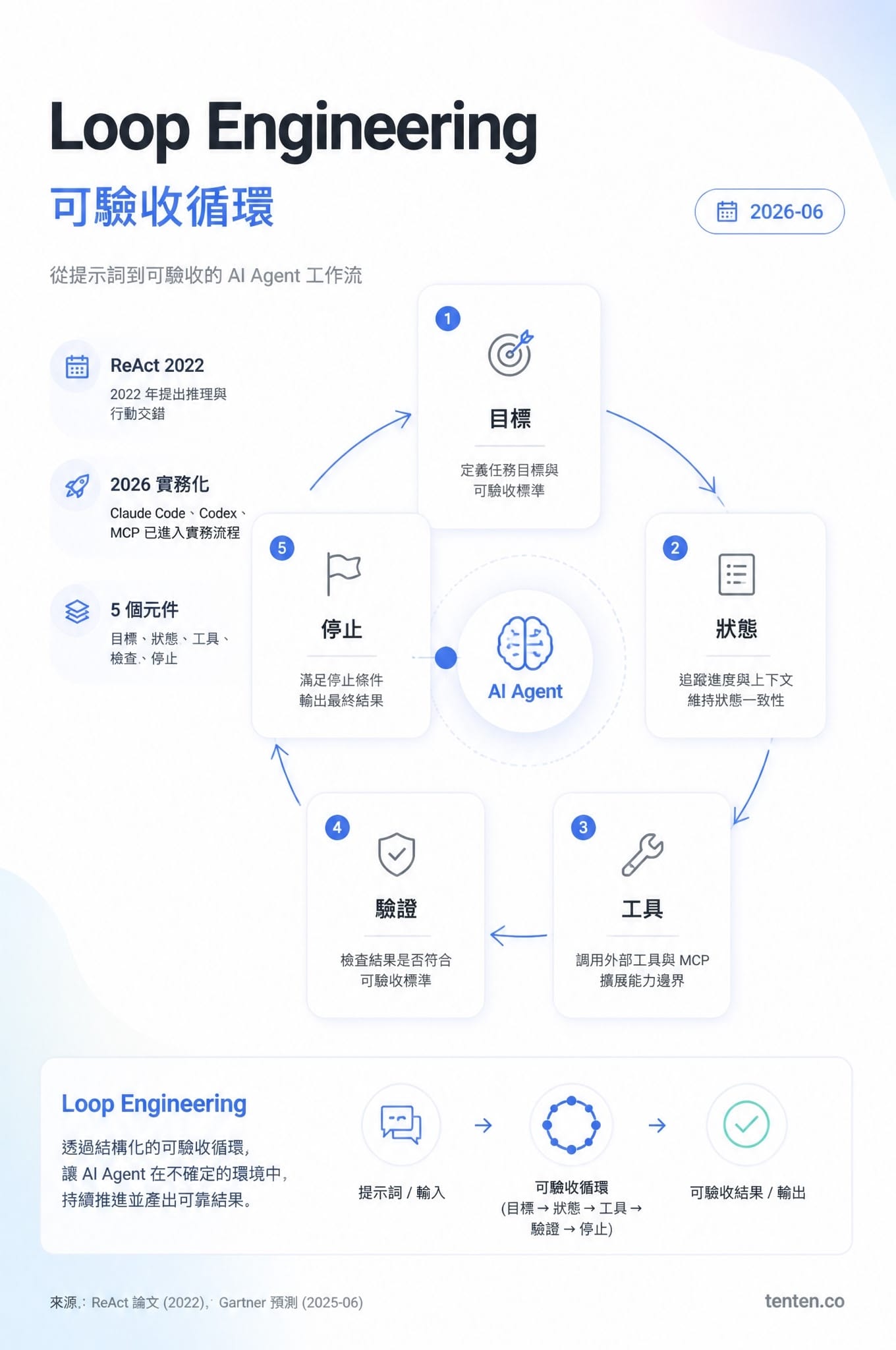
**Loop Engineering 是把 AI Agent 工作流從一次性提示詞,升級成會觀察、決策、行動、驗證的可驗收循環;截至 2026 年 6 月,這已經從研究概念進入 Claude Code、Codex、MCP 與 CI/CD 流程。**它適合重複、可驗、有明確商業價值的工作,不適合拿來自動化一切。真正的槓桿在兩端:人定義完成條件,人承擔最後責任。
先把 Loop 說清楚
Loop Engineering 的實務定義很簡單:你設計一個能持續推進工作的外層機制,不靠一輪一輪提醒 AI 該做什麼。這個機制會讀狀態、挑下一步、呼叫工具、檢查結果,再決定停止、重試、升級給人,或進入下一輪。
這個觀念並非憑空冒出來。2022 年 10 月,Shunyu Yao、Jeffrey Zhao、Dian Yu 等人在 ReAct: Synergizing Reasoning and Acting in Language Models 裡提出讓大型語言模型交錯產生推理軌跡與動作。Google Research 也把 ReAct 解釋為「推理影響內部狀態,動作取得外部觀察」的結構。今天工程團隊說的 loop,多半是在這個 observe-act-feedback 思路上,加上權限、狀態、預算、檢查者與人類閘門。
| 工作型態 | 典型做法 | 適用條件 | 退出條件 |
|---|---|---|---|
| 傳統流程自動化 | cron、RPA、固定腳本 | 步驟固定、輸入可預期 | 腳本成功或失敗 |
| AI 輔助 | 人下提示詞,AI 回答 | 目標清楚但路徑仍需人判斷 | 人覺得夠用 |
| Agent loop | AI 讀狀態、選工具、驗證結果 | 目標清楚,路徑可變 | 驗收清單通過或達到上限 |
| 雲端 routine / CI 觸發 | 排程或事件啟動 agent | 需要定期或事件驅動執行 | 成功、失敗、升級給人 |
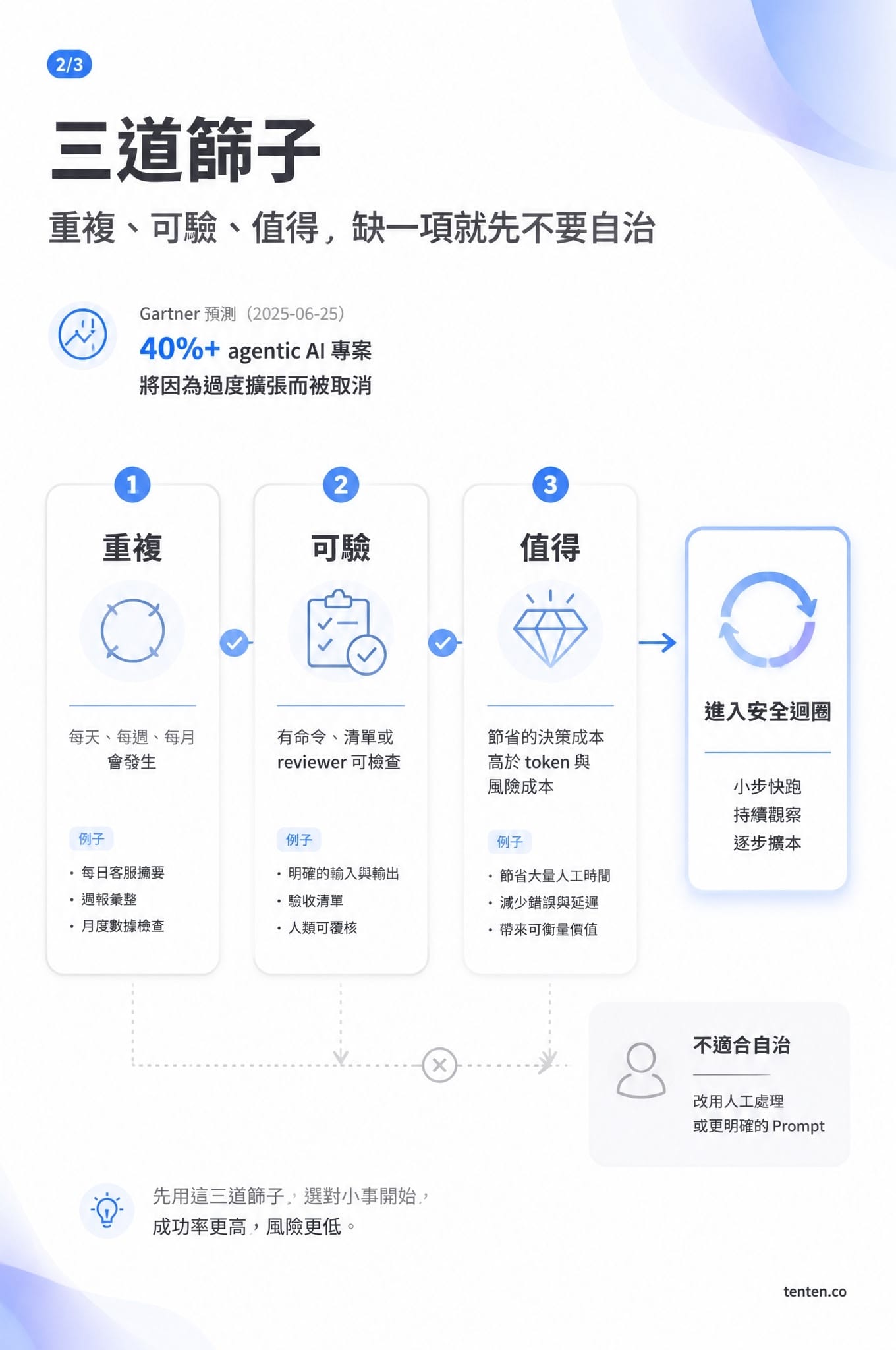
判斷一件事該不該做成 Loop
我會先問三個問題。
第一,它重複嗎?每天看 CI、每週整理競品價格、每月做報表,都有循環價值。一次性的策略判斷通常沒有。
第二,它可驗嗎?「把文案寫好」太抽象。「20 則貼文各自低於 150 字,不含 hashtag,且語氣符合品牌手冊」才是 agent 可以檢查的完成條件。
第三,它值得嗎?Gartner 在 2025 年 6 月預測,到 2027 年底,超過 40% 的 agentic AI 專案會因成本上升、價值不清或風險控管不足而被取消。這個數字提醒我們:loop 省下的是重複決策,不是判斷本身。
第一個可用 Loop:晨間維護循環
先從低風險、低權限的工作開始。以下模板是 Tenten 版示範,重點在結構,請先放到測試倉庫或非關鍵環境。

1. 把完成條件寫成可驗收清單
/goal 檢查 drafts/ 裡 12 則短文:
每則低於 150 字,
不含 hashtag,
保留原本檔名,
全部通過後停止,
最多 20 回合。
如果是工程工作,完成條件要交給命令與 reviewer。
/goal 讓 test/auth 全部通過,
npm run lint 無錯誤,
不改公開 API,
最多 8 回合。
2. 裝上心跳
# 會話內心跳:適合盯部署、等長任務跑完
/loop 10m 檢查 staging 部署狀態;部署完成後回報 URL 與錯誤摘要。
長期排程要放進 CI、桌面排程或雲端 routine。Anthropic 的 Claude Code routines 已經把排程、API 觸發、GitHub 事件與 MCP connectors 放進同一類工作模型;OpenAI 的 Codex CLI 則能在本機終端機讀取、修改並執行程式碼。選哪個工具次要,設計上限與證據才重要。
name: morning-triage
on:
schedule:
- cron: "0 1 * * 1-5"
workflow_dispatch:
jobs:
triage:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Run readonly agent triage
run: ./scripts/agent-triage.sh --readonly --limit 5
3. 把規則寫進 skill
---
name: daily-maintenance
description: 每個工作日讀取進度檔,整理昨夜 CI 失敗、新 issue、依賴警告;只起草低風險修正,其他升級給人。
---
## 1. 讀取進度
- 先讀 progress.md。
- 已完成的事項不要重做。
- 需要人的事項只補證據,不直接處理。
## 2. 找待辦
1. 昨夜失敗的 CI。
2. 超過 3 天未回覆的 issue。
3. 新增的依賴警告。
## 3. 處理規則
- 每次只處理一件事。
- 使用獨立 branch 或 worktree。
- 先起草最小改動,再交給只讀 reviewer。
## 4. 停止條件
- 最多 5 件。
- 任何公開 API、資料遷移、刪檔風險都升級給人。
- 通過測試與 reviewer 後才允許開 PR。
4. 做檢分離
---
name: readonly-reviewer
description: 對照驗收清單、測試輸出與 diff,只回 PASS 或 FAIL,不修改檔案。
tools: Read, Bash(npm test*), Bash(npm run lint*), Bash(git diff*)
---
1. 自己跑測試,不採信前一個 agent 的口頭結果。
2. 對照驗收清單讀 diff。
3. 找出公開行為改變、漏掉的邊界案例、安全風險。
輸出格式:
- PASS:列出實際驗證的命令與證據。
- FAIL:逐條列出原因與下一步。
Anthropic 的 Claude Code subagents 與 dynamic workflows 已經把「多個 agent 協作」做成產品層能力;OpenAI 的 Agents SDK + Codex guide 也把可審查的多 agent 工作流放進官方範例。這些能力好用,但也更容易燒 token。reviewer 要用在高風險或高價值的環節。
5. 用狀態檔保留記憶
# progress.md
## 已完成
- 2026-06-26:修正 auth token refresh 測試不穩,PR #142。
## 進行中
- 依賴警告:7 件已處理 3 件,image-lib 升版會改輸出格式。
## 需要人
- image-lib 安全修正牽涉公開格式,請維護者決定是否拆成 major release。
沒有狀態檔,循環常會像失憶的人,一直重新做第一步。狀態不該塞滿上下文。把穩定規則放 AGENTS.md、CLAUDE.md 或 skill,把短期進度放 progress.md。
六個場景:從工程到營運
| 場景 | 可交給 loop 的工作 | 驗收方式 | 升級給人的條件 |
|---|---|---|---|
| 工程維護 | CI 失敗分診、依賴升級、重複 bug 修復 | 測試、lint、diff 範圍 | 公開 API、資料遷移、安全風險 |
| 內容流程 | 粗想法變 hook、長文拆成多平台版本 | 字數、禁詞、品牌語氣檢查 | 涉及法律、醫療、投資承諾 |
| 監控研究 | 定價頁、changelog、競品訊號追蹤 | URL diff、資料時間戳 | 價格策略或合約調整 |
| 文件產製 | PDF 摘要、提案草稿、規格整理 | schema、連結、引用檢查 | 需承諾交期或報價 |
| 辦公支援 | 郵件摘要、客服工單分類 | 只讀摘要、明確分類 | 回覆、刪除、關閉工單 |
| 商業營運 | 續約風險、定價訊號、流失預警 | 指標門檻、資料來源 | 影響客戶關係或收入 |
我最保守的建議是先只讀。讓 agent 跑三到五天,只產出摘要與建議。當你開始相信它的判斷,再給它開 issue、開 PR 或更新文件的權限。刪除、部署、寄信、付款這類動作,先保留人類確認。
成本的主因是頻率
Loop 失控常由頻率造成,單次模型呼叫未必昂貴。一個 maker 加 reviewer 的小循環,如果每拍讀 4 萬 token、寫 6 千 token,工作日每天跑 5 次,月費可能還能接受;同樣的循環每 5 分鐘跑一次,成本會放大上百倍。真正要管的是拍數、停止條件與無進展偵測。
最低安全清單可以很短:
- 成功條件:完成長什麼樣。
- 上限:最多幾回合、幾分鐘、多少預算。
- 隔離:branch、worktree、沙盒或只讀權限。
- 檢查者:測試 runner、linter、schema validator 或 reviewer agent。
- 人類閘門:高風險事項停下來。
- 日誌:要能追查它做過什麼。
- 回報:夜裡出事也有人知道。
Model Context Protocol 讓 AI 應用能接外部工具與資料來源,這也是 loop 可以動手的原因。MCP server 可以暴露檔案、資料查詢、GitHub、Slack、行事曆等能力。權限邊界要跟 loop 一起設計,否則工具越多,風險越大。
FAQ
Loop Engineering 和 prompt engineering 有什麼差別?
Prompt engineering 重點在單次指令品質。Loop Engineering 重點在外層控制:狀態、工具、驗收、上限、檢查者與人類閘門。前者像寫一封清楚的委託信,後者像設計一條能反覆交付的工作線。
企業應該先從哪一種 loop 開始?
先從只讀、可驗、低風險的 loop 開始,例如 CI 摘要、PR 阻塞整理、競品頁面 diff、客服工單分類。這些工作有明確輸入與輸出,又不會直接影響客戶或帳務。
什麼工作不該做成 loop?
高度主觀、一次性、缺乏驗收條件、或錯了會立即造成金錢與法律風險的工作,都不該直接自治。策略、品牌、合約、醫療、投資與人事決策,需要人保留最後判斷。
Loop 需要用到 MCP 嗎?
不一定。簡單 loop 可以只讀本機檔案與命令列。當它需要查工單、讀 Slack、開 PR、更新 CRM 或呼叫內部 API,MCP 才變得重要。重點在工具權限與審計,連線數量只是次要考量。
權威引用
- ReAct: Synergizing Reasoning and Acting in Language Models
- Google Research — ReAct: Synergizing Reasoning and Acting in Language Models
- Claude Code Docs — How the agent loop works
- Claude Code Docs — Automate work with routines
- OpenAI Developers — Codex CLI
- Model Context Protocol — Introduction
- Gartner — Over 40% of Agentic AI Projects Will Be Canceled by End of 2027
- Mozilla Blog — The zero-days are numbered
Author Insight
大家想把 AI 放進流程,但常把「能跑」誤認成「能交付」。Loop Engineering 的價值在於逼團隊先說清楚驗收標準,再談工具。這會讓 AI 少一點神祕感,也讓責任回到該負責的人身上。
術語表
| 術語 | 定義 |
|---|---|
| Loop Engineering | 設計可反覆執行、可驗收、可停止的 AI agent 工作循環。 |
| Agent loop | AI 讀取狀態、選擇工具、執行、驗證,再決定下一步的執行循環。 |
| ReAct | 2022 年提出的推理與行動交錯框架。 |
| MCP | Model Context Protocol,讓 AI 應用連接外部資料與工具的開放協定。 |
| Reviewer agent | 只讀檢查者,負責對照驗收清單與測試結果,不直接修改成果。 |
| Human gate | 人類閘門,高風險或未通過檢查時由人決定下一步。 |