI 革命的浪潮!