阿里巴巴 Qwen-2.5 模型強勢登場,號稱最強開源 LLM,效能直逼 GPT-4o!深入了解其卓越效能、獨特優勢。
阿里巴巴再次震撼業界,重磅發布了全新的 Qwen-2.5 模型系列 (中文: 通义千问),包含 13 種不同規模與用途的模型,涵蓋數學、程式碼以及通用領域。其中最引人注目的,莫過於 Qwen-2.5 模型在 Live Bench AI 基準測試中,超越了 Llama 3 的 4050 億參數模型,一舉躍升為全球最強的開源模型,實力甚至超越了 Meta 的最新成果。
Qwen-2.5 模型系列主要分為三大類。首先是基礎模型,參數規模從 55 億一路延伸至 720 億。其次是專為程式設計打造的 Qwen-2.5 模型 Coder 版本,提供 15 億、70 億與 320 億三種參數規模。最後則是 Qwen-2.5 模型 Math 版本,同樣提供與 Coder 版本相同的參數選擇。
值得注意的是,在授權方面,除了 30 億與 720 億參數的 Qwen-2.5 模型外,其餘開源模型皆採用 Apache 2.0 授權。目前,這兩個較大與較小規模的 Qwen-2.5 模型尚未釋出,略顯可惜。不過,使用者可以在 Hugging Face 上找到其他 Qwen-2.5 模型,以及相關的授權檔案。您現在就能在 Hugging Face Spaces 上體驗這些 Qwen-2.5 模型,包含數學模型與程式碼模型。相關連結我會放在文章最後。
如何使用 Qwen 2.5
想要在本地端安裝 Qwen-2.5 模型,可以使用 LM Studio。操作非常簡單,您可以參考我之前關於 LM Studio 的教學影片,我會將連結放在說明欄。只需在 LM Studio 中搜尋 Qwen-2.5,就能找到所有新模型及其不同的量化版本。點擊下載後,在 AI 聊天視窗中選擇您下載的 Qwen-2.5 模型,即可輕鬆開始互動。
Qwen-2.5 模型採用了高達 18 兆個 tokens 的資料進行訓練,顯著提升了其在程式碼、數學以及指令遵循方面的知識與技能,並支援超過 29 種語言,以及高達 228K 的上下文長度。特別是 Qwen-2.5 模型 Coder 與 Math 版本,更針對程式碼與數學進行了深度優化,運用了包含 Chain of Thought、Program of Thought 以及 Tool Integrated Reasoning 等先進的推理技術,使其在眾多基準測試中,相較於其他更大規模的模型,展現了卓越的效能。


測試
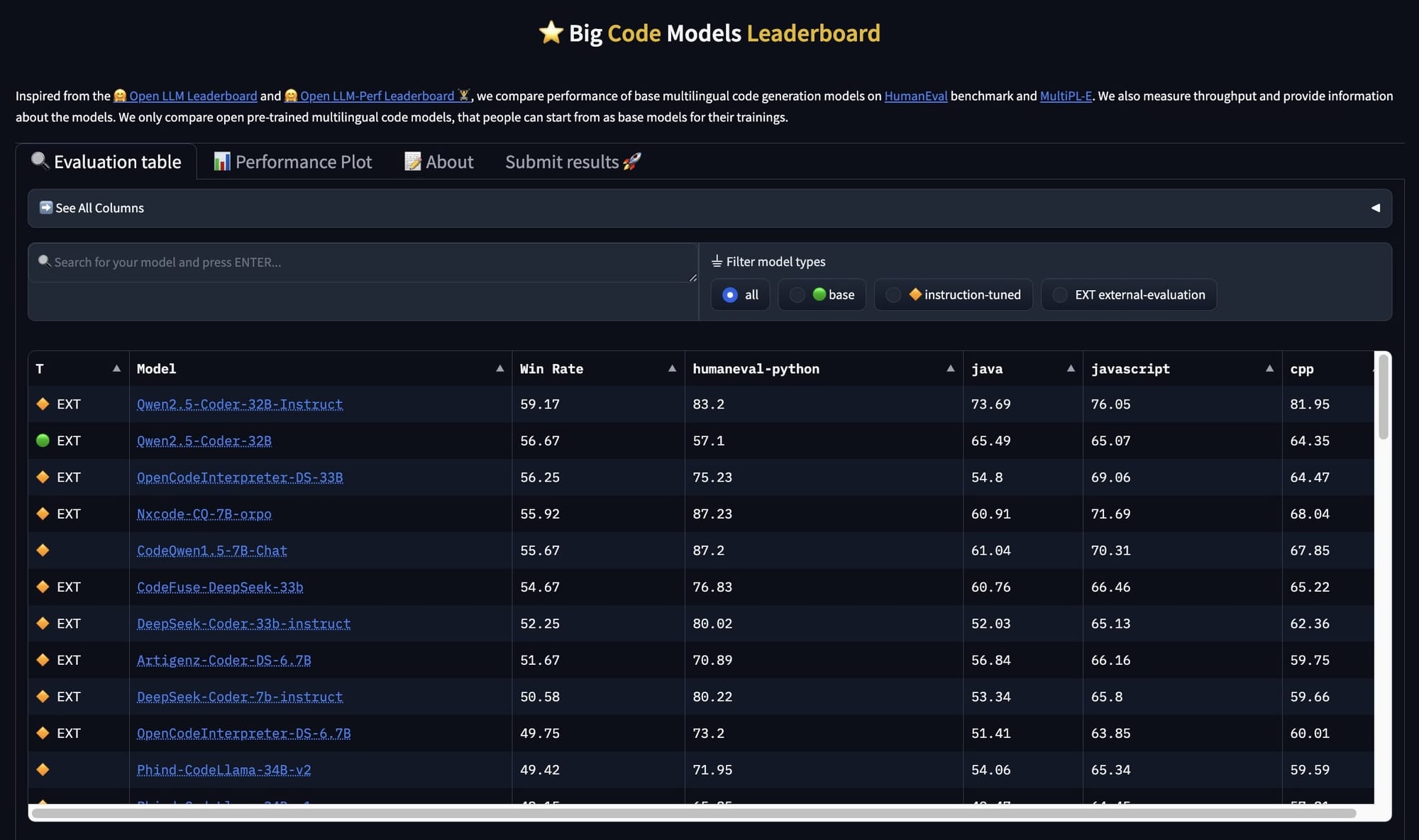
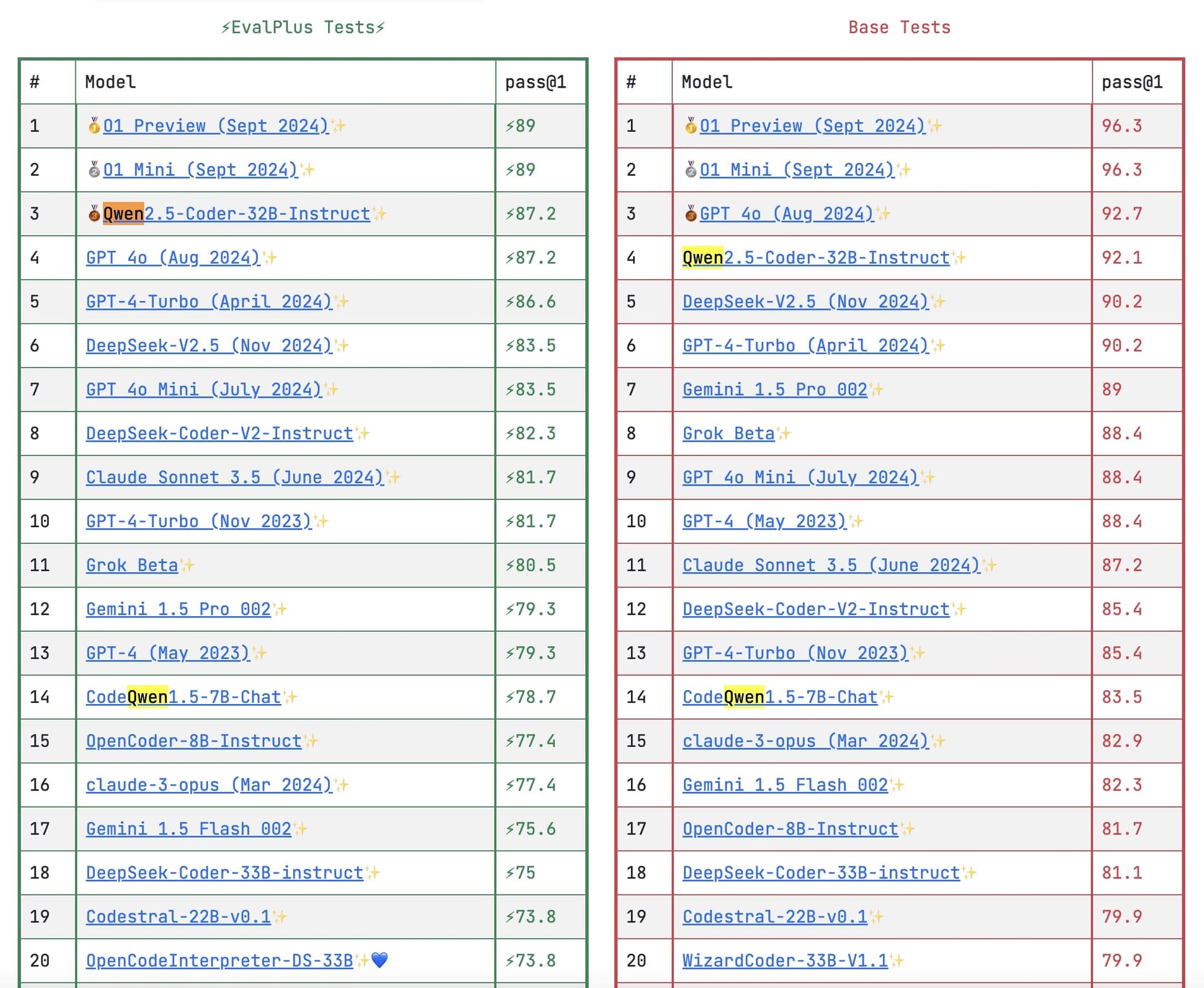
在效能方面,720 億參數的 Qwen-2.5 模型表現最為出色,不僅超越了所有開源模型,甚至超越了 Llama 3 的 1450 億與 700 億參數模型,以及 Mistral Large。更令人驚豔的是,Qwen-2.5 模型在許多基準測試中,效能已逼近 GPT-4o。雖然尚未能全面超越,但在大多數情況下,其表現已相當接近,這也是我極力想向大家介紹 Qwen-2.5 模型的原因,它是目前最強大的開源模型。
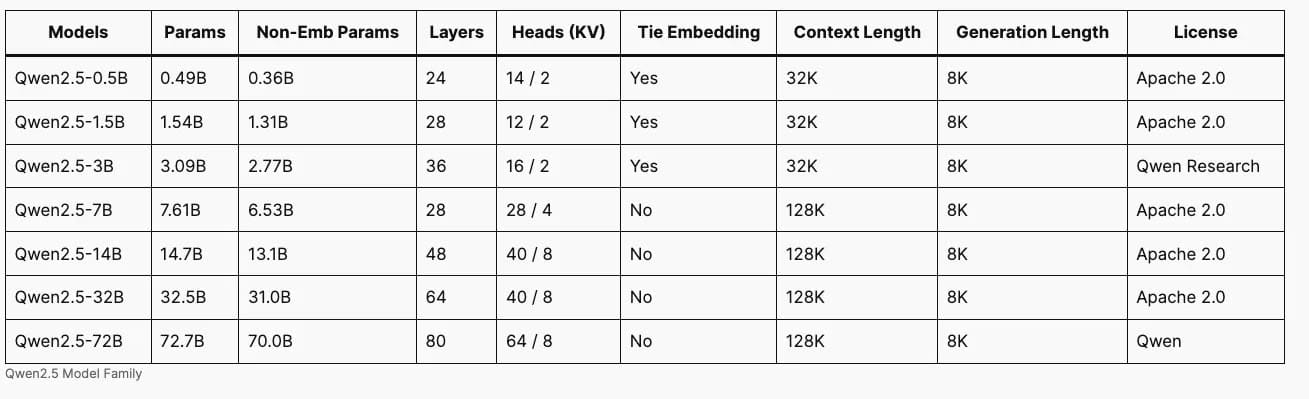
工作原理: Qwen 2.5 系列參數範圍從 5 億到 720 億個參數。
- Qwen 2.5 模型在 18 兆個代幣上進行了預訓練。參數大小高達 30 億個,可處理多達 32,000 個輸入令牌;較大的模型可以處理多達 128,000 個輸入標記。所有版本的輸出長度都可以為 8,000 個令牌。
- Qwen 2.5-Coder 在 5.5 兆個代碼標記上進行了進一步的預訓練。它可以處理多達 128,000 個輸入令牌並產生多達 2,000 個輸出令牌。它有 1.5B 和 7B 版本。
- Qwen 2.5-Math 對 1 兆個數學問題進行了進一步預訓練,其中包括從網路上抓取並由早期 Qwen 2-Math-72B-Instruct 產生的中國數學問題。 Qwen 2.5-Math 可以處理 4,000 個輸入標記並產生最多 2,000 個輸出標記。它有 1.5B、7B 和 72B 版本。除了解決數學問題外,Qwen 2.5-Math 還可以產生程式碼來幫助解決給定的數學問題。
結果:與具有開放權重的其他模型相比,Qwen 2.5-72B-Instruct 在 14 個基準測試中的 7 個上擊敗了 LLama 3.1 405B Instruct 和 Mistral Large 2 Instruct(1230 億個參數),包括LiveCodeBench 和 Mistral Large 2 Instruct(1230 億個參數),包括LiveCodeBench 、 MATH (解決數學應用問題)和MMLU (回答有關各種主題的問題)。與響應 API 呼叫的其他模型相比,Qwen-Plus 在 MATH、LiveCodeBench 和ArenaHard上擊敗了 LLama 3.1 405B、Claude 3.5 Sonnet 和 GPT-4o。較小的版本也能提供出色的效能。例如,Qwen 2.5-14B-Instruct 在七個基準測試中優於 Gemma 2 27B Instruct 和 GPT-4o mini。
當然,有些人可能會對 Qwen-2.5 模型的來源地感到擔憂,尤其是在資料隱私方面。這也是許多人對於使用這類模型有所顧慮的原因,這點確實令人遺憾。不過,值得注意的是,小型語言模型 (SLMs) 正迅速縮小與大型模型之間的差距。在官方部落格中特別提及了 Qwen-2.5 模型的 30 億參數版本,儘管體積較小,卻取得了令人印象深刻的成果,在 MMLU 基準測試中獲得了超越 65 分的成績。這顯示 Qwen-2.5 模型在關鍵更新方面下了許多功夫,包含支援生成高達 8K 的 tokens、提升處理結構化資料的能力、更優異的 JSON 輸出生成,以及強化了多樣化提示下的角色扮演能力。看到如此小型的模型也能媲美大型模型,實在令人振奮。
Qwen-2.5 模型系列中的程式碼模型 - Qwen/Qwen2.5-Coder-32B-Instruct,專為程式設計任務而設計,例如除錯和提供程式碼建議,如同其他程式碼模型一樣。儘管體積較小,但其效能表現強勁,相較於許多知名的模型,例如 DeepSeek Coder 的 330 億 Instruct 模型,以及舊版的 DeepSeek 模型,表現都相當出色。雖然與最新發布的 DeepSeek 模型相比仍有差距,但 Qwen-2.5 模型在多種程式語言中,皆能超越許多更大規模的模型,使其成為您程式設計的絕佳助手。

目前,320 億參數的程式碼模型仍在準備中,但已發布的 70 億參數基礎模型,相較於其他小型程式碼模型,特別是 StarCoder 和 DS Coder,表現已相當亮眼。雖然尚未能超越 DEC Coder,但絕對值得密切關注。Qwen-2.5 模型 Coder Instruct 版本在 40 種不同的程式語言和程式碼推理任務中表現優異,在基準測試中取得了優異的成績,並在數學任務中也展現了良好的能力。這突顯了 Qwen-2.5 模型在程式設計和數學方面的雙重專長。目前,此版本已開放 Apache 2.0 授權使用,但如同前面提到的,320 億參數版本尚未釋出。開發團隊正致力於挑戰更高階的模型,包含那些專有模型,這點讓我非常期待。
Qwen-2.5 模型在數學、基礎邏輯以及作為聊天模型方面的卓越能力。作為一個開源模型,Qwen-2.5 模型絕對是一個可以本地部署的絕佳選擇,可以作為 Cloud 或甚至是 OpenAI 模型的替代方案。我強烈建議大家親自嘗試看看 720 億參數的 Qwen-2.5 模型。
我衷心希望 Alibaba 的開發團隊能夠進一步提升 Qwen-2.5 模型的程式碼能力,這將使其成為市面上最強大的模型之一。但就目前而言,Qwen-2.5 模型已是一款非常出色的模型,我強烈建議您親自體驗。
不想錯過任何關於 AI, 大語言模型以及 AI 程式碼工具的進展,可 follow 我們的 thread: @tentenai_com / @tenten.co
Learn more about Qwen-2.5
- Qwen - 官方文件
- Qwen - Hugging Face
- Qwen-2.5-Coder 32B – 徹底改變編碼的人工智慧! - 盒子裡的真神? : r/LocalLLaMA — Qwen-2.5-Coder 32B – The AI That's Revolutionizing Coding! - Real God in a Box? : r/LocalLLaMA
- GitHub - QwenLM/Qwen2.5-Coder: Qwen2.5-Coder is the code version of Qwen2.5, the large language model series developed by Qwen team, Alibaba Cloud.
更多關於 AI 編碼工具
- GitHub Copilot 免費版發布:開發者的福音
- AI 程式助手哪家強?WindSurf vs. Cursor AI vs. Bolt.net 大對決
- 告別加班!AI 幫你輕鬆開發:2025必備程式助手推薦
- Qwen 2.5 Coder(32B): 開放AI模型的全新選擇
- Cursor 神技大公開!編碼速度提升 2 倍,效率翻倍
- AI程式工具推薦:新手也能輕鬆上手的開發神器
- 8歲女孩也能輕鬆上手!Cursor 讓AI程式設計不再遙不可及
- Cursor AI 顛覆程式開發!零基礎也能快速打造App
- Qwen-2.5 模型:最強開源 LLM,效能直逼 GPT-4o!
常見問答 (FAQ)
Q1: Qwen-2.5 模型有哪些主要版本? A1: Qwen-2.5 模型系列主要分為三大類:基礎模型(55億至720億參數)、程式設計專用的Coder版本(15億、70億與320億參數)以及Math版本(同樣提供15億、70億與320億參數)。
Q2: Qwen-2.5 模型的訓練規模有多大? A2: Qwen-2.5 模型採用了高達18兆個tokens的資料進行訓練,支援超過29種語言,並且具有高達228K的上下文長度處理能力。
Q3: Qwen-2.5 模型的效能表現如何? A3: 720億參數的Qwen-2.5模型不僅超越了所有開源模型(包括Llama 3的1450億與700億參數模型),在許多基準測試中的表現已經接近GPT-4o的水準。
Q4: 如何在本地端使用Qwen-2.5模型? A4: 可以通過LM Studio來安裝使用Qwen-2.5模型。在LM Studio中搜尋Qwen-2.5,選擇並下載所需版本,然後在AI聊天視窗中選擇下載的模型即可開始使用。
Q5: Qwen-2.5 Coder版本有什麼特色? A5: Qwen-2.5 Coder版本專門針對程式設計任務最佳化,支援40種不同程式語言,特別適合用於除錯和提供程式碼建議,在多項基準測試中表現優異。