RAG 和 Fine-tuning (微調) 是 LLM 兩種關鍵技術。本文深入比較兩者差異、優缺點與適用情境,協助您選擇最適合的 LLM 應用策略,提升模型效能與準確性。
在人工智慧(AI)飛速發展的時代,如何增強大型語言模型(LLM)的效能,一直是各大企業與開發者關注的核心議題。RAG(Retrieval Augmented Generation)與Fine Tuning堪稱現今最常見的兩大解決方案。本文將從原理、優勢、使用情境以及如何組合運用等面向切入,帶你完整解析「RAG vs Fine Tuning」的奧祕,並幫助你判斷適合自身應用的最佳方案。
為什麼需要增強大型語言模型?
大型語言模型具有強大的自然語言處理能力,但在應用層面仍面臨兩大問題:
- 訓練資料侷限:LLM 可能缺少最新或特定領域的訓練數據,導致回應不足或資訊落後。
- 用途過於廣泛:預設的 LLM 通常相當通用,若要應用於企業內部,往往需要進一步「專業化」,才能在特定領域提供更有深度的回應。
因應以上挑戰,選擇「RAG vs Fine Tuning」就變得格外重要。
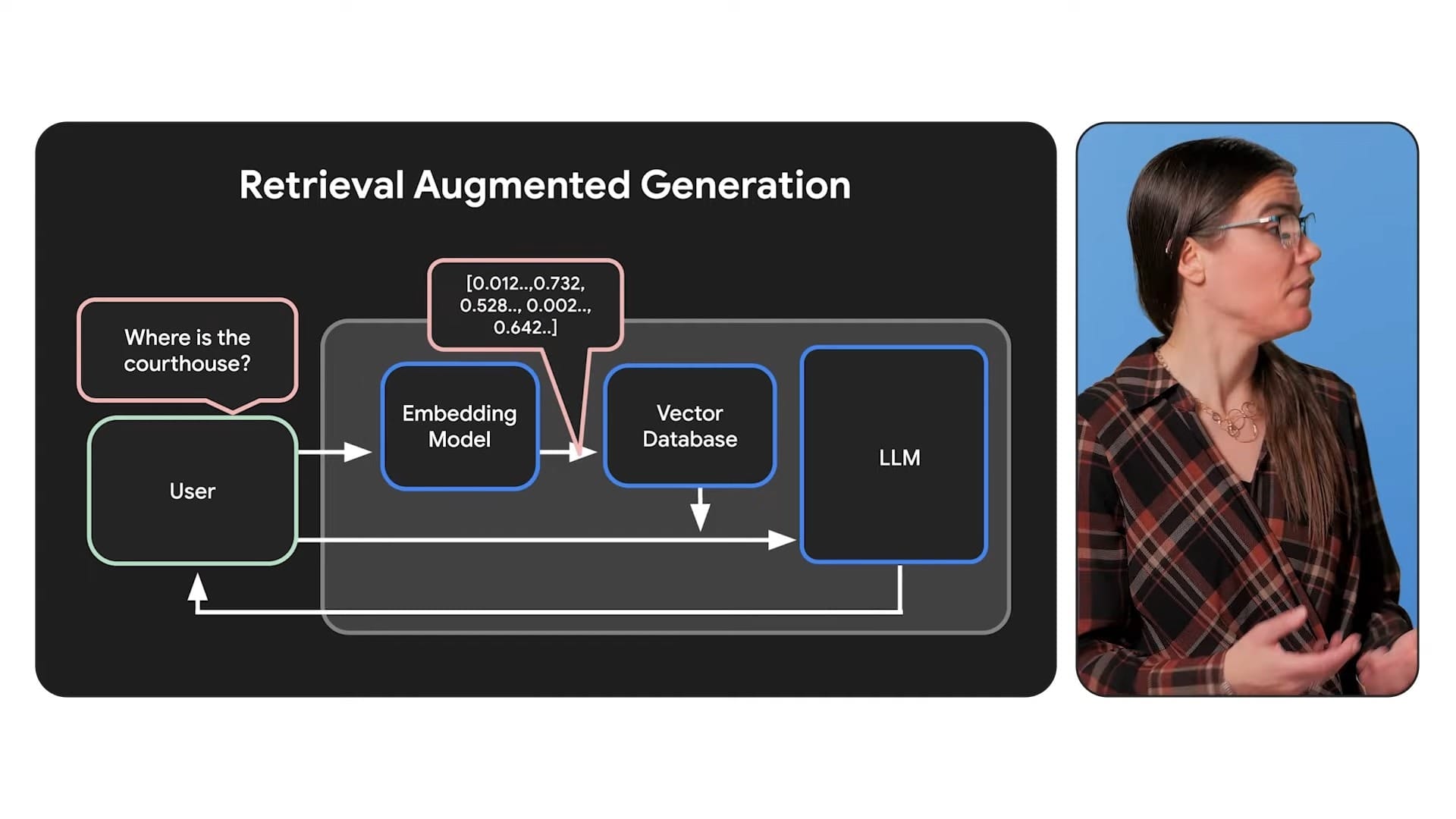
什麼是 RAG(Retrieval Augmented Generation)?
RAG的核心概念在於:
- 檢索外部資料:先透過檢索系統從資料庫或其他動態資料來源,取得與問題相關的「最新」資訊。
- 增補提示(Prompt):將檢索到的背景資料與使用者的原始問題一起送入模型。
- 生成答案:大型語言模型在結合自身的預訓練知識與額外提供的資訊後,產生更精準的回答。

為何 RAG 能解決 LLM 的「過時」問題?
以「歐洲盃 2024」比賽結果為例,預訓練的 LLM 若無最新賽事資訊,回答可能會失準,甚至出現「幻覺」(hallucination)般的不實內容。有了 RAG,系統能及時檢索最新戰果,再把結果與提示一同送入模型,最後給出更可靠的回應。
RAG 的優勢
- 動態更新:能持續串接最新資料,適合需要即時資訊的系統。
- 降低幻覺風險:使用真實來源的外部文件,有助提供依據與透明度。
- 無需改動原始模型:只要確保資料庫和檢索系統的效率,即可不斷「補充」模型知識。
RAG 的挑戰
- 維運成本:需要額外的檢索系統或資料庫,且資料量愈大,檢索策略愈複雜。
- 依賴 Prompt 容量:受限於模型的「上下文視窗」,要精心選擇最相關的內容放入提示,才能達到最佳效果。

RAG (Retrieval-Augmented Generation)
- 運作方式:
- RAG 通過結合語言生成與資訊檢索技術,讓模型能從外部資料庫中檢索相關資訊並將其整合到生成的回應中。
- 不需要改變模型本身,而是依賴外部知識來源(如內部數據庫、文件或網頁)來補充模型的回應能力。
- 優勢:
- 動態更新:適合需要即時訪問最新信息的場合,如新聞、產品資訊或政策更新。
- 減少幻覺現象:通過引用外部資料,降低生成錯誤或虛構內容的風險。
- 成本效益高:無需重新訓練模型,適合快速部署和頻繁更新的需求。
- 劣勢:
- 延遲問題:因為需要檢索外部資料,回應速度可能較慢。
- 依賴數據質量:檢索結果的準確性取決於外部知識庫的完整性和更新頻率。
- 適用場景:
- 需要即時訪問最新數據的應用,如客戶服務聊天機器人、內部知識管理系統。
常見的 RAG (Retrieval-Augmented Generation) 使用案例
RAG 技術結合了檢索與生成模型的優勢,能夠動態檢索外部知識並生成上下文相關的回應,因此在多個領域中具有廣泛應用。以下是一些常見的使用案例:
1. 問答系統
- 應用場景:RAG 可用於開發高級問答系統,通過檢索相關文檔或資料來生成準確且具體的答案。
- 優勢:適合處理需要整合多來源資訊的複雜查詢,例如醫療診斷、法律諮詢或技術支持。
2. 客服與聊天機器人
- 應用場景:RAG 增強了客服聊天機器人的能力,能即時訪問產品資訊、客戶歷史記錄等,提供更精準和上下文相關的回應。
- 優勢:改善客戶體驗,提升問題解決效率和滿意度。
3. 電子商務與個性化推薦
- 應用場景:在零售和電子商務中,RAG 可根據用戶偏好和產品資料生成個性化推薦。
- 優勢:提高轉化率和客戶參與度,提供更相關的購物建議。
4. 內容生成與摘要
- 應用場景:RAG 用於自動生成高質量內容或摘要,例如新聞報導、技術文件或市場分析。
- 優勢:通過檢索可信來源的信息,確保生成內容的準確性和一致性。
5. 醫療與健康 (醫療 AI)
- 應用場景:RAG 在醫療領域可用於診斷輔助、臨床試驗設計以及醫學知識查詢。
- 優勢:快速檢索病患記錄、醫學文獻等,幫助醫療專業人員做出更明智的決策。
6. 法律研究與文書處理
- 應用場景:在法律領域,RAG 可檢索案例法、法規或合同條款以支持法律研究和文件起草。
- 優勢:加速處理時間,減少錯誤,提高工作效率。
7. 決策支持系統
- 應用場景:RAG 用於企業決策支持,例如分析數據集、評估選項或預測趨勢。
- 優勢:幫助組織快速獲取關鍵資訊並制定策略。
8. 搜尋引擎與信息檢索
- 應用場景:RAG 增強了搜索引擎的功能,不僅能檢索相關文檔,還能生成信息豐富的摘要。
- 優勢:提高搜索結果的相關性和可讀性。
9. 虛擬助手與即時信息查詢
- 應用場景:虛擬助手可利用 RAG 提供即時更新的信息,例如天氣、新聞或事件資訊。
- 優勢:提供更準確且上下文相關的答案,提升交互體驗。
10. 工業與製造業
- 應用場景:RAG 幫助快速訪問工廠運營數據、故障排除指南或合規標準。
- 優勢:支持決策過程並促進創新。
RAG 技術在解決動態信息需求、提升生成內容準確性以及改善交互體驗方面表現出色。它適合需要整合多來源數據並提供上下文相關回應的各種應用場景。
什麼是 Fine Tuning?
若說 RAG 是「額外補充資訊」,那麼Fine Tuning就是把所需的領域知識「融入」模型本身,使其能更貼合特定應用場景。過程中透過標記好的資料(labeled data),對模型再進行一段訓練,最終得到一個在該領域更精通的小型語言模型。

Fine Tuning 能帶來哪些好處?
- 深度專業化:可針對保險、法律、金融等高專業領域,強化模型在專業術語、口吻與邏輯推理上的表現。
- 降低推論成本:Fine Tuning 後的模型對於特定任務可使用較小的 Prompt,就能得到更準確的回覆,進而提高運算效率。
- 直接整合到模型權重中:所學到的知識成為模型內建的一部分,生成結果速度更快,也更具有一致性。
Fine Tuning 的限制
- 資料時效性:模型只知道訓練至截稿時間點之前的資訊,之後的變動無法即時反映。
- 訓練成本:需要投入額外的計算資源與時間,且對資料品質與標記正確性有相當要求。
- 模型大小受限:如果資料持續增長,還得再次做 Fine Tuning,流程並不輕鬆。
Fine-tuning
- 運作方式:
- Fine-tuning 是在預訓練模型的基礎上,使用特定領域的小型數據集進行再訓練,以調整模型參數,使其更適合特定任務。
- 通常需要凍結部分層或添加新的任務專用層來進行高效調整。
- 優勢:
- 專業化表現:能夠深入理解特定領域或任務,提供一致且高質量的回應。
- 定制化能力強:可以調整模型行為、語氣和專業術語以符合特定需求。
- 劣勢:
- 資源密集型:需要大量計算資源和時間來進行訓練,尤其是對於大型模型。
- 靜態性:由於基於靜態訓練數據,無法處理最新或動態變化的信息。
- 適用場景:
- 適合需要一致性和專業性表現的任務,如醫療診斷、法律文件分析、技術支援等。
LLM 微調的常見用例有哪些?
在大型語言模型(LLM)的實際應用中,**微調(Fine-tuning)**能有效將通用模型轉化為符合特定領域或任務需求的專用工具。以下整理關鍵應用場景與實際案例:
一、提升領域專業知識
針對高度專業的產業需求,微調能讓模型掌握特定領域的術語與邏輯。例如:
- 醫療領域:透過臨床病歷(如 MIMIC-III 資料庫)微調模型,可自動生成病患摘要,加速醫護人員診斷流程。
- 金融領域:以財經新聞與財報微調模型(如 BERT/RoBERTa),強化市場情緒分析準確度,協助預測股價波動。
- 法律領域:分析合約條款時,微調模型能辨識法律用語的異常或關鍵條款,提升審查效率。
二、客製化任務優化
根據商業場景需求,微調可強化模型在特定任務的表現:
- 內容生成:調整模型產出符合品牌調性的行銷文案或社群貼文(例如模仿 Elon Musk 的推文風格)。
- 分類與標籤化:電商平台透過微調 DistilBERT 模型,自動將商品描述分類至正確目錄,提升搜尋精準度。
- 指令遵循:使用指令微調(Instruction Tuning)讓模型更準確執行「總結此文件」或「翻譯成法文」等明確任務。
三、解決技術限制
微調能克服預訓練模型的先天限制:
- 長文本處理:當任務需處理超長文件(如法律合約或研究論文),微調可減少對輸入長度的依賴,並維持輸出品質。
- 降低推論成本:透過參數高效微調(PEFT)或量化技術(QLoRA),能在有限資源下維持模型效能,適合邊緣運算場景。
四、確保資料合規與隱私
企業使用內部資料微調模型,可避免敏感資訊外流至第三方平台。例如:
- 醫療病歷分析:醫院在本地端微調模型,確保患者資料不外洩。
- 內部文件處理:金融機構微調模型解析內部報告,取代手動整理流程。
五、強化互動體驗
微調能塑造更自然的用戶互動:
- 客服聊天機器人:調整回應語氣與風格,使其符合企業形象(如專業正式或輕鬆口語)。
- 個人化推薦:零售業透過微調模型分析用戶行為,提供精準商品推薦。
透過上述應用,微調技術已成為企業將 LLM 整合至核心業務的關鍵步驟,既能保留通用模型的廣泛知識,又能針對特定需求大幅提升效能與適用性。
RAG vs Fine Tuning:什麼時候該用哪一種?
RAG 與 Fine-tuning 的選擇建議
| 特性 | RAG | Fine-tuning |
|---|---|---|
| 更新能力 | 即時訪問最新數據 | 基於靜態數據 |
| 準確性 | 適合廣泛查詢,但可能在特定領域表現有限 | 在特定領域提供更高準確性 |
| 延遲 | 可能較高(需檢索外部資料) | 低延遲(無需檢索) |
| 成本與資源需求 | 部署成本低,但運行時需維護知識庫 | 訓練成本高,但部署後維護成本低 |
| 適用場景 | 動態環境,如即時查詢 | 靜態環境,如專業領域應用 |
1. 資料更新頻率
- RAG:如果你的資料在不斷更新,或需求依賴最新資訊,如時事新聞、產品更新說明等,RAG 可以隨時檢索並整合。
- Fine Tuning:當你的領域知識比較穩定(例如法律條文、內部規範),且需要模型更深入地瞭解專業用語與架構時,Fine Tuning 會更適合。
2. 資料來源與透明度
- RAG:可直接提供外部文件來源與引文,有助於解答結果的可信度;非常適合金融、醫療或需要明確引用來源的情境。
- Fine Tuning:如果只是想要一個更「懂行話」的模型,並不在意即時地引用出處,Fine Tuning 更能一勞永逸地「改造」模型。
3. 整合應用可能性
- 同時運用 RAG 與 Fine Tuning:
- 先用 Fine Tuning 讓模型熟悉專業領域的常用語彙、格式與邏輯。
- 再透過 RAG 連結即時或近乎即時的資料,如最新新聞、檔案或數據庫。
- 這種組合為金融快訊、法條檢索、醫療研究等高度專業又需要動態資訊更新的情境,提供了最完整的解決方案。
綜合建議
- 如果需要處理動態信息且資源有限,RAG 是更好的選擇。
- 如果目標是提升某一特定領域的專業表現且有足夠資源,則應選擇 Fine-tuning。
- 在某些情況下,可以結合兩者(稱為 RAF)
結論:量身打造你的 AI 策略
「RAG vs Fine Tuning」並非非此即彼的二元抉擇;兩種方法都有其適用場合,也能相輔相成。對於依賴最新資訊的應用而言,RAG 能帶來更高彈性與即時性;而需要深度專業化的場景,Fine Tuning 則能提供更強大的內建智慧。若想兼顧即時性與專業度,混合使用往往能發揮事半功倍的效果。
無論你是開發者還是企業決策者,都該先盤點自己的資料特性與應用需求,再決定是採用 RAG、Fine Tuning,或是兩者結合。唯有深入理解「RAG vs Fine Tuning」的差異與優勢,才能在瞬息萬變的 AI 競賽中脫穎而出。
如果你對 RAG 或 Fine Tuning 仍有任何疑問,歡迎在留言區與我們分享你的想法。別忘了訂閱我們的頻道持續關注,以掌握更多 AI 相關的最新資訊!