了解 NVIDIA NeMo 如何成為對話式 AI 開發的強大引擎,幫助開發者創造更具吸引力、更有效率的應用程式。
隨著人工智慧(AI)技術日益精進,市場對高效開發與部署 AI 模型的需求也越來越高。NVIDIA NeMo 正是專為滿足這類需求而生的一套開源工具,能協助企業與開發者在雲端、資料中心甚至邊緣裝置上,更輕鬆地構建、訓練並部署強大的語音、語言及文字轉語音應用。本文將為你全面解析 NVIDIA NeMo 的關鍵特色、功能與典型應用場景,帶你深入了解如何善用這款頂尖的 AI 工具。
NVIDIA NeMo 是什麼?
NVIDIA NeMo 是由 NVIDIA 推出的開源工具包,主要針對自然語言處理(NLP)、語音以及文字轉語音(TTS)等領域的 AI 模型所設計。它不僅整合了強大的資料處理與訓練功能,還提供生產就緒的部署方案,讓更多產業能輕鬆導入生成式 AI,以提高營運效率並推動創新應用。
NeMo 的核心功能
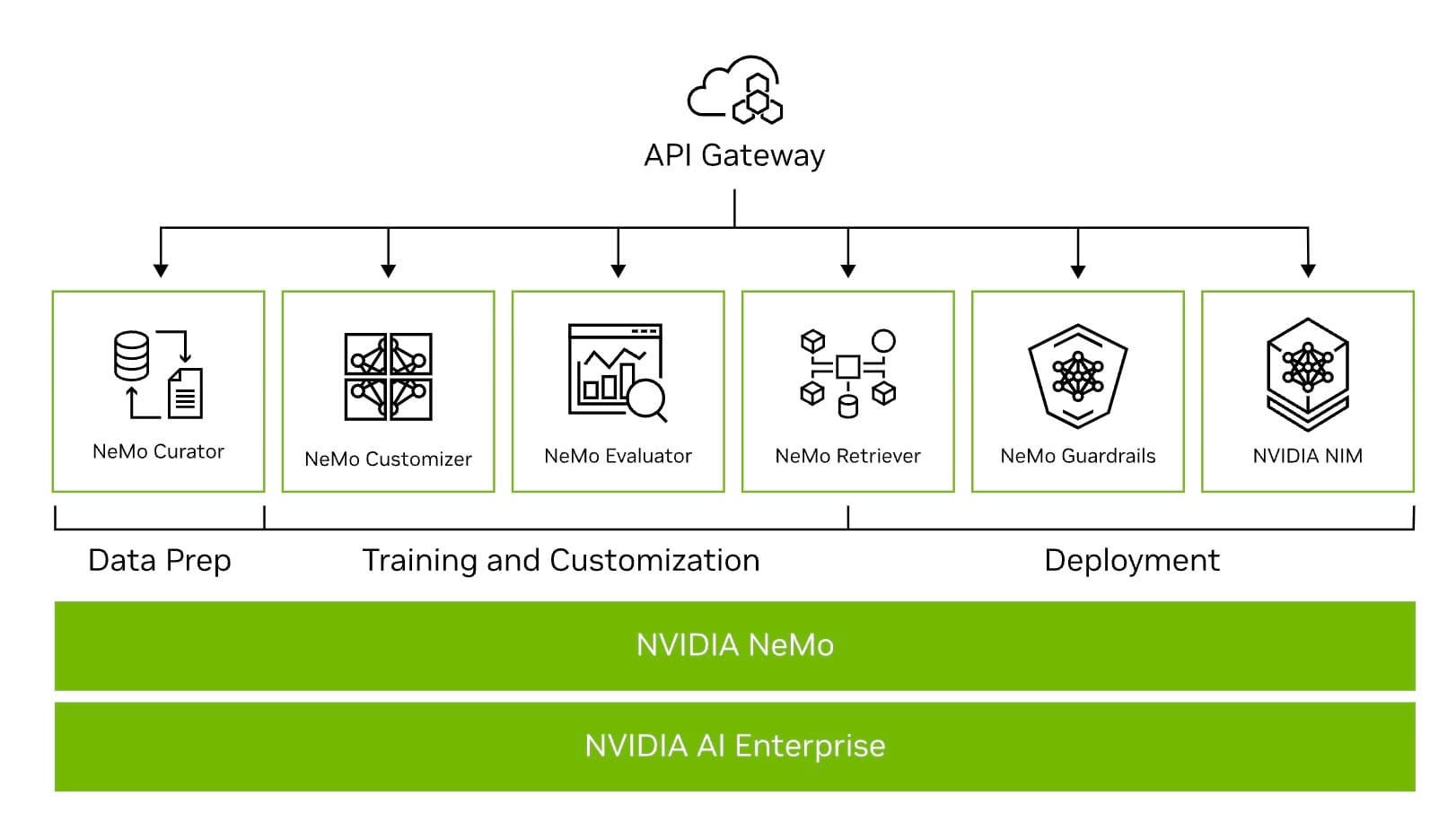
在 NVIDIA NeMo 的全貌中,可將功能概略分成三大部分:資料準備、訓練與客製化,以及部署支援。以下分別說明各主要元件的亮點:
- Nemo Curator(資料準備加速器)
- NVIDIA NeMo 中的 Curator 工具,能以 GPU 加速方式快速整理與產生高品質的大規模資料集,為預先訓練大型語言模型(LLM)提供穩固基礎。
- Nemo Customizer(客製化微服務)
- 透過 Customizer,使用者可有效率地微調與對齊大型語言模型,滿足各種領域的應用需求。這項功能將生成式 AI 技術整合到更多行業之中,打造更合適的垂直解決方案。
- Nemo Evaluator(模型評估微服務)
- Evaluator 能夠在任意平台上快速評估生成式 AI 模型的表現,不論是標準學術基準,或是針對企業自訂化需求的評量,都能加以測試並提供深入分析。
- NVIDIA Retrieval(資料檢索微服務)
- 此工具可協助企業將客製化模型與各式商業數據連結,以提供更準確的回答或分析結果。它支援簡易的系統整合並提升模型回應的精確度。
- Nemo Guardrails(多層防護機制)
- Guardrails 在對話管理的過程中扮演關鍵角色,確保生成式模型在內容適當性、安全性與合規性上都能滿足企業需求,協助用戶更安心地使用 NVIDIA NeMo。
- NVIDIA NeMo Inference(安全穩定的推論部署)
- 作為 NVIDIA AI Enterprise 產品的一部分,NeMo Inference 微服務提供高效且可靠的推論部署環境,可在雲端、資料中心或工作站上運行大型語言模型,簡化安裝並確保最高的執行效率與安全性。
NVIDIA NeMo 的四大優勢
- 跨環境彈性部署
- 可在公有雲、私有雲、資料中心及邊緣裝置靈活部署 NVIDIA NeMo,協助開發者根據實際需求選擇最合適的平台。
- 生產就緒與企業級穩定性
- 作為 NVIDIA AI Enterprise 套件的一部分,NVIDIA NeMo 提供安全性、技術支持與 API 穩定度,能讓企業快速進入量產環境。
- 提升投資報酬率
- NVIDIA NeMo 結合多 GPU、跨節點訓練與推論技術,加速開發週期、縮短時程,降低專案的整體成本並提高投資效益。
- 效能優化與完整工作流程
- 從資料準備、模型訓練與微調到推論階段,NVIDIA NeMo 都提供整套解決方案與工具,滿足各式生成式 AI 需求。
NeMo 模組化架構與關鍵技術
- 預訓練模型(Pre-trained Models)
- NVIDIA NeMo 內建多種預訓練模型,用於自動語音辨識(ASR)、文字生成、機器翻譯等領域。開發者可透過遷移學習,快速將這些模型微調至各種應用場景。
- 模組化設計(Modular Architecture)
- 透過模組化的方式,使用者能自由組合和連結如語音轉文字、文字處理、文字轉語音等功能元件,打造專屬的 AI 工作流程。
- 大型語言模型訓練(Nemo Megatron)
- NVIDIA NeMo 內含的 Megatron 框架支援大規模 Transformer 模型的訓練,可處理數十億甚至上兆參數,輕鬆打造與 GPT-4 等級的先進生成式模型。
- 對話式應用最佳化
- NVIDIA NeMo 專為構建對話式智慧助理、聊天機器人與虛擬助理而設計,結合語言理解、語音交互及多模態整合,大幅提升使用者體驗與互動品質。
典型應用情境
- 語音辨識與合成
- 應用於智慧客服與虛擬助理,支援自動語音辨識(ASR)和文字轉語音(TTS),大幅縮短訊息傳遞時間,並提供更自然的語音互動。
- 自然語言理解
- 用於情感分析、問題解答與聊天機器人等。藉由 NVIDIA NeMo 的微調與評估工具,可打造更精準的語言模型,提供更貼近用戶需求的對話體驗。
- 生成式應用
- NVIDIA NeMo 可為新聞摘要、內容撰寫、機器翻譯等提供強大的文字生成能力,協助企業或研究人員快速產生高品質文本內容。
- 多產業落地範例
- 包括醫療、金融、電商等垂直領域。透過 NVIDIA NeMo,可快速佈署語音客服、對話式機器人或智慧助理,以應對各種商業需求與挑戰。
Nvidia Nemo 核心功能
- 生成式 AI 模型的開發與定制
NeMo 提供了一整套工具,包括 GPU 加速的數據處理工具(如 NeMo Curator),用於準備高質量的大規模數據集進行模型訓練。NeMo Customizer 則支持對模型進行微調和領域特定的對齊,以滿足企業需求。 - 預訓練模型與腳本
NeMo 提供多種預訓練模型及其訓練腳本,例如支持 Llama 2 和 NVIDIA Nemotron 系列模型,幫助快速開發應用或進行特定任務的微調。 - 檢索增強生成(RAG)功能
NeMo Retriever 支持高性能、低延遲的信息檢索,通過檢索增強生成技術將模型與企業數據連接,實現上下文感知的回應和洞察。 - 安全性與合規性保障
NeMo Guardrails 提供針對生成式 AI 的安全功能,如內容安全、主題控制和防篡改檢測,確保 AI 模型在特定情境中生成安全且適當的回應。
應用場景
NVIDIA NeMo 被廣泛應用於多個行業,包括:
- 客戶服務:通過智能代理加速問題解決,提高客戶滿意度。
- 醫療健康:在醫院等設施中運行低延遲的語音或文本處理應用。
- 製造與零售:優化供應鏈管理和庫存控制。
- 金融與汽車:增強欺詐檢測及語音交互功能。
部署選項
NeMo 平台支持靈活的部署方式,包括:
- 自我托管:下載容器並在任何環境中運行。
- 雲端托管:使用 DGX Cloud 或其他流行雲服務提供商進行管理。
NVIDIA NeMo 的未來方向
隨著 Agentic AI(代理型人工智慧)的興起,NVIDIA 推出了 Nemotron 模型系列,專注於支持複雜任務的專業化智能代理。這些模型包括 Nano、Super 和 Ultra 三種規模,適用於從低延遲邊緣設備到高性能數據中心的各種需求。
總而言之,NVIDIA NeMo 為企業提供了一個強大且靈活的平台,用於構建和部署生成式 AI 解決方案,其全面的工具集和安全功能使其成為各行業實現生產力提升的重要助力。

NVIDIA NeMo 與其他生成式 AI 架構相比有何優勢?
NVIDIA NeMo 與其他生成式 AI 框架的比較
NVIDIA NeMo 是一個專為生成式 AI 設計的端到端框架,與其他生成式 AI 平台相比,其在性能、靈活性和功能上具有顯著優勢。以下是 NeMo 與其他框架的主要比較:
1. 性能與擴展性
- NVIDIA NeMo
NeMo 利用 NVIDIA 的高效硬體(如 H100 GPU 和 Tensor Cores)以及先進的平行化技術(如 Fully Sharded Data Parallelism、Tensor Parallelism 和 Expert Parallelism),使其能夠高效處理具有數十億到數兆參數的大型語言模型(LLMs)。例如,NeMo 在 MLPerf 基準測試中展示了卓越的 GPT-3 性能,並支持多節點和多 GPU 的線性擴展。 - 其他框架
像 Hugging Face Transformers 和 OpenAI 的工具也提供了 LLM 支援,但在極大規模模型的訓練和推論性能上,通常無法匹敵 NVIDIA 硬體和 NeMo 的深度整合。
2. 多模態支援
- NVIDIA NeMo
NeMo 支援多模態生成式 AI,包括語言、圖像、視訊和語音模型。它的新功能允許用戶輕鬆處理高品質視覺數據並進行多模態模型的訓練與推論,如 LLaVA 和 CLIP。 - 其他框架
雖然一些框架(如 PyTorch 和 TensorFlow)也支持多模態應用,但它們通常需要更多的手動整合,且缺乏 NeMo 提供的即用型工具和工作流。
3. 模型定制與微調
- NVIDIA NeMo
提供專門工具(如 NeMo Customizer 和 Curator)來簡化模型定制過程,並支持企業級應用的微調和領域對齊。此外,它還支持檢索增強生成(RAG),將模型與私有數據連接,提升上下文相關性。 - 其他框架
Hugging Face 等框架提供了預訓練模型和微調功能,但在企業特定需求的整合(如 RAG)方面可能需要更多額外開發。
4. 部署靈活性
- NVIDIA NeMo
支持雲端(如 Google Cloud、AWS)、數據中心和邊緣設備上的部署,並且與 NVIDIA Riva 等生產環境優化工具無縫整合。 - 其他框架
雖然 Hugging Face 和 TensorFlow 等也支持多種部署選項,但它們可能缺乏像 NVIDIA 硬體這樣深度優化的基礎設施支援。
5. 安全性與企業功能
- NVIDIA NeMo
提供專門的安全工具(如 NeMo Guardrails),確保生成內容符合企業規範。此外,其 API 穩定性和高效能使其成為企業採用生成式 AI 的首選。 - 其他框架
一些框架缺乏內建的安全功能,需要額外開發來滿足企業需求。
NVIDIA NeMo 在性能、多模態支援、模型定制、部署靈活性和安全性方面表現出色,特別適合需要大規模生成式 AI 解決方案的企業。相比之下,其他框架雖然在小型應用或學術研究中可能更易於上手,但在處理超大規模模型或提供完整端到端解決方案時,NeMo 更具競爭力。
NVIDIA NeMo 的主要應用場景
NVIDIA NeMo 是一個專為生成式 AI 設計的端到端框架,能夠支持多種應用場景,涵蓋語言處理、語音 AI、多模態模型等領域。以下是其主要應用場景的概述:
1. 自然語言處理(NLP)與大型語言模型(LLMs)
- 對話式 AI:用於構建智能聊天機器人和虛擬助手,能夠理解複雜查詢並提供自然且準確的回應,提升客戶服務體驗。
- 內容生成:協助創建高質量內容,例如文章、報告和創意寫作,適用於行銷、培訓及企業內部使用。
- 翻譯服務:改進自動翻譯工具的準確性和流暢性。
- 情感分析:分析客戶反饋和社交媒體數據,以評估公眾意見和情緒。
- 文檔處理:加速從文檔中提取數據的過程,用於法律文件或醫療記錄的分析。
2. 語音 AI
- 自動語音識別(ASR):將語音轉換為文本,用於智能助理、客服系統等應用。
- 文本轉語音(TTS):生成自然語音輸出,用於數位人類、虛擬角色和語音導航系統。
- 多語言支持:支持多種語言的語音處理,適合全球化應用場景。
3. 多模態生成式 AI
- 支持結合文本、圖像和視頻數據的多模態模型,用於視覺問答系統、視頻內容分析等。
- 例如,NeMo 可用於視頻分析和生成,或在醫療影像中輔助診斷。
4. 檢索增強生成(RAG)
- NeMo Retriever 提供高效的信息檢索功能,通過檢索增強生成技術將模型與企業數據庫連接。這使得 AI 能夠基於上下文提供更準確的回應,用於知識管理、搜索引擎優化等。
5. 行業特定應用
- 醫療健康:支持醫療診斷輔助、患者記錄摘要以及醫學研究中的數據分析。
- 金融服務:增強欺詐檢測、自動化報告生成以及客戶互動效率。
- 零售與電子商務:提供個性化推薦系統和優化客戶購物體驗。
- 製造與網絡運營:改進供應鏈管理及網絡運營效率。
6. 內容創建與數據生成
- NeMo 支持合成數據生成(Synthetic Data Generation),可用於增強訓練數據集的多樣性,提升模型的穩健性。例如,在生物分子設計或信用卡交易分析中生成合成數據。
7. 安全與合規性保障
- NeMo Guardrails 提供內容安全功能,確保生成式 AI 的回應符合企業規範,防止不當或有害內容的產生。

NVIDIA NeMo 的靈活性和模組化設計,使其能夠滿足多種行業需求。從對話式 AI 和語音應用到多模態模型與行業特定解決方案,NeMo 為企業提供了一個強大且可擴展的平台來實現生成式 AI 的潛力。
NVIDIA NeMo 能否與現有的 AI 系統整合
NVIDIA NeMo 的整合能力
NVIDIA NeMo 可以無縫整合到現有的 AI 系統中,為企業和開發者提供靈活且強大的生成式 AI 解決方案。以下是其整合能力的關鍵方面:
1. 與現有 AI 基礎架構的兼容性
- 雲端和本地部署:NeMo 支援在多種環境中運行,包括 Google Cloud、AWS、Microsoft Azure 等雲端平台,以及企業內部的本地數據中心。
- NVIDIA NIM 微服務:NeMo 提供一組微服務(如 NeMo Retriever 和 NeMo Guardrails),可以輕鬆與現有應用集成,實現安全性增強和數據檢索功能。
2. 與第三方工具的整合
- 開源工具和框架:NeMo 與 PyTorch Lightning 深度集成,並支持 Hugging Face 預訓練模型,讓開發者能夠利用現有的生態系統資源。
- 觀測與優化工具:例如,Weights & Biases 和 Fiddler AI Observability 平台可以與 NeMo Guardrails 集成,用於監控和優化生成式 AI 應用。
3. 支援多種應用場景
- 檢索增強生成(RAG):NeMo Retriever 能夠將模型與企業專有數據連接,實現上下文相關的回應,適用於知識管理和業務洞察。
- 安全與合規性:NeMo Guardrails 提供靈活的安全框架,確保生成式 AI 系統符合企業政策和價值觀,可用於客戶交互、內容過濾等場景。
4. 模型定制與微調
- 預訓練模型支持:NeMo 支援多種大型語言模型(如 GPT、BERT、Llama 2)以及多模態模型(如 CLIP 和 Stable Diffusion),並提供簡化的微調工具(如 NeMo Customizer),使其能夠快速適應特定行業需求。
- 分佈式訓練能力:利用 NVIDIA 的 GPU 資源,NeMo 能夠高效處理大規模模型的訓練和推論,並支持跨多節點、多 GPU 的擴展。
5. 行業實例
- 企業應用:如 Amdocs 和 Cerence AI,利用 NeMo Guardrails 增強客戶交互的安全性和準確性。
- 設計與研發:Cadence 將 NeMo 整合到其設計流程中,用於生成式設計和數據檢索,同時保護敏感信息。
- 諮詢服務:Deloitte 和 Wipro 等公司使用 NeMo 開發高效能生成式 AI 解決方案,以滿足企業需求。
使用 NVIDIA NeMo 構建大型語言模型(LLMs)的主要優勢
NVIDIA NeMo 是一個專為大型語言模型(LLMs)設計的端到端平台,提供多項技術優勢,顯著提升模型的訓練效率、性能和應用靈活性。以下是使用 NeMo 構建 LLMs 的主要好處:
1. 高效的訓練與推論
- 加速訓練速度:NeMo 提供多種並行化技術(如數據並行、張量並行和流水線並行),使得訓練速度比傳統方法快 20%-30%。例如,使用 NeMo 訓練 175 億參數的 GPT-3 模型時,僅需 24 天即可完成,而不需要數月的時間。
- 混合精度訓練:支持 FP32、FP16、BF16 和 TransformerEngine/FP8 等多種精度選項,通過 NVIDIA Tensor Cores 提升訓練速度,同時保持高準確性。
- 推論性能優化:與 NVIDIA Triton Inference Server 集成,實現低延遲、高吞吐量的推論,適用於大規模部署。
2. 模型定制與靈活性
- 快速定制模型:NeMo 支持基於預訓練模型進行微調或提示學習(Prompt Learning),能在數分鐘到數小時內完成模型定制,而無需從零開始訓練。
- 支持多種架構創新:除了 Transformer 模型外,NeMo 還支持混合狀態空間模型(Hybrid State Space Models, SSMs)及其與 Transformer 的結合,為開發者提供更多創新選擇。
- 多語言支持:內建多語言模型,包括中文等,適用於全球化應用場景。
3. 可擴展性與分佈式計算
- 多 GPU 和多節點支持:NeMo 利用分佈式計算技術,能夠高效處理超大規模模型(如超過 1 兆參數的 GPT 模型),顯著縮短訓練時間。
- 資源最佳化:NeMo 提供自動化超參數調整工具,可根據硬體資源和性能需求自動配置最佳訓練和推論參數,進一步提升效率。
4. 簡化的開發流程
- 模組化設計:NeMo 提供神經模組(Neural Modules)作為邏輯構建塊,用於快速構建和調試 AI 應用。這種方法提高了開發效率和模型重用性。
- 預訓練模型庫:通過 NVIDIA GPU Cloud (NGC),NeMo 提供大量經過優化的預訓練模型,可直接用於自然語言處理、語音識別等應用,加速開發進程。
5. 強大的企業級功能
- 安全與合規性保障:NeMo Guardrails 確保生成式 AI 系統符合企業政策,防止生成不當內容,適合高要求的企業環境。
- 上下文感知應用:利用 NeMo Retriever 技術,可以將 LLM 與企業內部知識庫連接,實現上下文相關的回應和洞察分析。
NVIDIA NeMo 為大型語言模型提供了全面且高效的解決方案,其在性能、靈活性和可擴展性方面的優勢,使其成為企業和研究機構構建 LLMs 的首選工具。無論是快速定制模型、加速訓練速度還是簡化部署流程,NeMo 都能顯著降低開發成本並提升生產力。
NVIDIA NeMo 的超參數工具 (hyperparameter tool) 如何優化模型訓練
NVIDIA NeMo 的超參數工具(如 Auto Configurator)專為大型語言模型(LLMs)的高效訓練設計,通過自動化和優化關鍵參數的選擇,顯著提升訓練效率和性能。以下是其運作方式及優化方法的詳細說明:
1. 自動化超參數搜索
- 核心超參數的優化
Auto Configurator 專注於影響訓練吞吐量的四大關鍵超參數:- 張量並行(Tensor Parallelism, TP)
- 流水線並行(Pipeline Parallelism, PP)
- 上下文並行(Context Parallelism, CP)
- 專家並行(Expert Parallelism, EP)
此外,它還調整微批次大小(Micro Batch Size, MBS)、激活檢查點層數(Activation Checkpointing Layers, ActCkpt),以及全局批次大小(Global Batch Size, GBS),以實現最佳性能。
- 候選配置生成
工具通過啟發式方法生成多組候選配置,並進行網格搜索以找到最適合的配置。這些候選配置以 NeMo 格式提供,用戶可直接運行最有潛力的配置進行測試。
2. 訓練時間與資源估算
- 模型大小建議
根據硬體資源(如 GPU 數量、TFLOPS 性能)、訓練時間限制和數據集規模,Auto Configurator 能夠推薦適合的模型大小。例如,在 20 個 NVIDIA DGX 節點上,若希望在 5 天內完成訓練,工具可能建議使用一個 50 億參數的 GPT 模型。 - 訓練時間預測
工具基於輸入的數據集和超參數,估算模型的訓練時間,以便用戶更好地規劃資源和時間。
3. 訓練吞吐量優化
- 性能提升技術
NeMo 使用選擇性激活重計算(Selective Activation Recomputation)和序列並行化(Sequence Parallelism)等技術,顯著減少重複計算次數,從而提升吞吐量。在內部測試中,這些技術使 GPT-3 模型的訓練吞吐量提高了 20%-30%。 - 混合精度支持
支持 bfloat16 和 FP16 混合精度,加速計算同時降低內存使用。這對於處理大規模模型尤其重要。
4. 簡化工作流程
- 基礎配置生成
Auto Configurator 可自動生成符合 NeMo 格式的基礎配置文件,用戶只需進一步調整或直接使用即可開始訓練。 - 多次實驗管理
通過集成 Hydra Multi-Run 和 PyTorch Lightning,NeMo 提供統一的實驗管理工具,用於執行多組超參數搜索,同時記錄結果以便分析。
NVIDIA NeMo 的超參數工具通過自動化搜索和優化關鍵參數,大幅提升了大型語言模型的訓練效率。它不僅減少了手動調整的工作量,還能根據硬體資源和應用需求提供最佳配置建議,使得 LLMs 的開發更加高效且可控。
NVIDIA NeMo 的 Auto Configurator 如何根據硬體限制推薦模型大小
NVIDIA NeMo 的 Auto Configurator 工具能根據硬體資源和訓練條件,推薦適合的模型大小,從而最大化資源利用並優化訓練效率。以下是其推薦模型大小的工作原理與方法:
1. 依據硬體和訓練參數進行計算
Auto Configurator 使用以下關鍵輸入參數來計算模型大小:
- GPU 數量:可用的 GPU 節點數量,例如 NVIDIA DGX 系統。
- 每個 GPU 的 TFLOPS 性能:例如,A100 GPU 的峰值性能約為 140 TFLOPS。
- 訓練時間限制:用戶提供的最大訓練時間(如 5 天)。
- 訓練所需的標記數量(Tokens):模型需要處理的標記數量(如 1000 億標記)。
根據這些參數,Auto Configurator 計算出在指定硬體和時間內可以完成訓練的最佳模型大小。例如,在 20 個 DGX 節點(80GB GPU)上進行 5 天的訓練,工具可能建議使用一個 50 億參數的 GPT 模型。
2. 基於性能推估進行建議
- 時間與資源預估
Auto Configurator 根據輸入參數模擬訓練過程,估算完成所需的時間和資源。例如,它會計算每個 GPU 在指定條件下處理標記的速度,並推導出整體訓練所需的時間。 - 實際案例
如果用戶希望在 32 個 GPU 上訓練一個處理 1000 億標記的模型,工具可能建議一個 24.2 億參數的模型,並估算需要 50 天完成訓練。
3. 自動生成基礎配置
- Auto Configurator 在推薦模型大小後,會生成一個基礎配置文件(Base Config)。該文件包含初始超參數設置,但尚未經過優化。
- 用戶可以直接使用此配置文件開始訓練,也可進一步進行超參數搜索以提升性能。
4. 靈活適配多種硬體
- 支援多種硬體環境,包括 NVIDIA DGX 節點、A100 GPU 和其他高性能計算設備。
- 即使硬體資源有限(如使用 40GB GPU),Auto Configurator 仍能調整推薦結果以適應硬體限制。
NVIDIA NeMo 的 Auto Configurator 通過分析硬體資源、TFLOPS 性能、訓練時間和標記需求,自動推薦適合的模型大小。這不僅簡化了用戶配置大型語言模型的流程,也最大化了硬體利用率,同時確保在給定條件下達到最佳性能。

總結:NVIDIA NeMo 為生成式 AI 提供全方位動能
NVIDIA NeMo 為開發者與企業提供了資料準備、模型訓練、微調、評估、檢索及部署的一站式解決方案。它不僅涵蓋強大的工具與預訓練模型,也整合了多層防護與高效推論環境,讓生成式 AI 的導入更加安全可靠。對於想在雲端、資料中心或邊緣裝置上構建對話式應用的組織而言,NVIDIA NeMo 可說是不可或缺的核心利器。
如欲進一步瞭解或開始使用 NVIDIA NeMo,建議前往官方網站或相關資源頁面,並善用其完整工具鏈,以充分釋放生成式 AI 的潛力,為你的企業或專案帶來高效且創新的發展。祝你在 NVIDIA NeMo 的開發旅程中一切順利,打造出令人驚豔的 AI 服務與應用!
Learn more
- Nvidia - Tenten | AI、科技、新創快訊|解鎖人工智慧的未來
- NVIDIA NeMo:您的生成式 AI 開發利器
- NVIDIA Nim:快速部署生成式 AI 的新選擇,從開發到上線只需五分鐘
- NVIDIA NIM:釋放 AI 模型潛力的微服務
- NVIDIA DLSS 4:不只多幀生成,而是 GPU 技術的全面進化
- NVIDIA Reflex 2 與全新 Frame Warp 技術:重新定義遊戲延遲與反應速度
- Nvidia RTX Remix 的未來:不只止於畫面升級
- 秒懂 RTX Mega Geometry:遊戲與創作的未來?
- NVIDIA RTX 50 系列效能解密:該升級了嗎? 還是再等等?
- 黃仁勳談AI晶片、機器人與未來
- Nvidia Project DIGITS:桌面AI超級電腦的革命進化
常見問題 (FAQ)
1. 什麼是 NVIDIA NeMo?
NVIDIA NeMo 是 NVIDIA 推出的一套開源工具包,專為自然語言處理(NLP)、語音及文字轉語音(TTS)等生成式 AI 應用設計,提供資料準備、模型訓練、微調以及安全部署等完整解決方案。
2. NVIDIA NeMo 的核心功能有哪些?
NVIDIA NeMo 的核心功能包含以下幾個部分:
- Nemo Curator:快速準備與生成高品質的大規模資料集。
- Nemo Customizer:進行大型語言模型的微調與對齊。
- Nemo Evaluator:評估生成式 AI 模型的表現。
- NVIDIA Retrieval:連結商業數據以提升模型準確性。
- Nemo Guardrails:確保生成式 AI 符合安全與合規需求。
3. NVIDIA NeMo 有哪些主要應用場景?
NVIDIA NeMo 被廣泛應用於以下場景:
- 語音辨識與合成(如智慧客服)。
- 自然語言理解(如聊天機器人與情感分析)。
- 生成式應用(如新聞摘要與機器翻譯)。
- 多種產業(如醫療、金融與電商)的垂直解決方案。
4. NVIDIA NeMo 的部署方式有哪些優勢?
NVIDIA NeMo 支援跨環境彈性部署,可運行於公有雲、私有雲、資料中心及邊緣裝置。此外,它具備生產就緒與企業級穩定性,提供技術支持與安全保障,加速開發週期並降低專案成本。
5. NeMo 提供哪些技術來優化大型語言模型的訓練?
NVIDIA NeMo 採用 Megatron 框架進行大規模 Transformer 模型的訓練,可管理含多達數兆參數的模型,從而輕鬆構建可媲美 GPT-4 等級的先進生成式 AI。