NVIDIA 推出「領先業界」的開源 Llama-3.1-Nemotron-70B-Instruct 大型語言模型
NVIDIA 決定發布業界最重量級的「Llama-3.1-Nemotron-70B-Instruct」大型語言模型,超越了 OpenAI 的 GPT-4o 和 Anthropic 的 Claude 3.5 Sonnet。
NVIDIA 致力主導 AI 領域,推出全新大型語言模型,專注於優化使用者回應
Nvidia正在以前所未有的方式推動 AI 領域創新,在顯然已經主導「AI 硬體」領域之後,該公司現正與 Meta 合作,展示其在開源大型語言模型方面的實力。來自 NVIDIA 的最新 Llama-3.1-Nemotron-70B-Instruct 大型語言模型尚未受到主流媒體廣泛報導,但根據初步可得的資訊和基準測試,Nvidia的這個新型大型語言模型可能成為業界領先者。
NVIDIA 表示,Llama-3.1-Nemotron-70B-Instruct 大型語言模型專門設計用於使 AI 回應更加具體且符合人類偏好,特別是在事實準確性和連貫問題解決方面。該模型據稱是基於 Meta 的 Llama-3.1-70B-Instruct Base 訓練而成,後者同樣是 Meta 專為 700 億參數設計的作品。透過 NVIDIA 的微調,Llama-3.1-Nemotron-70B-Instruct 特別針對「SteerLM 迴歸獎勵建模」。
SteerLM Llama-2 是一個基於開源 Llama-2 架構的 130 億參數生成語言模型。它已使用 NVIDIA 開發的 SteerLM 方法進行定制,允許使用者在推理過程中控制模型輸出。
SteerLM 實現的關鍵功能:
- 透過指定所需的屬性(如品質、有用性和毒性)來動態控制反應。
- 與微調和引導等 RLHF 技術相比,簡化了訓練。
模型架構和訓練
SteerLM方法涉及以下關鍵步驟:
- 在人工註釋資料上訓練屬性預測模型以評估反應品質。
- 使用此模型來註釋不同的資料集並豐富訓練資料。
- 執行條件微調以使回應與指定的屬性組合一致。
- (可選)透過模型採樣和進一步微調進行引導訓練。
SteerLM Llama-2 在 Llama-2 架構之上應用了此技術。它根據互聯網規模的資料進行預訓練,然後使用OASST和HH-RLHF資料進行客製化。
更多關於 SteerLM
- Model Alignment by SteerLM Method — NVIDIA NeMo Framework User Guide latest documentation
- Announcing NVIDIA SteerLM: A Simple and Practical Technique to Customize LLMs During Inference | NVIDIA Technical Blog
- nvidia/SteerLM-llama2-13B · 抱臉 — nvidia/SteerLM-llama2-13B · Hugging Face
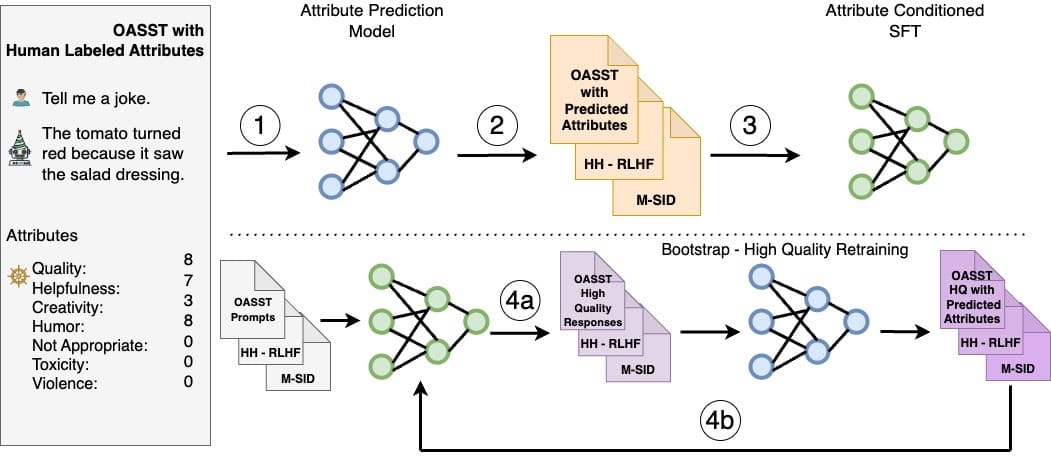
此文章涉及一些技術性內容,但考慮到這樣的傑作,確實值得深入探討。SteerLM 迴歸獎勵建模涉及定義一個獎勵函數,通過使用迴歸模型來優化數據集以生成更清晰的回應,藉此引導大型語言模型的學習過程。這使得數據質量和模型複雜性得到更好的優化,最終使 NVIDIA 能夠生成更貼近用戶需求的回應。
有趣的是,根據 HuggingFace 上的 Llama-3.1-Nemotron-70B-Instruct 大型語言模型卡片顯示,這個特定模型成功解決了傳統 AI 模型無法解決的「草莓」問題,即計算單詞中「R」的數量。這還不是唯一的成就,接下來的細節可能會讓讀者更加驚訝。NVIDIA 的 Llama-3.1-Nemotron-70B-Instruct 大型語言模型在多個基準測試中取得領先排名,特別是在 Arena Hard(一個用於指令調校大型語言模型的自動評估工具)中表現出色,以下是整體評分的對比:
| 模型 | Arena Hard | AlpacaEval | MT-Bench | 平均回應長度 |
|---|---|---|---|---|
| 詳情 | (95% CI) | 2 LC (SE) | (GPT-4-Turbo) | (MT-Bench 字元數) |
| Llama-3.1-Nemotron-70B-Instruct | 85.0 (-1.5, 1.5) | 57.6 (1.65) | 8.98 | 2199.8 |
| Llama-3.1-70B-Instruct | 55.7 (-2.9, 2.7) | 38.1 (0.90) | 8.22 | 1728.6 |
| Llama-3.1-405B-Instruct | 69.3 (-2.4, 2.2) | 39.3 (1.43) | 8.49 | 1664.7 |
| Claude-3-5-Sonnet-20240620 | 79.2 (-1.9, 1.7) | 52.4 (1.47) | 8.81 | 1619.9 |
| GPT-4o-2024-05-13 | 79.3 (-2.1, 2.0) | 57.5 (1.47) | 8.74 | 1752.2 |
暫時不用過分關注具體數字,但值得注意的關鍵點是,Llama-3.1-Nemotron-70B-Instruct 成功超越了業界主流的大型語言模型,如 OpenAI 的 GPT-4o,這是一個重要里程碑,考慮到 NVIDIA 的微調對 Llama-3.1-70B-Instruct Base 產生了多麼巨大的影響。
我們尚未看到該大型語言模型在特定情況下的表現,如複雜編碼任務或推理focused問題,但初步基準測試確實顯示 NVIDIA 的最新大型語言模型裝備完善。
如果你急於訪問 Llama-3.1-Nemotron-70B-Instruct 大型語言模型,你可以從 NVIDIA 的 NIM平台獲取,或者在 HuggingFace 上的相容版本試用。總的來說,感覺得出 Nvidia 加入 LLM 模型訓練,並打算透過開放原始碼加速發展。
NVIDIA Llama-3.1-Nemotron-70B-Instruct - FAQ
- 什麼是 NVIDIA Llama-3.1-Nemotron-70B-Instruct? 這是 NVIDIA 推出的一款開源大型語言模型,基於 Meta 的 Llama-3.1-70B-Instruct Base 訓練而成,並經過 NVIDIA 的 SteerLM 技術微調,旨在提升 AI 回應的準確性、一致性和符合人類偏好。
- SteerLM 技術是什麼? SteerLM 是一種讓使用者在推理過程中控制模型輸出的技術,透過指定所需的屬性(如品質、有用性和毒性)來動態控制回應,並簡化訓練過程。
- Llama-3.1-Nemotron-70B-Instruct 的效能如何? 根據初步基準測試,它在 Arena Hard 等評測中表現出色,超越了 OpenAI 的 GPT-4o 和 Anthropic 的 Claude 3.5 Sonnet 等業界領先的大型語言模型。尤其在「草莓」問題(計算單詞中「R」的數量)上取得了突破。
- 如何取得 Llama-3.1-Nemotron-70B-Instruct? 可以透過 NVIDIA 的 NIM 平台或 HuggingFace 上的相容版本取得。
- Llama-3.1-Nemotron-70B-Instruct 的主要優勢是什麼? 它專注於優化使用者回應,使其更具體、事實準確,並更符合人類偏好。透過 SteerLM 技術,它能夠更好地控制模型輸出,並在多項基準測試中展現出領先的性能。