
OpenClaw 在 2026 年初成為 GitHub 上成長速度最快的開源專案之一,累積超過 20 萬顆星。這個由奧地利開發者 Peter Steinberger 創建的 AI 代理框架,能透過 WhatsApp、Telegram、Slack 等通訊平台執行真實世界的任務。然而,從安裝到穩定運作之間存在一段顯著落差,多數使用者在最初兩週內就會遭遇 token 燒毀、agent 迴圈、指令失靈等問題。
本文整理社群中實際驗證有效的七項操作原則,適用於正在評估或已開始使用 OpenClaw 的開發者與技術決策者。
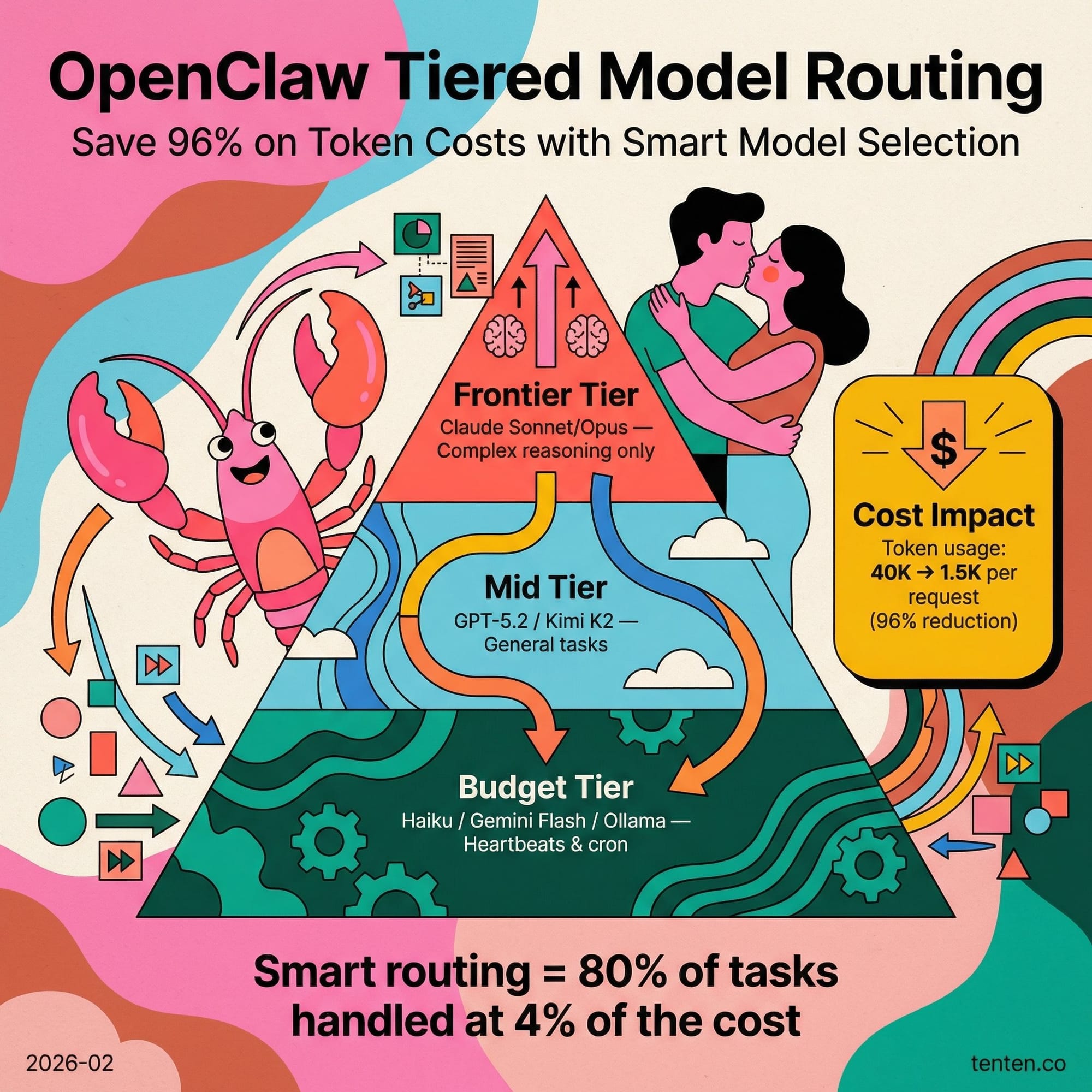
一、分層模型配置:別把所有任務都丟給最強模型
多數新手犯的第一個錯誤是讓所有任務都透過 Claude Sonnet 或 GPT-4 等級的模型執行。heartbeat 檢查、排程任務、例行性 cron job 並不需要頂級模型的推理能力,卻會消耗相同等級的 token 成本。
實務上,有效的配置方式是建立分層架構:以低成本模型(如 Haiku、Gemini Flash,或透過 Ollama 執行的本地模型)處理一般性任務,僅在需要複雜推理時才調用 Sonnet 或 Opus。社群中已有使用者透過此策略,將單次請求的 token 消耗從 20,000–40,000 降低至約 1,500。OpenClaw 支援在工作階段中以 /model 指令即時切換模型,這讓動態路由成為可行方案。
這個原則的底層邏輯與 Claude Code Router 的設計理念相通:將運算資源導向真正需要的地方,而非均勻分配。
二、用 SKILL.md 建立明確的行為護欄
OpenClaw 預設狀態下的表現相當不穩定。它會陷入迴圈、重複執行相同動作、遺失上下文,甚至做出與指令無關的決策。根本原因在於 agent 本身缺乏足夠的行為約束。
解決方案是在 workspace 的 skills/ 資料夾中建立自訂的 SKILL.md 檔案。每個 SKILL.md 包含 YAML frontmatter(名稱與描述)和 Markdown 格式的行為指令。這些檔案的功能類似於提示工程中的系統提示(system prompt),明確告訴 agent 何時該做什麼、何時該停止。
關鍵的護欄設計包括:防迴圈規則(偵測到重複行為時自動中斷)、上下文壓縮摘要(在長對話中定期濃縮已處理的資訊)、任務檢查點(在向使用者提問前先完成基本驗證)。表現良好的 OpenClaw 部署通常都有經過大量客製化的指令集,開發者需要自行研究並撰寫適合自身工作流的規則。
Skills 的載入遵循優先序:workspace 內的 skills 最優先,其次是 ~/.openclaw/skills 中的本地 skills,最後是內建的 bundled skills。這代表你可以在不修改系統檔案的情況下覆蓋任何預設行為。
三、背景工作需要 cron job,不是「讓 agent 跑著」
一個常見的誤解是認為 OpenClaw 可以在關閉聊天視窗後繼續自主執行任務。事實是 OpenClaw 的 session 僅在連線期間保持狀態(stateful only while open)。一旦你關閉對話或離開,agent 會遺失當前的工作上下文。
要實現真正的背景自動化,需要依賴 OpenClaw 內建的 cron 排程系統。具體做法是設定具有獨立 session target 的 cron job,讓系統在預定時間啟動獨立的 agent session 並回報執行結果。針對一次性的延遲任務(例如「明天早上幫我寄出這封信」),更穩定的架構是使用任務佇列(Notion 資料庫、SQLite、或純文字檔案),搭配定期檢查佇列的 cron job 來處理。
這個限制與 Claude Code Sub Agents 的運作邏輯有本質差異。Claude Code 的 sub-agent 可以在主 session 存續期間並行處理任務,而 OpenClaw 的架構則要求你明確設計持久化機制。
四、一次只整合一個工作流,端到端驗證後再擴展
嘗試同時設定 email、行事曆、Telegram、網頁爬取和 cron job 是效率最低的做法。每一個整合都是獨立的失敗點(separate failure mode),任何一個環節出問題都會影響整體除錯。
經過實戰驗證的策略是:選擇一個完整的工作流(例如每天早上 8 點的新聞摘要推送),從頭到尾讓它穩定運作後,再加入下一個整合。這與企業 AI 自動化的導入邏輯一致:先在單一場景驗證價值,建立信心後再橫向擴展。
當系統出現異常時,openclaw doctor --fix 指令可以診斷並修復常見的配置問題。這個工具會檢查 DM policy 設定、PATH 環境變數、skill 依賴關係等潛在問題。
五、用持久化文件保存有效的配置與決策
OpenClaw 的 compaction 機制(上下文壓縮)會在長時間使用後逐漸流失重要的脈絡資訊。如果 agent 每次啟動都需要從頭學習你的偏好和過往決策,效率會持續下降。
務實的解決方案是維護 workspace 中的核心文件:USER.md(你的個人資訊與偏好)、AGENTS.md(agent 的角色定義與行為準則)、HEARTBEAT.md(定期檢查的排程與內容),以及 MEMORY.md(長期記憶與重要決策記錄)。將關鍵決策與成功的配置方案寫入這些檔案,可以大幅減少 agent 的重新學習成本。
這個做法呼應了 AI Agent 系統設計中的一個核心原則:agent 的效能與它能存取的結構化知識成正比。

六、模型品質決定 agent 品質
許多使用者對 OpenClaw 的挫敗感其實來自底層模型的 tool call 能力不足。聊天品質和 agent 品質是兩回事:一個模型能夠在對話中產出流暢的回覆,不代表它能可靠地呼叫工具、解析回應並鏈接多步驟操作。
根據社群回饋,以下是各模型在 agent 任務中的表現分級:
| 模型 | Agent 工作表現 | 適用場景 |
|---|---|---|
| Claude Sonnet / Opus | 工具呼叫可靠,推理品質穩定 | 主要 orchestrator |
| GPT-5.2(API) | tool call 處理能力良好 | 替代方案 |
| Kimi K2(API) | tool call 品質可接受 | 成本敏感場景 |
| DeepSeek Reasoner | 推理能力強但工具呼叫易出錯 | 不建議用於 agent |
| GPT-5.1 Mini | 成本極低但 agent 能力有限 | 僅適合簡單任務 |
模型選擇的重要性在於 OpenClaw 會組裝大量的 prompt(系統指令、對話歷史、工具 schema、skills、memory),這些 context load 需要前沿模型才能有效處理。多數穩定運作的部署都以 Claude 或 GPT 作為主要 orchestrator,搭配低成本模型處理 heartbeat 和子任務。

七、困難是正常的,成功需要時間
OpenClaw 目前仍處於快速迭代階段,GitHub 上那些「一夜之間用 agent 做出完整應用」的展示通常省略了數週的調校過程。demo 展示與日常穩定使用之間的落差是真實的,但這個落差正在快速縮小。
Peter Steinberger 在 2026 年 2 月宣布加入 OpenAI,並將 OpenClaw 移交至開源基金會管理。這個轉變意味著專案的治理結構將更加正式,但也帶來社群方向可能調整的不確定性。從開源 AI 模型的發展軌跡來看,社群驅動的專案在獲得企業支持後通常會加速成熟,前提是治理架構設計得當。
安全性考量不可忽略
在投入 OpenClaw 之前,技術決策者需要正視其安全風險。CrowdStrike 的分析報告明確指出,配置不當的 OpenClaw 實例可能被利用為 AI 後門,具備從連接系統洩漏敏感資料的能力。Cisco 的 AI 安全研究團隊在測試第三方 skill 時也發現了資料外洩和 prompt injection 的風險。
對企業環境而言,在具備完善的安全治理框架之前,OpenClaw 更適合作為技術探索工具而非正式的生產環境方案。如果你的組織正在評估 AI Agent 的企業部署,建議先從受控環境開始,並建立明確的權限邊界。
引用來源
- OpenClaw Official Documentation — https://docs.openclaw.ai/
關於作者
Tenten 團隊長期追蹤 AI 開發工具與 agent 框架的演進,從 Claude Code 到 OpenClaw,我們的觀察是:工具的進化速度遠超過多數組織的適應速度。OpenClaw 的價值不在於它現在能做什麼,而在於它揭示的方向——個人化、本地優先、可程式化的 AI 代理將成為開發者工具鏈的標準組件。當前最務實的投入方式是選定一個具體的自動化場景,嚴格遵循分層配置與漸進式整合的原則,在可控範圍內累積實戰經驗。
若您希望進一步了解 AI Agent 與自動化工作流的企業導入策略,歡迎與 Tenten 團隊預約諮詢,探討最適合您組織的解決方案。
延伸閱讀:








