

揭秘DeepSeek創始人梁文鋒的背景與經歷!從幻方量化到千億私募,他如何帶領DeepSeek在AI領域崛起?
在當前量化投資與人工智能領域,「梁文鋒」無疑是一個備受矚目的名字。他既是幻方量化的創始人,也在 2023 年成立了深度求索(DeepSeek),吸引眾多業界人士關注。本文將帶你回顧梁文鋒的成長歷程,並探討他如何憑藉「AI+量化」的獨特思維,在短短數年之間締造出讓人嘆為觀止的成就。
從數學愛好者到量化先行者
梁文鋒1985 年出生於廣東湛江,父親是一位小學老師。自幼,他就對數學模型和演算法產生極大興趣。2002 年,年僅 17 歲的梁文鋒考入浙江大學電子信息工程專業,並在之後攻讀了信號與通信工程相關的研究生學位。在學術期間,他專注研究機器視覺,發表了關於 PTZ 攝影機目標追蹤演算法的論文。
2008 年全球金融危機引發市場震盪,但梁文鋒卻敏銳地看到了量化投資的機遇,開始蒐集市場行情、宏觀經濟以及金融數據,並嘗試將機器學習應用於自動化交易策略。儘管當時也曾傳出大疆創始人汪滔曾邀請他共同創業,但梁文鋒堅定地選擇了「AI 改變世界」的道路。

創業初期:從小規模到破局騰飛
杭州雅克比的起點
2013 年,28 歲的梁文鋒與浙大同學徐進共同創辦「杭州雅克比投資管理有限公司」,這個小小的投資管理公司為日後的金融版圖奠定了基礎。
幻方量化:正式啟航
2015 年,中證 500 股指期貨上市,量化私募正式進入 2.0 時代。當年 6 月,正值中國股市「股災」肆虐,卻也成為梁文鋒和徐進的重大機遇。他們在杭州成立了「杭州幻方科技有限公司」,後更名為「浙江九章資產管理有限公司」,正式開啟以數學與人工智能驅動的量化投資。雖然那一年市場動盪,他們依舊仰賴高頻交易策略站穩腳跟,並在 10 月與 12 月陸續成立多只基金產品,展示了出色的募資能力。
2016 年初,梁文鋒與徐進又於寧波成立「幻方量化投資管理合夥企業」,並於同年成功加入中國證券投資基金業協會。10 月,幻方量化推出首個 AI 模型並首次使用 GPU 進行深度學習運算,此時公司資產管理規模已達 10 億元人民幣。

AI 加持:幻方的飛躍與挑戰
全面導入 AI 策略
2017 年,梁文鋒加大在 AI 演算法與軟硬體研發的投資。至當年年底,幾乎所有量化策略都已切換為深度學習模型,資金管理規模也順利擴張至 30 億元。2018 年,幻方量化首次榮獲「金牛獎」,也確立了以 AI 為核心的長期發展路線。然而,AI 訓練所需的龐大算力逐漸成為發展瓶頸。
「螢火一號」與百億私募
為解決算力不足問題,2019 年,梁文鋒投入 2 億元自建深度學習訓練平臺「螢火一號」,搭載 1100 張 GPU。也在這一年,幻方量化管理資金突破百億元。同時,幻方資本於香港成立,取得資產管理的「九號牌」,全球佈局正式展開。
2019 年底,梁文鋒在金牛獎頒獎禮上的演講引發關注。他直言,量化投資與非量化之間的差異,關鍵在於「伺服器取代了傳統基金經理人的角色」,並強調高昂的管理費用與投資人高期望之間的壓力,也使量化私募必須不斷精進策略。

跨入千億與業績波動
翻越千億大關
2021 年初,「螢火二號」正式上馬,投入 10 億元升級算力。同年 2 月,梁文鋒為《征服市場的人:西蒙斯傳》寫序,表示其在工作中遇到困難時,始終被量化傳奇詹姆斯·西蒙斯「一定有辦法對價格建模」的箴言所鼓舞。到了 2021 年 8 月,幻方量化管理規模突破千億,與九坤投資、明汯投資、靈均投資並稱「量化私募四大天王」。

回撤與縮規
然而,同年 11 月起,幻方量化業績震盪,迫使其暫停募集,並在年底時發佈致投資者公開信,表示回撤達到歷史最大值。據稱,AI 模型在買賣時機的拿捏上出現失誤,造成短期績效不如預期。之後公司主動縮減上百億元的管理規模,從接近千億降至八百多億。投資人情緒波動也相當劇烈,甚至有股東在網路上表達對高管的不滿。儘管如此,梁文鋒仍堅持不斷優化演算法與風控機制,期待走出短期低潮。
2022 年,幻方量化內部有匿名人士以「一隻平凡的小豬」名義慈善捐款高達 1.38 億元人民幣,涵蓋白血病救助、鄉村工匠、兒童大病救助與聽障兒童支持等多個公益項目。外界普遍猜測捐款人就是梁文鋒,但本人並未公開證實。
再創新局:深度求索(DeepSeek)崛起
進軍通用人工智能
2023 年,38 歲的梁文鋒決定跨足通用人工智能(AGI),於 7 月在杭州成立「深度求索人工智能基礎技術研究有限公司」(DeepSeek)。這個聚焦大模型與基礎研究的新創團隊,聚集了來自清華、北大、北郵、北航等國內頂尖學校的博士與應屆生,顯示梁文鋒對於「年輕化、純本土化」的堅定選擇。團隊不聘用高年資專家,而是深信創造力與熱情才是推動技術突破的關鍵。
DeepSeek - V2 與超低 API 價格
2024 年 5 月,DeepSeek 推出語言模型 DeepSeek - V2,並以「每百萬 token 輸入 1 元、輸出 2 元」的親民定價震驚業界,被譽為「AI 界的拼多多」,也迫使其他大廠如字節跳動、阿里巴巴、百度、騰訊等相繼下調自家模型的收費。深度求索藉由此舉極大化了產品觸達率,並展現出「梁文鋒」獨到的策略眼光。
DeepSeek - V3:高性價比的巔峰之作
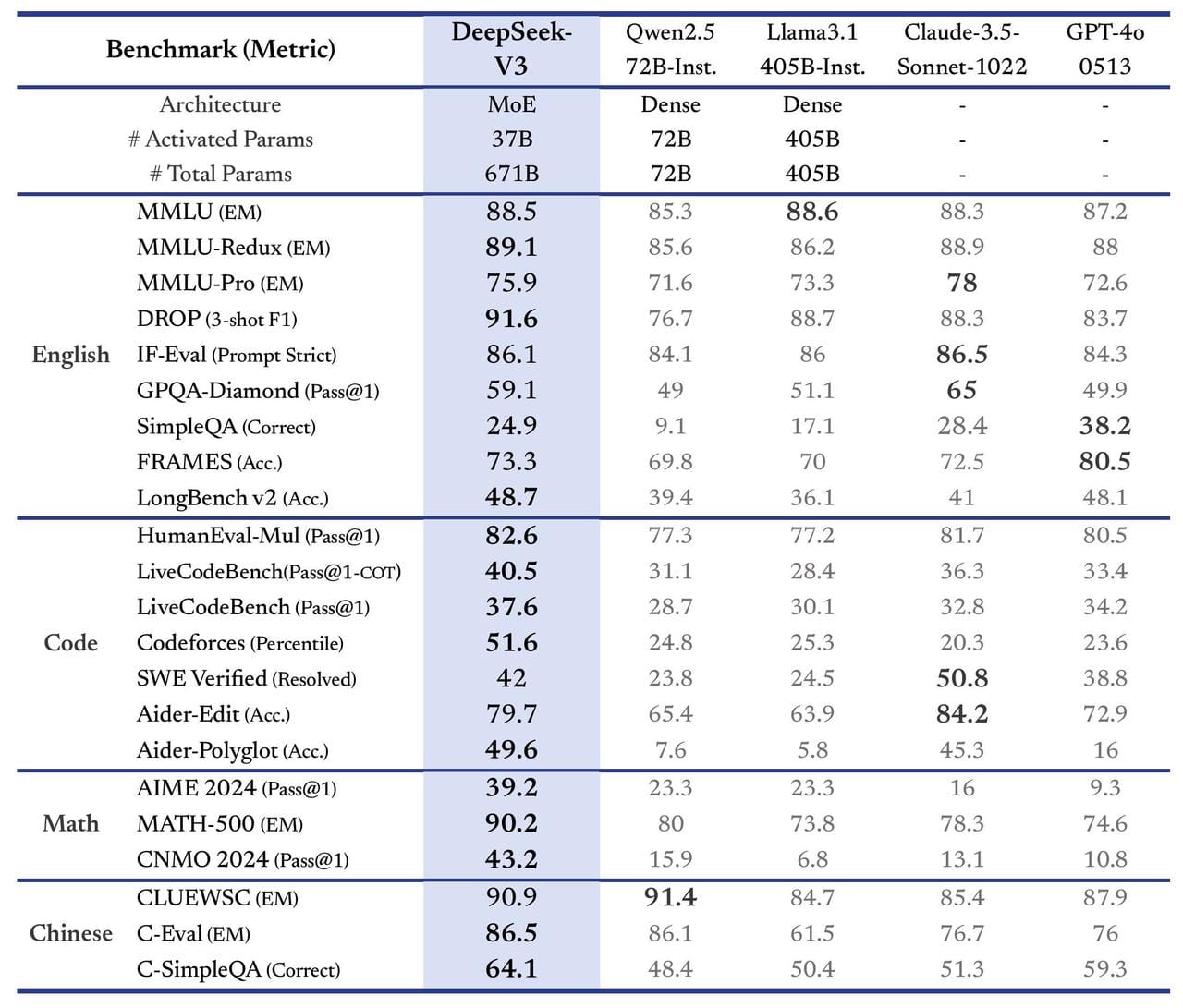
2024 年 12 月 26 日,DeepSeek - V3 正式發佈,並公開 53 頁技術論文。據官方數據,DeepSeek - V3 在多項測試中領先國內外眾多大模型。如在 MMLU(EM)測試中取得 88.5 分,超過 ChatGPT-4o 的 87.2 分;在 DROP 測試中更高達 91.6 分。更令人驚訝的是,其訓練成本僅約 557.6 萬美元,不到 ChatGPT-4o 所花費成本的十分之一,成為大模型領域罕見的「高性能、高性價比」代表。
隨著 DeepSeek - V3 的推出,OpenAI 創始成員安德烈·卡帕西(Andrej Karpathy)也對這個僅 139 人的本土研發團隊表達讚賞。值得注意的是,DeepSeek 走的並非國際化菁英路線,而是選擇本土大學的新鮮人或畢業不久的年輕研究者,以扁平化管理與「自由創新」理念來激發活力。
DeepSeek API 定價與其他主流 LLM API 對比表
以下為 DeepSeek API 與其他主要 LLM API 的價格比較(單位:每百萬 tokens 成本),包含輸入與輸出費用:
| 供應商 | 模型 | 輸入價格(每百萬tokens) | 輸出價格(每百萬tokens) | 備註 |
|---|---|---|---|---|
| DeepSeek | DeepSeek R1 | $0.14 | $0.28 | 具競爭力定價,支援快取功能以降低長期成本 |
| DeepSeek Chat 8B | $0.20 | $0.60 | 專為對話任務設計 | |
| DeepSeek Chat 67B | $1.00 | $3.00 | 高效能模型,成本仍低於 GPT-4-turbo | |
| OpenAI | GPT-4 | $30.00 | $60.00 | 高階模型,適合需頂尖性能的應用場景 |
| GPT-3.5 Turbo | $0.50 | $1.50 | 中小型應用的經濟選擇 | |
| GPT-4 Turbo | $10.00 | $30.00 | GPT-4 的輕量版,效能略減但成本降低 | |
| Anthropic | Claude 3.5 Sonnet | $3.00 | $15.00 | 平衡成本與性能,適合大規模處理需求 |
| Claude 3 Haiku | $0.80 | $4.00 | 輕量級任務的實惠選項 | |
| Meta (LLaMA) | LLaMA 2 Chat (13B) | $0.75 | $1.00 | 需自行架設或依賴第三方API服務商,增加部署複雜度 |
| LLaMA 2 Chat (70B) | $1.95 | $2.56 | 更高參數量帶來成本提升 | |
| Cohere | Command R | $0.50 | $1.50 | 通用型模型,定價具競爭力 |
| Command R+ | $3.00 | $15.00 | 強化版模型,適用複雜任務 |
核心差異分析
- DeepSeek 成本優勢
- 相較 OpenAI 的 GPT-4 系列,DeepSeek 價格低 10 倍以上,尤其適合高用量需求。
- 高階模型 DeepSeek Chat 67B 的輸出成本僅為 GPT-4 Turbo 的 10%。
- OpenAI 高階定位
- GPT-4 系列維持最高定價($60/百萬輸出tokens),反映其技術領先地位。
- Anthropic 的平衡策略
- Claude Haiku 在輕量級模型中具價格競爭力,Sonnet 則針對企業級需求。
- 開源模型的隱形成本
- Meta 的 LLaMA 雖標價較低,但需額外投入基礎設施與維護成本。
- 應用場景建議
- 預算敏感型專案: 優先考慮 DeepSeek R1 或 Claude Haiku
- 高複雜度任務: 評估 DeepSeek Chat 67B 與 GPT-4 的性價比差異
- 可擴充架構: 需計算開源模型(如 LLaMA)的總持有成本(TCO)
後續發展:金融與 AI 的交匯
幻方量化的調整與未來
2024 年 10 月,幻方量化宣布將逐漸降低對沖產品的投資倉位至零,顯示「量化私募四大天王」之一的幻方正在重新規劃其策略。2025 年,幻方量化的資產管理規模已降至 300 億元以下,退出行業前六名。不過,即使面臨種種壓力,梁文鋒依舊透過幻方持續支持災區救助與慈善事業,也為自己在 AI 領域的研發提供相對穩定的資金來源。
技術驅動的堅持
對 梁文鋒 而言,金融從來不是終點,而是資本與技術的結合點。他在量化投資的成功,為自己積累了可持續投入 AI 基礎研究的實力。每一次創業,他都選擇在市場寒冬期著手佈局,從 2008 年金融危機、2015 年股市震盪,再到 2023 年後的 AI 大模型競爭,皆能逆勢而上,足見「梁文鋒」對技術趨勢與時局脈動的精准把握。
結語:以好奇心推進未來
在尚未滿 40 歲的年紀,梁文鋒已經締造出震撼業界的成就。無論是在量化私募領域踏入千億級別的幻方量化,還是以 DeepSeek 開創大模型低價高效的新模式,都展現了他對技術與創新的熱情。正如他所言,DeepSeek 更像是一場「好奇心驅動的學術探索」,而非純粹的商業逐利。面對未來,梁文鋒與 DeepSeek 極有可能持續突破 AI 領域的極限,為世界帶來更多令人驚豔的可能性。
FAQ
1. 梁文鋒是誰?
梁文鋒,1985 年出生於廣東湛江,是「DeepSeek」以及「幻方量化」的創始人。他憑藉人工智能與量化投資結合,創建了千億規模的私募基金,並在 AI 領域崛起。
2. DeepSeek 為什麼被稱為「AI 界的拼多多」?
DeepSeek 的 API 定價策略非常親民,例如 DeepSeek - V2 定價每百萬 tokens 輸入僅 1 元、輸出 2 元,相較於 OpenAI 的 GPT-4 系列低出 10 倍以上,極大降低了大模型的使用門檻。
3. DeepSeek - V3 有哪些突破?
DeepSeek - V3 在多項測試中展現卓越性能,例如在 MMLU 測試中取得 88.5 分,多項指標超越 ChatGPT-4o,且訓練成本僅 557.6 萬美元,是一個兼具高性能與高性價比的大模型。
4. 梁文鋒在 AI 領域的策略是什麼?
梁文鋒重視年輕化、本土化的創新團隊,不聘用高年資專家,將重心放在大模型與基礎研究。同時採用自由創新與扁平化管理,避免過多層級干擾創造力。
5. DeepSeek API 在市場上的競爭優勢是什麼?
DeepSeek API 在成本上有巨大優勢,例如高階模型 DeepSeek Chat 67B 的輸入與輸出成本遠低於 GPT-4 Turbo,適合高用量需求的應用場景。另外,DeepSeek 還具備高效能與快取功能,進一步降低長期成本。
延伸閱讀








