Databricks 懶人包來啦!一篇搞懂統一數據分析跟 AI 平台怎麼玩,讓你秒變數據達人!
在當今數據驅動的商業環境中,企業需要強大的工具來處理、分析和利用海量數據。Databricks 作為一個統一的開放式分析平台,正在幫助全球數千家企業實現數據與人工智能的轉型。這篇文章將帶您全面了解 Databricks,從基本概念到架構、功能以及使用案例,讓您對這個強大的平台有清晰的認識。
什麼是 Databricks?
Databricks 是一個統一的開放式分析平台,用於構建、部署、共享和維護企業級數據、分析和人工智能解決方案。這個雲端平台由 Apache Spark 的原始創建者於 2013 年創立,目前已成為數據和人工智能領域的領導者。
Databricks 將數據湖和數據倉庫的優點結合在一起,創建了所謂的「數據湖倉」(Data Lakehouse)架構,讓您可以在一個統一的平台上處理結構化和非結構化數據。這意味著數據工程師、數據科學家和分析師可以在同一個平台上協作,無需在多個系統之間切換。
作為一個完全雲原生的平台,Databricks 可以在主要的雲服務提供商上運行,包括 AWS、Microsoft Azure、Google Cloud 和 Alibaba Cloud。
- Meta 支援數據分析新創公司 Databricks,這家公司正準備 IPO — Meta backs Databricks as the data analytics startup inches toward IPO
- 「今年進行 IPO 是愚蠢的」:Databricks 執行長解釋他為何等待上市 | TechCrunch — 'It's dumb to IPO this year': Databricks CEO explains why he's waiting to go public | TechCrunch
- Databricks:為 2025 年 IPO 做好準備 — Databricks: Ready for 2025 IPO
- Forge IPO 新聞 - Databricks 即將進行 IPO 及私募股票價格 — Forge IPO News - Databricks' Upcoming IPO & Private Stock Price
Databricks 架構
Databricks 採用了雙層架構設計,由控制平面(Control Plane)和數據/計算平面(Data/Compute Plane)組成。這種架構設計確保了安全性、可擴展性和靈活性。
| 架構層 | 說明 | 主要功能 |
|---|---|---|
| 控制平面 | 由 Databricks 管理的後端服務 | 用戶訪問管理、工作區、作業調度、元數據存儲 |
| 數據/計算平面 | 數據處理的地方 | 可以在客戶的雲帳戶中(傳統模式)或在 Databricks 帳戶中(無服務器模式) |
傳統的 Databricks 架構中,控制平面由 Databricks 完全管理,而計算平面則託管在您的雲環境中(AWS、Azure 或 Google Cloud)。無服務器計算模式則提供了更簡化的體驗,Databricks 會自動處理資源配置和擴展。
Databricks 核心組件
Databricks 平台包含多個強大的組件,共同提供完整的數據管理和分析能力:
Delta Lake
Delta Lake 是 Databricks 的優化存儲層,為表格在湖倉中提供基礎。它是開源軟件,擴展了 Parquet 數據文件,提供基於文件的事務日誌,支持 ACID 事務和可擴展的元數據處理。Delta Lake 與 Apache Spark API 完全兼容,並為結構化流處理提供緊密集成。
MLflow
MLflow 是一個開源平台,用於開發模型和生成式 AI 應用程序。它具有以下主要組件:
- 追蹤:允許追蹤實驗,記錄和比較參數與結果
- 模型:管理和部署來自各種 ML 庫的模型
- 模型註冊表:管理模型從準備到生產的部署過程
- AI 代理評估和追蹤:幫助比較、評估和排除 AI 代理的問題
Unity Catalog
Unity Catalog 提供集中式訪問控制、審計、血統和跨 Databricks 工作區的數據發現功能。它基於標準 ANSI SQL 的安全模型,允許管理員使用熟悉的語法授予權限,並自動捕獲用戶級別的審計日誌和血統數據。
Photon
Photon 是 Databricks 的高性能、原生、向量化查詢引擎,完全用 C++ 編寫,主要目標是加速 SQL 和 DataFrame 工作負載。它能夠顯著提高查詢性能,不需要對現有工作負載進行任何修改,並且與 Apache Spark API 完全兼容。
SQL Warehouses
SQL Warehouses 是執行 SQL 查詢的計算資源,有三種主要類型:
| 類型 | 特點 | 適用場景 |
|---|---|---|
| Classic | 支持基本功能 | 入門級性能需求 |
| Pro | 提供增強性能,支持 Photon 向量化查詢引擎 | 高性能分析 |
| Serverless | 消除基礎設施管理,自動配置資源和彈性擴展 | 按需查詢分析 |
Databricks 主要使用案例
Databricks 平台能夠支持多種數據和 AI 使用案例,幫助企業從數據中獲取價值:
數據工程和 ETL
Databricks 提供強大的工具和功能用於 ETL (提取、轉換、加載) 工作流程:
- Delta Live Tables (DLT):簡化 ETL 開發,編纂最佳實踐並自動化操作複雜性
- 統一的數據處理:處理批處理和實時數據流
數據分析和商業智能
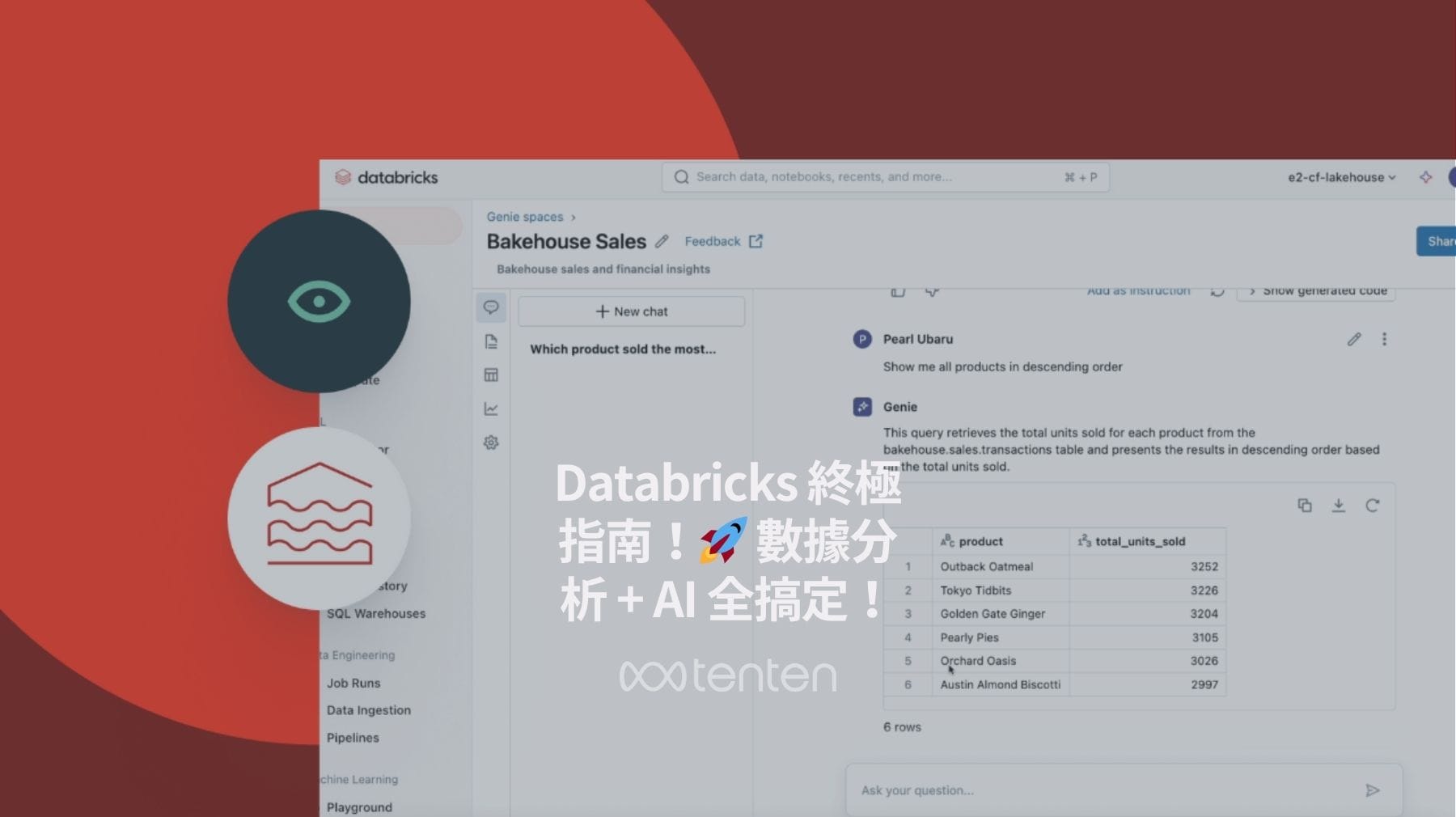
Databricks SQL 是 Databricks Lakehouse 平台內的強大分析工具,允許數據專業人員運行 SQL 查詢、分析數據和創建交互式儀表板。它的特點包括:
- SQL 編輯器:直觀的查詢界面,支持語法高亮和自動完成
- 查詢結果緩存:提高重複查詢的響應時間
- 與 BI 工具整合:支援 Power BI、Tableau 和 Looker 等
機器學習和 AI 模型開發
Databricks 為機器學習和 AI 模型開發提供了完整的生命週期管理:
- 實驗追蹤:記錄和比較實驗參數和結果
- 模型註冊和部署:管理模型從開發到生產的整個過程
- 生成式 AI 支持:開發和評估高質量的 AI 代理
供應鏈管理
Databricks 使企業能夠利用需求預測、實時跟踪和倉庫分析來維持最佳庫存水平。通過分析歷史趨勢、供應商性能和外部因素,Databricks 幫助企業預測和減輕潛在的供應鏈中斷。

Databricks 安全與合規
Databricks 將安全性建立在平台的每一層,提供全面的安全功能來保護您的數據和工作負載:
| 安全功能 | 說明 |
|---|---|
| 加密 | 保護靜態和傳輸中的數據 |
| 網絡控制 | 限制對資源的訪問 |
| 審計 | 記錄用戶活動和數據訪問 |
| 身份集成 | 與企業身份提供者整合 |
| 訪問控制 | 基於角色的精細權限管理 |
| 數據治理 | 通過 Unity Catalog 提供集中式治理 |
Databricks 擁有多種認證和合規證明,能夠滿足高度監管行業的獨特合規需求,同時重視數據隱私,幫助您遵守隱私法律和監管要求。
Databricks 生態系統和合作夥伴
Databricks 擁有超過 5000 個全球合作夥伴,提供數據、分析和 AI 解決方案和服務:
- 雲合作夥伴:AWS、Microsoft Azure、Google Cloud 和 Alibaba Cloud
- 技術合作夥伴:提供 ETL、數據攝取、BI、ML 和治理的互補功能
- 諮詢合作夥伴:幫助企業策劃、實施和擴展數據、分析和 AI 計劃
如何開始使用 Databricks
開始使用 Databricks 相對簡單。您可以選擇適合您需求的雲提供商(AWS、Azure 或 Google Cloud),然後設置 Databricks 工作區。一旦設置完成,您就可以創建集群、筆記本,並開始分析您的數據。
Databricks Academy 是所有官方 Databricks 培訓的主要來源,提供各種學習路徑,不僅提供深入的技術培訓,還可以讓業務用戶熟悉平台。
Reddit 上關於 Databricks 的熱門討論分析
在 Reddit 的技術社群中,Databricks 作為數據平台的核心工具,持續引發廣泛討論。以下是從多個子版塊(如 r/databricks、r/dataengineering、r/bigdata)整理出的關鍵議題,涵蓋技術挑戰、工具整合、成本管理及未來發展方向。
技術挑戰與效能優化
許多用戶反映,在開發環境中使用 DLT 時,每次測試變更需等待 3-5 分鐘的集群啟動時間,嚴重影響迭代效率。部分解決方案包括:
- 啟用 Development Mode,避免每次運行都重新啟動集群
- 改用 Serverless 計算,利用其快速啟動特性縮短等待時間
- 建議在正式部署前,先透過 Workflows 進行效能調校
有團隊發現,使用 AWS Spot 實例進行自動擴展時,可能在 Shuffle 階段因實例中斷導致數據丟失。儘管官方文件強調架構可靠性,但實務上仍需透過以下措施降低風險:
- 確保 Driver 節點運行於非 Spot 實例
- 設計 冪等性(Idempotent)的批次作業,確保重複執行不會產生副作用
- 針對 S3 儲存的多驅動器寫入衝突,啟用
delta.enableS3MultiClusterWrites設定以避免數據覆蓋
工具整合與 BI 生態系
Power BI 用戶在 DirectQuery 模式下面臨查詢延遲問題,尤其當 Databricks 視圖複雜時,物化視窗(Materialized Views)成為常見解決方案。然而,部分團隊轉向 Sigma 或 Holistics 等現代 BI 工具,雖需持續啟動 SQL Warehouse 集群,但能換取更高的分析彈性。值得注意的是,Databricks SQL Dashboard 因其原生整合優勢,被推薦用於即席分析場景。
社群對 Databricks 新推出的 AI/BI Genie 功能高度期待,其自然語言轉換為視覺化報表的能力,被視為挑戰 Power BI 和 Tableau 的潛力股。此外,第三方工具如 Zing Data 和 getdot.ai 因支援 Slack/Teams 整合,成為快速探索數據的輔助選項。
成本控制與架構最佳化
Reddit 用戶普遍認為,Job Clusters 比 All-Purpose Clusters 更適合生產環境,因其資源配置針對任務執行最佳化,且成本較低。Serverless SQL Warehouse 則因按查詢計費模式,成為臨時分析的熱門選擇,但需注意閒置時的自動暫停機制。
在 Lakehouse 設計中,Bronze 層是否需完全複製原始數據引發討論。部分團隊主張透過 Delta Sharing 直接存取外部數據源,避免重複儲存;另一方則認為 Bronze 層的原始備份對稽核與回溯至關重要。實務上,可透過 Unity Catalog 的跨平台權限管理,平衡數據存取與儲存成本。
社群對 Databricks 將部分功能(如 Unity Catalog)轉為商業版感到不滿,認為其開源承諾「名不符實」。對此,用戶建議評估 Apache Iceberg 等替代方案,尤其在需高度客製化的場景中。
Databricks: 統一的數據和 AI 平台
Databricks 作為一個統一的數據和 AI 平台,正在幫助全球數千家企業從他們的數據中獲取更多價值。通過結合數據湖和數據倉庫的優點,Databricks 提供了一個強大、靈活且易於使用的平台,適用於各種數據處理、分析和 AI 用例。
無論您是尋求改進數據工程流程、加速分析洞察,還是開發先進的機器學習模型,Databricks 都提供了所需的工具和功能。隨著數據和 AI 在商業中的重要性不斷增長,Databricks 無疑將繼續成為企業數據策略的關鍵組成部分。
從 Reddit 討論可歸納出三大核心建議:
- 效能與成本平衡:優先採用 Serverless 與 Job Clusters,並透過 System Tables 持續監控資源使用
- 工具整合策略:評估 BI 工具時,需同步考量查詢模式與集群成本,善用 Databricks SQL 原生儀表板減少外部依賴
- 架構現代化:逐步導入 Unity Catalog 治理,並在開源與商業功能間取得平衡,避免供應商鎖定
最終,Databricks 的價值體現於「統一平台」的協作潛力,但成功與否則取於團隊是否深入理解其限制,並制定務實的優化策略。
Databricks收購案列表
| 收購時間 | 公司名稱與連結 | 收購金額 | 主要技術/產品 | 整合後應用 |
|---|---|---|---|---|
| 2020年6月 | Redash | 未公開 | 開源資料視覺化與儀表板平台 | 整合至Databricks平台,強化資料可視化與協作功能 |
| 2021年10月 | 8080 Labs | 未公開 | 低代碼資料科學工具Bamboolib | 開發Databricks低代碼介面,擴展公民資料科學家用戶群 |
| 2023年5月 | Okera | 未公開 | AI驅動資料治理平台,專注元數據管理與存取控制 | 整合至Unity Catalog,強化資料治理與合規性 |
| 2023年6月 | MosaicML | 13億美元 | 生成式AI模型訓練平台,擁有MPT系列大型語言模型 | 發展為Databricks Mosaic AI,成為端到端AI開發平台 |
| 2023年6月 | Rubicon | 未公開 | AI儲存基礎設施技術 | 強化湖倉平台儲存層效能,優化AI工作負載支援 |
| 2023年10月 | Arcion | 1億美元 | 即時資料複製技術,支援CDC與多雲端資料同步 | 整合至Lakeflow產品線,強化即時資料管道能力 |
| 2024年3月 | Lilac AI | 未公開 | 非結構化文字資料分析工具,專注AI模型訓練資料準備 | 強化生成式AI的資料準備流程 |
| 2024年4月 | Einblick | 未公開 | 自然語言轉代碼技術,實現低代碼資料分析 | 開發自然語言介面,整合至Databricks SQL與AI工具鏈 |
| 2024年6月 | Tabular | 超過10億美元 | Apache Iceberg格式創始團隊,資料湖管理解決方案 | 推動Delta Lake與Iceberg格式兼容性,建立開放湖倉架構標準 |
| 2025年2月 | BladeBridge | 未公開 | AI驅動資料倉庫遷移工具,支援20+種資料源轉換 | 加速企業從Snowflake等平台遷移至Databricks SQL |
| 2025年5月 | Neon | 約10億美元 | Serverless PostgreSQL平台,具備資料庫分支與自動擴展功能 | 強化AI代理基礎設施,整合至資料智能平台 |
技術整合亮點:
- Neon:將PostgreSQL即時佈建能力與AI工作流結合,支援每秒數千次AI代理操作
- Tabular:解決Delta Lake與Iceberg格式戰爭,客戶遷移成本降低60%
- MosaicML:使客戶訓練專屬LLM成本降低5倍,模型部署時間從數週縮短至數小時
戰略布局分析:Databricks透過收購完成「資料+AI」閉環,從資料湖倉儲擴展至全棧AI基礎設施,直接挑戰AWS、Google Cloud等雲端巨頭。

FAQ
- 什麼是 Databricks?
- 解答: Databricks 是一個統一的雲端分析平台,結合「數據湖」與「數據倉庫」的優勢,構建出「數據湖倉」(Data Lakehouse)架構。該平台支援數據處理、分析及人工智慧應用,可在 AWS、Azure、Google Cloud 等主要雲服務上運行。
- Databricks 的核心組件有哪些?
- 解答: Databricks 平台具備多個核心組件,包括:
- Delta Lake: 支援 ACID 交易並提升儲存層效率。
- MLflow: 管理機器學習模型全生命週期。
- Unity Catalog: 提供集中化數據治理與訪問控制。
- Photon: 加速 SQL 和 DataFrame 查詢性能的原生查詢引擎。
- Databricks 的主要使用案例是什麼?
- 解答: Databricks 支援多種使用場景,包括:
- 數據工程與 ETL(數據提取、轉換、加載)。
- 數據分析與商業智能(BI)。
- 開發機器學習和生成式 AI 模型。
- 供應鏈管理及預測分析。
- 如何控制運行 Databricks 的成本?
- 解答:
- 使用任務型叢集(Job Clusters)取代通用叢集(All-Purpose Clusters)。
- 在 SQL 查詢分析中採用無伺服器 SQL 知識庫(Serverless SQL Warehouses),並啟用閒置自動暫停功能。
- 使用 Unity Catalog 平衡數據存取權限和儲存成本。
- Databricks 與 Apache Spark 有什麼關係?
- 解答: Databricks 由 Apache Spark 的原創者於 2013 年創立,並將 Spark 作為其平台的核心組件,進行強化和改進。Databricks 提供對 Apache Spark 的全方位功能支持,包括批處理和流處理兩種模式。
讓 Tenten 協助您的數據轉型之旅
在數據驅動的時代,選擇正確的數據分析平台與實作策略對企業成功至關重要。Tenten 是一家專業的數位代理機構,擁有豐富的 Databricks 實作經驗與數據工程專業知識。我們協助企業建立完整的數據湖倉架構,優化 ETL 流程,並導入先進的機器學習模型。
無論您是剛開始探索 Databricks 的潛力,還是需要優化現有的數據基礎設施,我們的專業團隊都能為您提供量身定製的解決方案。從架構設計、成本優化到團隊培訓,Tenten 將成為您在數據轉型路上的最佳夥伴。
準備好開始您的數據轉型之旅了嗎?立即預約諮詢,讓我們的專家團隊為您制定最適合的 Databricks 實作策略