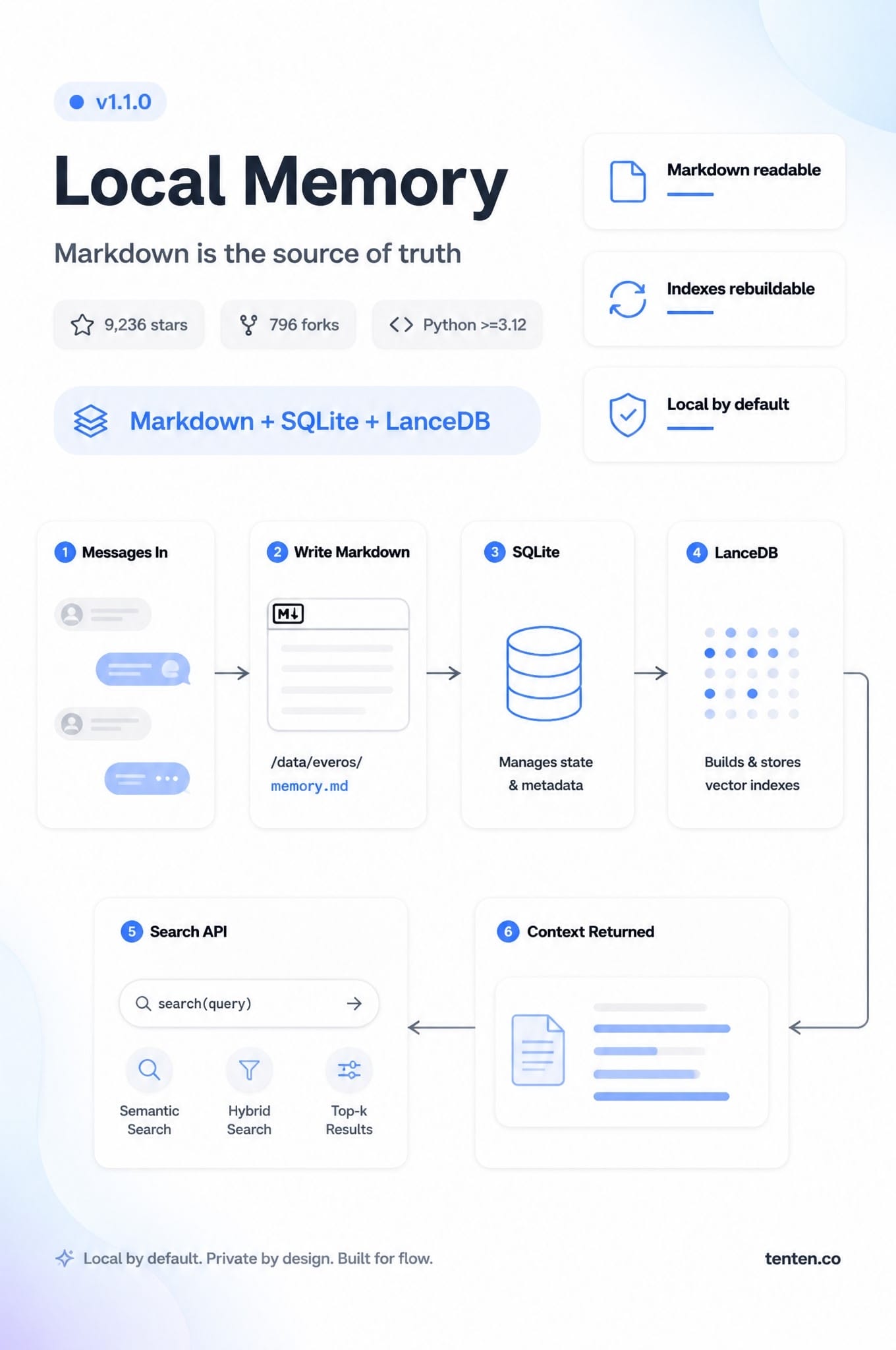
**Agent 記憶架構的核心在於把工作脈絡拆成可攜、可檢查、可重建的長期資產,而不是讓模型多背一點聊天紀錄。**截至 2026 年 6 月 27 日,EverOS 在 GitHub API 查詢中有 9,236 顆星、796 個 fork,PyPI 最新版為 1.1.0;官方文件把它定位為 local-first memory runtime,底層採用 Markdown、SQLite 與 LanceDB。
AI coding agent 現在最痛的地方,通常不在單次回答。真正消耗人的,是每次開新 session 都要重新解釋:這個 repo 怎麼跑、哪個資料夾不能動、哪些客戶命名有歷史原因、上次部署在哪裡卡住。模型可以很強,失憶還是會讓工作變慢。
我會把 agent memory 拆成四層來看:隨時載入的核心事實、需要時查詢的會話存檔、可複用的技能、可替換的外部記憶服務。這個四層模型比「把所有紀錄塞進 prompt」務實,因為它承認一件事:不同記憶的使用頻率、成本與風險不同。
四層模型:先分清楚哪些記憶該常駐
第一層是 prompt memory。它放的是每次啟動都該知道的固定事實,例如專案規範、環境資訊、個人偏好、已知雷區。Claude Code 的官方文件把 CLAUDE.md 與 auto memory 分開:前者由人寫,後者由 Claude 根據修正與偏好累積;兩者都會在 session 起始時載入,但它們扮演 context,而非強制設定。
第二層是 session archive。它不該永遠塞在 prompt 裡,而應該在需要時搜尋。EverOS 的 /api/v1/memory/search 就屬於這類能力。官方 API 文件也提醒,/add 與 /flush 會同步寫入 Markdown,但 LanceDB 索引是非同步更新;剛寫完就搜尋,可能要等 sub-second 到 10-15 秒。
第三層是 skill memory。這一層記的是可重複的流程:部署步驟、除錯路徑、客戶交付格式、審稿規則。EverOS 文件把 agent skills 放在 agent track 內,Claude Code 則把更穩定的任務流程放進 skills 或 path-scoped rules 會更合適。
第四層是外部 provider。Mem0、Letta、MemOS、EverOS 都在解同一類問題,但資料主權與部署邏輯不同。Mem0 的 GitHub 描述是 universal memory layer;Letta 強調 stateful agents;MemOS 強調 self-evolving memory OS。EverOS 的差異在於 Markdown source of truth,SQLite 與 LanceDB 是可重建的索引。
| 層級 | 適合放什麼 | 常見工具形態 | 主要風險 |
|---|---|---|---|
| Prompt memory | 規範、偏好、環境、禁忌 | CLAUDE.md、MEMORY.md |
太長會吃 context,也會降低遵循率 |
| Session archive | 歷史對話、決策、任務軌跡 | SQLite、FTS、向量搜尋 | 沒有查詢策略時會變成資料墳場 |
| Skill memory | 可重複工作流 | skill files、hooks、rules | 太早抽象化會保留錯流程 |
| External provider | 跨工具與跨專案記憶 | EverOS、Mem0、Letta、MemOS | 權限、同步延遲、資料治理 |
EverOS 的判斷點:Markdown 是真實資產
EverOS 官方 overview 寫得很清楚:v1 範圍包含本機部署、conversation / workflow / agent trace / file knowledge 轉成結構化記憶、hybrid retrieval、雙軌 user / agent memory、CLI 與 HTTP API。它不追求一開始就做多人 SaaS。
這一點很重要。對開發者來說,agent memory 最怕變成另一個看不見的 dashboard。EverOS 的 how-memory-works 文件把規則寫成一句話:Markdown 是 source of truth,SQLite 與 LanceDB 是 derived and rebuildable。刪掉 .index/ 可以重建;刪掉 Markdown 才是真的刪掉記憶。
| 檢查點 | 2026-06-27 查證值 | 採用意義 |
|---|---|---|
| 最新 release | v1.1.0,2026-06-24 發布 | 舊的 1.0.x 教學要重看 API 與文件 |
| PyPI 版本 | everos 1.1.0,Python >=3.12 | 部署前先確認 Python |
| GitHub 熱度 | 9,236 stars、796 forks | 有開發者關注,但仍屬早期工具 |
| 授權 | Apache-2.0 | 企業可評估內部整合 |
| 預設 host | 127.0.0.1:8000 | 本機優先,不應裸露到外網 |
| 儲存架構 | Markdown + SQLite + LanceDB | 內容可讀,索引可重建 |
基於這些限制,我會把 EverOS 放在「個人與小團隊可試」的位置,不直接稱為企業平台。官方 API reference 明確說 EverOS 沒有內建 authentication;Security Policy 也說,把 HTTP API 暴露到不可信網路不在支援威脅模型內。這句話要放在安裝指令前面,不能等到出事之後才補。
保留的實作路徑:本機 EverOS + bge-m3
下面保留原始實測路徑中有複製價值的 command blocks。這組流程偏個人本機環境:macOS Apple Silicon、uv、DeepSeek-compatible LLM endpoint、本機 bge-m3 embedding、Obsidian Vault。官方 README 的預設 provider 是 OpenRouter 與 DeepInfra;如果你照下面做,請把它視為自訂 provider 設定,並非官方唯一建議。
先安裝 uv 與 Python 3.12:
curl -LsSf <https://astral.sh/uv/install.sh> | sh
export PATH="$HOME/.local/bin:$PATH"
# 安装 Python 3.12
uv python install 3.12
檢查版本:
uv --version
# -> uv 0.6.x
安裝 EverOS:
uv tool install everos
建立資料目錄。原始路徑把記憶放在 Obsidian Vault,優點是 Markdown 可以直接被人檢查與編輯。
mkdir -p ~/Documents/Obsidian\ Vault/everos-data
建立 ~/Documents/Obsidian Vault/everos-data/.env:
# ─── 数据目录(放在 Obsidian Vault 里)───
EVEROS_MEMORY__ROOT=/Users/<你的用户名>/Documents/Obsidian Vault/everos-data
# ─── LLM:DeepSeek(OpenAI 兼容接口)───
EVEROS_LLM__MODEL=deepseek-v4-flash
EVEROS_LLM__API_KEY=sk-xxxxxxxx # 替换成你自己的 Key
EVEROS_LLM__BASE_URL=https://api.deepseek.com/v1
# ─── 多模态:复用 LLM ───
EVEROS_MULTIMODAL__MODEL=deepseek-v4-flash
EVEROS_MULTIMODAL__API_KEY=sk-xxxxxxxx
EVEROS_MULTIMODAL__BASE_URL=https://api.deepseek.com/v1
# ─── Embedding:本地服务(下一步部署)───
EVEROS_EMBEDDING__MODEL=BAAI/bge-m3
EVEROS_EMBEDDING__API_KEY=local
EVEROS_EMBEDDING__BASE_URL=http://127.0.0.1:9999/v1
# ─── API 绑定与日志 ───
EVEROS_API__HOST=127.0.0.1
EVEROS_API__PORT=8000
EVEROS_LOG_LEVEL=INFO
EVEROS_LOG_FORMAT=text
TZ=Asia/Shanghai
這裡有兩個細節。EVEROS_MEMORY__ROOT 用絕對路徑,避免 shell 展開問題。TZ=Asia/Shanghai 是原始範例值;台灣團隊可以改成 Asia/Taipei,讓日誌顯示符合內部慣例。
自建 embedding 服務:bge-m3 的取捨
Hugging Face 上的 BAAI/bge-m3 文件列出 1024 維、8192 token sequence length,並支援 dense、sparse、multi-vector retrieval。這讓它適合中英文混合的本機記憶檢索,但成本是模型檔案與啟動時間。你可以用官方 provider,也可以照來源流程用 sentence-transformers + FastAPI 自架。
uv venv ~/.local/share/everos-embedding --python 3.12
source ~/.local/share/everos-embedding/bin/activate
uv pip install sentence-transformers fastapi uvicorn
把以下內容保存為 ~/.local/share/everos-embedding/server.py:
import os
import sys
import numpy as np
from fastapi import FastAPI
from pydantic import BaseModel
import uvicorn
# 国内用户设置 HuggingFace 镜像加速
os.environ.setdefault("HF_ENDPOINT", "<https://hf-mirror.com>")
app = FastAPI(title="Local Embedding Server")
MODEL_NAME = "BAAI/bge-m3"
_model = None
def get_model():
global _model
if _model is None:
from sentence_transformers import SentenceTransformer
print(f"[embedding] Loading {MODEL_NAME} ...", file=sys.stderr)
_model = SentenceTransformer(MODEL_NAME)
dim = _model.get_sentence_embedding_dimension()
print(f"[embedding] Loaded. Dimension: {dim}", file=sys.stderr)
return _model
class EmbeddingRequest(BaseModel):
model: str = MODEL_NAME
input: str | list[str]
@app.post("/v1/embeddings")
async def create_embedding(request: EmbeddingRequest):
model = get_model()
inputs = request.input if isinstance(request.input, list) else [request.input]
embeddings = model.encode(inputs, normalize_embeddings=True)
return {
"object": "list",
"data": [{"object": "embedding", "index": i, "embedding": emb.tolist()}
for i, emb in enumerate(embeddings)],
"model": MODEL_NAME,
"usage": {"prompt_tokens": sum(len(t.split()) for t in inputs), "total_tokens": 0}
}
@app.get("/health")
async def health():
return {"status": "ok"}
if __name__ == "__main__":
uvicorn.run(app, host="127.0.0.1", port=9999, log_level="warning")
啟動並測試:
source ~/.local/share/everos-embedding/bin/activate
nohup python ~/.local/share/everos-embedding/server.py \
> /tmp/embedding-server.log 2>&1 &
# 等它下载模型并启动(首次 ~2 分钟,后续秒起)
# 验证:
curl <http://127.0.0.1:9999/health>
# -> {"status":"ok"}
# 测试 Embedding:
curl -X POST <http://127.0.0.1:9999/v1/embeddings> \
-H 'Content-Type: application/json' \
-d '{"input": "测试中文嵌入"}' \
| python3 -c "import sys,json; print(len(json.load(sys.stdin)['data'][0]['embedding']))"
# -> 1024
啟動 EverOS,先測最小記憶鏈路
Embedding 服務起來後,再啟動 EverOS:
everos server start \
--env-file ~/Documents/Obsidian\ Vault/everos-data/.env &
# 验证:
curl <http://127.0.0.1:8000/health>
# -> {"status":"ok"}
此時架構很單純:
localhost:8000 ← EverOS API(记忆读写/搜索/提取)
localhost:9999 ← bge-m3 Embedding(向量化)
↑
└── EverOS 调用 Embedding 做语义索引
寫入、flush、搜尋:
# 1. 写入一条对话
TS=$(($(date +%s)*1000))
curl -X POST <http://127.0.0.1:8000/api/v1/memory/add> \
-H 'Content-Type: application/json' \
-d "{
\"session_id\": \"test-001\",
\"app_id\": \"claude-code\",
\"project_id\": \"default\",
\"messages\": [
{\"sender_id\": \"user\", \"role\": \"user\", \"timestamp\": $TS,
\"content\": \"我需要一个跨会话持久化的 Agent 记忆系统\"}
]
}"
# 2. 触发记忆提取(flush 会让 EverOS 用 LLM 提炼原子事实)
curl -X POST <http://127.0.0.1:8000/api/v1/memory/flush> \
-H 'Content-Type: application/json' \
-d '{"session_id":"test-001","app_id":"claude-code","project_id":"default"}'
# 3. 等几秒后搜索
curl -X POST <http://127.0.0.1:8000/api/v1/memory/search> \
-H 'Content-Type: application/json' \
-d '{
"user_id": "user",
"app_id": "claude-code",
"project_id": "default",
"query": "Agent 记忆系统",
"top_k": 5
}'

這段測試的價值不在 benchmark。它只證明一條最小鏈路:訊息進來,記憶被抽取,Markdown 被寫入,索引稍後可搜。對個人 coding workflow,這已經足夠判斷下一步要不要投入。
接 Claude Code:不要假裝 symlink 等於完整記憶層
原始流程用 symlink 把 Claude Code 的 memory 目錄接到 Obsidian Vault。這個做法能讓 MEMORY.md 變成可見檔案,但仍然只是一個可見化步驟。完整串接仍需要 Claude Code hooks、MCP 或自製橋接層,在任務開始查詢 EverOS,在任務結束 flush 有價值的對話。
# 1. 在 Vault 里创建 Claude Code 记忆目录
mkdir -p ~/Documents/Obsidian\ Vault/claude-code-memory
# 2. 找到 Claude Code 当前项目的 memory 路径
# 一般是 ~/.claude/projects/<项目slug>/memory
# 如果不知道,直接 ls ~/.claude/projects/ 看有哪些项目
# 3. 建软链接
ln -sfn \
~/Documents/Obsidian\ Vault/claude-code-memory \
~/.claude/projects/-Users-<你的用户名>-Documents-workspace-商单-/memory
效果:
Claude Code 写 MEMORY.md
↓
实际写入 ~/Documents/Obsidian Vault/claude-code-memory/MEMORY.md
再包一層管理腳本:
everos-ctl start # 启动 Embedding + EverOS
everos-ctl stop # 停止全部
everos-ctl status # 查看运行状态
everos-ctl search "关键词" # 语义搜索记忆
everos-ctl ingest # 把 Claude Code MEMORY.md 导入 EverOS
如果要自動啟動:
launchctl load ~/Library/LaunchAgents/com.everos.memory.plist
採用建議:從小範圍開始,不要把記憶當魔法
我會先把 EverOS 放進個人或小團隊研發環境,不會直接放進正式企業流程。理由很簡單:它的想法對,版本也在快速前進,但權限、備份、同步延遲、資料分類都還要由使用者自己補。
最適合的起點是 coding agent 的「專案記憶」。讓 agent 記住 repo 的 build command、部署坑、常見測試資料、客戶命名規則。這些東西價值高,敏感度可以控,錯了也容易用 Markdown 檢查。等這層穩了,再考慮跨工具與跨團隊。
客戶敏感資料是最差的起點。EverOS Security Policy 已經提醒:記憶內容是明文 .md 檔案,機密資料要靠作業系統權限或磁碟加密保護。這是設計選擇,不該被誤讀為免費安全承諾;採用者必須正視。
FAQ
Agent 記憶架構是否一定要四層
不一定。四層模型只是判斷工具:哪些資訊每次都要載入,哪些資訊需要搜尋,哪些流程應該變成技能,哪些能力可以交給外部 provider。小專案可以只有 CLAUDE.md 與一個搜尋層。
EverOS 和 RAG 有什麼不同?
RAG 通常把外部知識查回來給模型使用。EverOS 更關心使用者與 agent 互動後留下的長期記憶,並把 Markdown 當 source of truth。它仍使用 hybrid retrieval,但重點是記憶生命週期。
這套流程是否適合台灣企業直接導入
可以做內部試點,不建議直接進正式環境。企業要先補身份驗證、網路隔離、備份、加密、資料分類與稽核。否則 local-first 工具很容易被誤用成沒有防護的內部服務。
bge-m3 是否為唯一選擇
不需要。bge-m3 的優勢是 1024 維、8192 token、支援多語與多種 retrieval 模式。你也可以用 OpenRouter、DeepInfra、OpenAI-compatible endpoint,或其他本地 embedding 服務;重點是 API 與維度要相容。
Claude Code 內建 memory 是否足夠
看用途。Claude Code 的 CLAUDE.md 與 auto memory 適合放規範、偏好與常見更正;跨工具、跨專案與可搜尋歷史資料,通常需要另一層 memory runtime 或資料庫。
權威引用
Author Insight
我對 agent memory 的判斷很務實:先讓記憶變成檔案,再談智慧。看得見、查得到、能回滾,才有資格進入日常工作流。Tenten 在 AI workflow、內容工程與企業自動化專案中。
術語表
| 術語 | 定義 |
|---|---|
| Agent 記憶架構 | AI agent 保存、查詢、重用工作脈絡的系統設計 |
| Prompt memory | 每次 session 起始都載入的規範與核心事實 |
| Session archive | 需要時查詢的歷史對話與任務資料 |
| Skill memory | 從重複工作中抽出的可複用流程 |
| Markdown source of truth | 以 Markdown 檔案作為真實記憶內容,索引可重建 |
| LanceDB | EverOS 用來建立向量、BM25 與 scalar retrieval 索引的本機資料層 |