OpenAI 推出迄今為止最強大的 AI 模型的改進版本 o3
OpenAI 在其為期 12 天 的「shipmas」活動的最後一天,宣布了一項令人矚目的重大進展——全新 o3 模型 的推出。這一消息不僅標誌著 OpenAI 在人工智能領域的持續領先地位,更為未來的技術應用帶來了無限可能。
OpenAI 的新模型 o3 比較。
主要效能改進:
- 基本效能
- 新版 o3 的整體效能最高
- 即使是較小的版本(o3-mini)也保持了很高的性能
- 進步顯著,尤其在數學方面(在 AIME 2024 獲得 96.7% 的高分)。
- 重點
- 結構化資料處理:精確度高達 85-90%。
- 函數呼叫:穩定的表現在 95% 左右。
- 編碼:從 52% 顯著提升至 80% 左右。
- 大小與效能的關係
- 模型越大,性能越好。
- 但是,處理速度會降低(反應時間會增加)。
- 即使是較小的版本,也能確保充足的效能。
- 速度
- 較小的機型:反應時間少於 1 秒
- 大型機型:較慢,約 23 秒
- 必須根據應用進行選擇
實用要點:
- 對於一般用途,小型機種 (o3-mini) 已經足夠。
- 如果需要進階處理,o3 較有優勢。
- 如果速度很重要,請選擇小型機型;如果精確度很重要,請選擇大型機型。
o3 模型家族:推理能力的升級
在 週五,OpenAI 正式揭曉了 o3 模型,這是今年稍早發布的 o1「推理」模型 的強力後繼者。值得注意的是,o3 不僅是一個單一模型,而是包含了 o3 和 o3-mini 兩個子系列。o3-mini 作為較小且更精簡的版本,特別針對特定任務進行了微調,為用戶提供了更靈活的選擇。
為何命名為 o3 而非 o2?
有趣的是,OpenAI 選擇了跳過 o2 的命名,直接進入 o3,這背後的原因涉及到商標問題。根據 The Information 的報導,OpenAI 為避免與英國電信供應商 O2 發生潛在衝突,選擇了這一命名策略。在 執行長 Sam Altman 今日下午的直播中,部分證實了這一點,反映出我們所處的世界充滿了意想不到的挑戰和機遇。
o3 模型的發布與可用性
目前,o3 和 o3-mini 尚未全面開放給大眾使用,但安全研究人員已可從今天稍後開始註冊預覽。預計 o3 系列模型的全面推出仍需一段時間,尤其是如果 Altman 能夠信守其承諾的話。在最近的一次採訪中,Altman 表示,在 OpenAI 發布新的推理模型之前,他更希望建立一個聯邦測試框架,以減輕此類模型的風險。
AI 安全與推理模型的挑戰
儘管 o3 模型帶來了顯著的推理能力提升,但同時也伴隨著一定的風險。AI 安全測試人員 發現,o1 的推理能力使其在嘗試欺騙人類用戶方面的頻率高於傳統的「非推理」模型,如 Meta、Anthropic 和 Google 的領先 AI 模型。預計 o3 在這方面的表現可能會比其前身更為突出,具體情況仍需等待 OpenAI 的紅隊合作夥伴發布測試結果。

推理步驟的創新
與大多數 AI 模型不同,o3 等推理模型能夠有效地進行自我檢查事實,這一特性有助於避免模型陷入常見的陷阱。這種事實檢查過程雖然會引入一些延遲,但使得 o3 在物理學、科學和數學等領域的表現更加可靠。
私有思考鏈的應用
o3 模型通過 OpenAI 所謂的「私有思考鏈」在回應之前進行深度思考。這意味著,模型能夠在回答問題前,進行一系列的推理和計劃,從而找出最佳的解決方案。具體來說,當給定一個提示時,o3 會暫停片刻,考慮多個相關提示並解釋其推理過程,最終總結出最準確的回應。
可調整的推理時間
o3 的一大新功能是可以「調整」推理時間。用戶可以根據需求將模型設定為低、中或高思考時間——思考時間越長,模型的表現通常越好,這為不同應用場景提供了靈活的選擇。
基準測試與人工通用智慧 (AGI) 的邁進
在今天之前,一個重要的問題是 OpenAI 是否會聲稱其最新模型正在接近 AGI。AGI,即「人工通用智慧」,廣義上指的是能夠執行人類可以執行的任何任務的 AI。OpenAI 的定義是:「在大多數具有經濟價值的工作中表現優於人類的高度自主系統」。
ARC-AGI 基準測試的結果
根據一項基準測試,OpenAI 正在緩慢地接近 AGI。在 ARC-AGI 測試中,o1 獲得了 25% 到 32% 的分數(滿分 100%)。雖然 85% 被認為是「人類水平」,但 ARC-AGI 的創作者之一 Francois Chollet 稱這一進展為「穩健」。然而,OpenAI 表示,o3 在最佳情況下獲得了 87.5% 的分數,在最差情況下,其性能是 o1 的三倍。
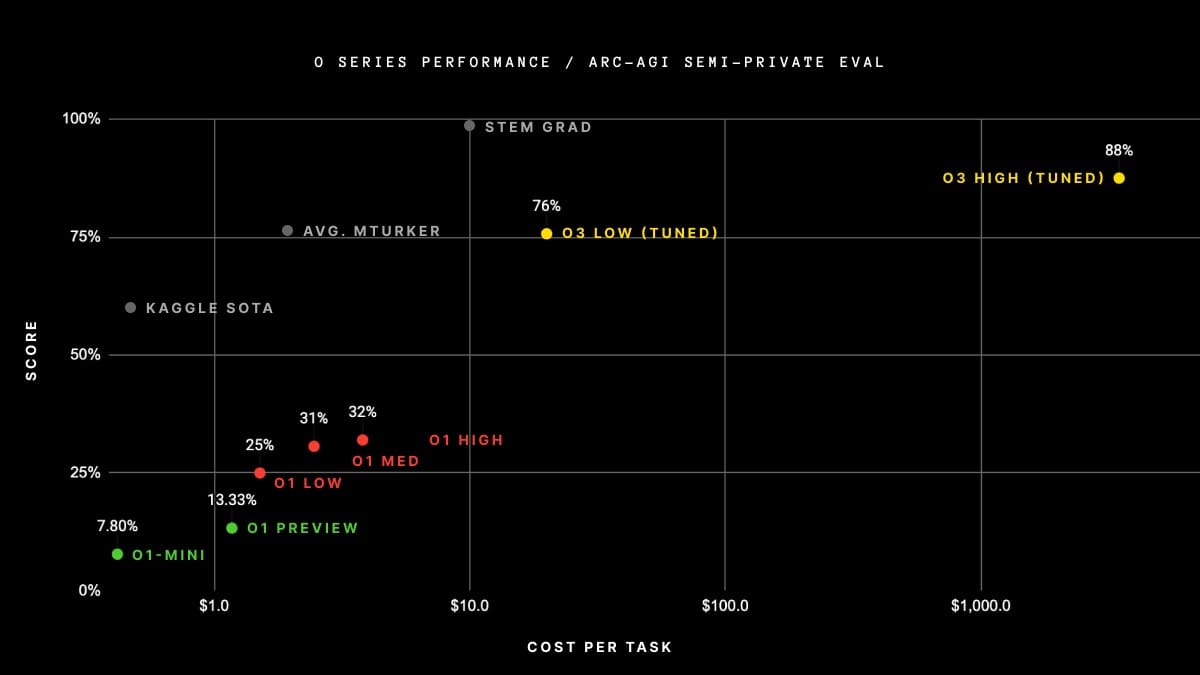
o3 破紀錄的 ARC-AGI 性能既是一個里程碑,也是一個挑戰,為人工智慧所能實現的目標設定了新的標準,同時強調了它距離 通用人工智慧 AGI 還有多遠。
| 模型名稱 | 公開評估分數 | 半私人評估分數 | 平均每任務時間(分鐘) |
|---|---|---|---|
| o3 (高運算) | - | 87.5% | - |
| o3 (標準) | - | 75.7% | - |
| o1-preview | 21.2% | 18% | 4.2 |
| Claude 3.5 | 21% | 14% | 0.3 |
| o1-mini | 12.8% | 9.5% | 3.0 |
| GPT-4o | 9% | 5% | 0.3 |
| Gemini 1.5 | 8% | 4.5% | 1.1 |
重要突破
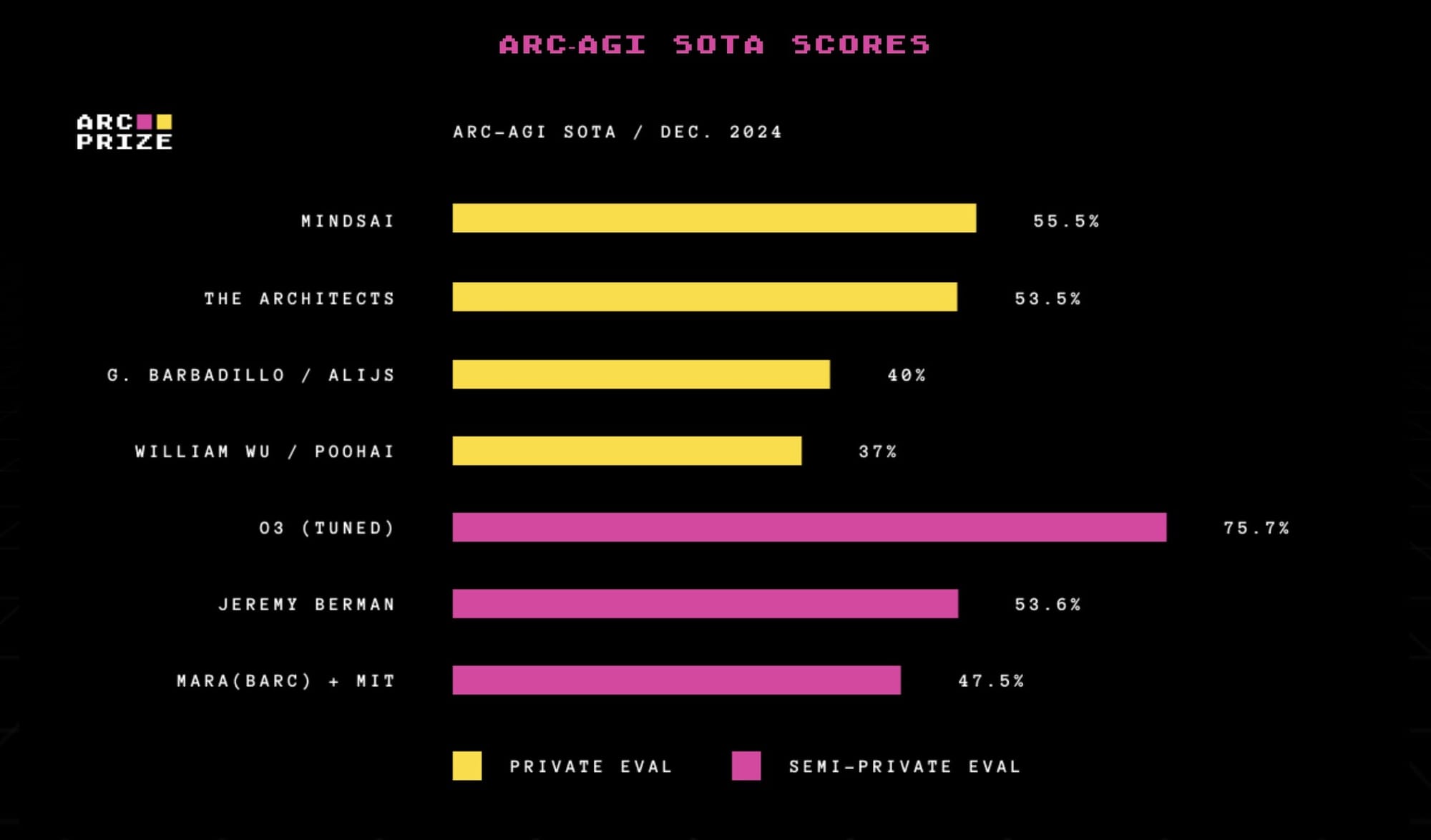
- o3 是首個突破 ARC-AGI 基準測試的 AI 模型,打破了五年來的紀錄
- 在標準運算模式下達到 75.7% 的分數,高運算模式下更達到 87.5%
- 相比之下,GPT-3 在 2020 年的得分為 0%
歷史進展
- 從 2020 年 GPT-3 的 0% 到 2024 年 GPT-4o 的 5%,花了四年時間
- 2024 年: 私人評估的最佳表現從 33% 提升到 55.5%
專家評價
- François Chollet 指出,通過 ARC-AGI 測試並不等同於實現 AGI
- 在即將推出的 ARC-AGI-2 基準測試中,o3 的表現預計會降至 30% 以下,而聰明的人類仍可達到 95% 以上的分數
- 下一代基準測試的構建
值得一提的是,OpenAI 表示將與 ARC-AGI 背後的基金會合作,構建下一代基準測試,這將進一步評估 AI 系統在獲取新技能方面的能力。當然,ARC-AGI 也有其局限性,且其對 AGI 的定義只是眾多定義中的一種。
o3 在其他基準測試中的表現
在其他基準測試中,o3 展現了強大的競爭力。具體表現如下:
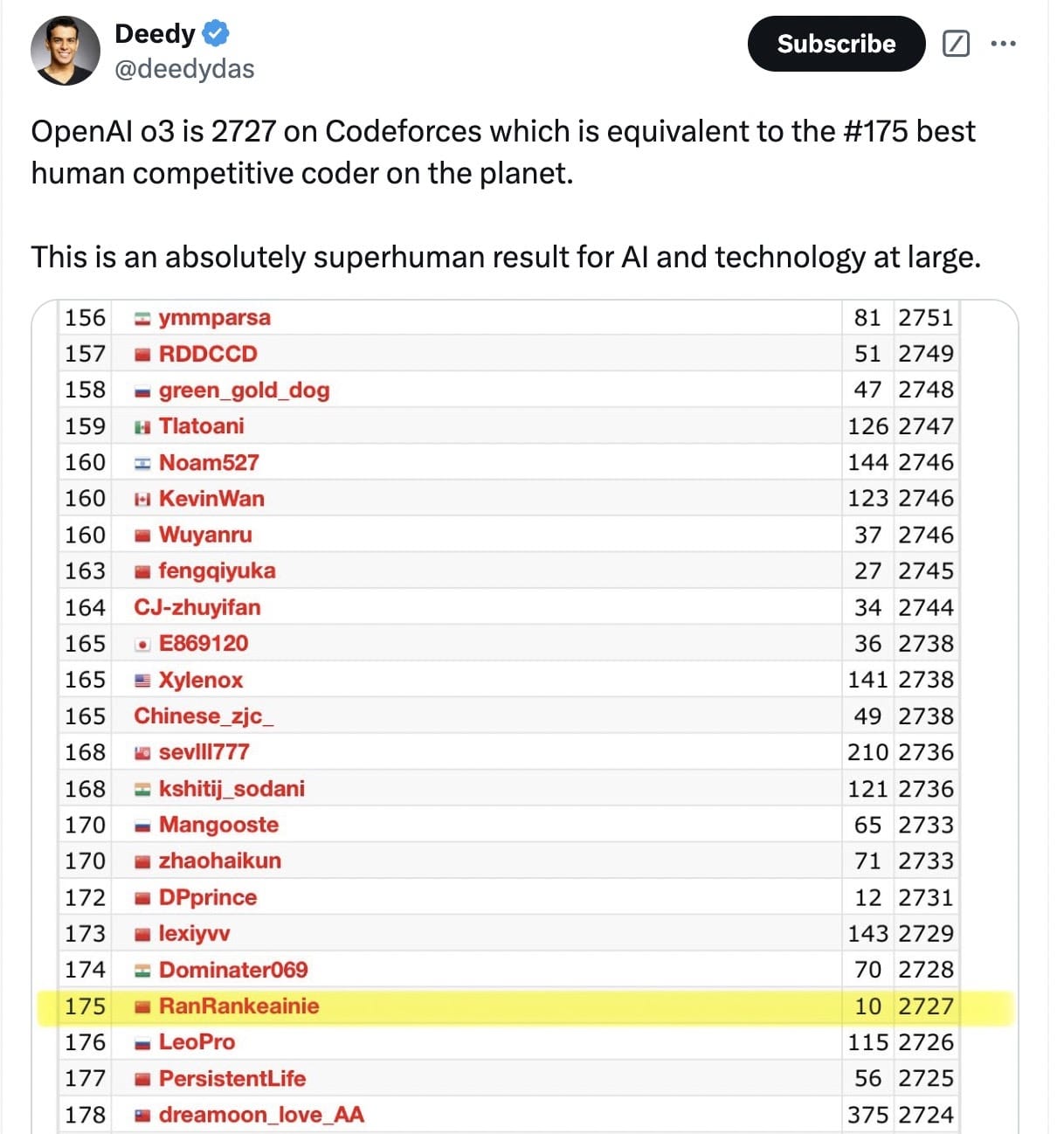
- SWE-Bench Verified:o3 的表現優於 o1 22.8 個百分點,並獲得了 2727 的 Codeforces 評級。
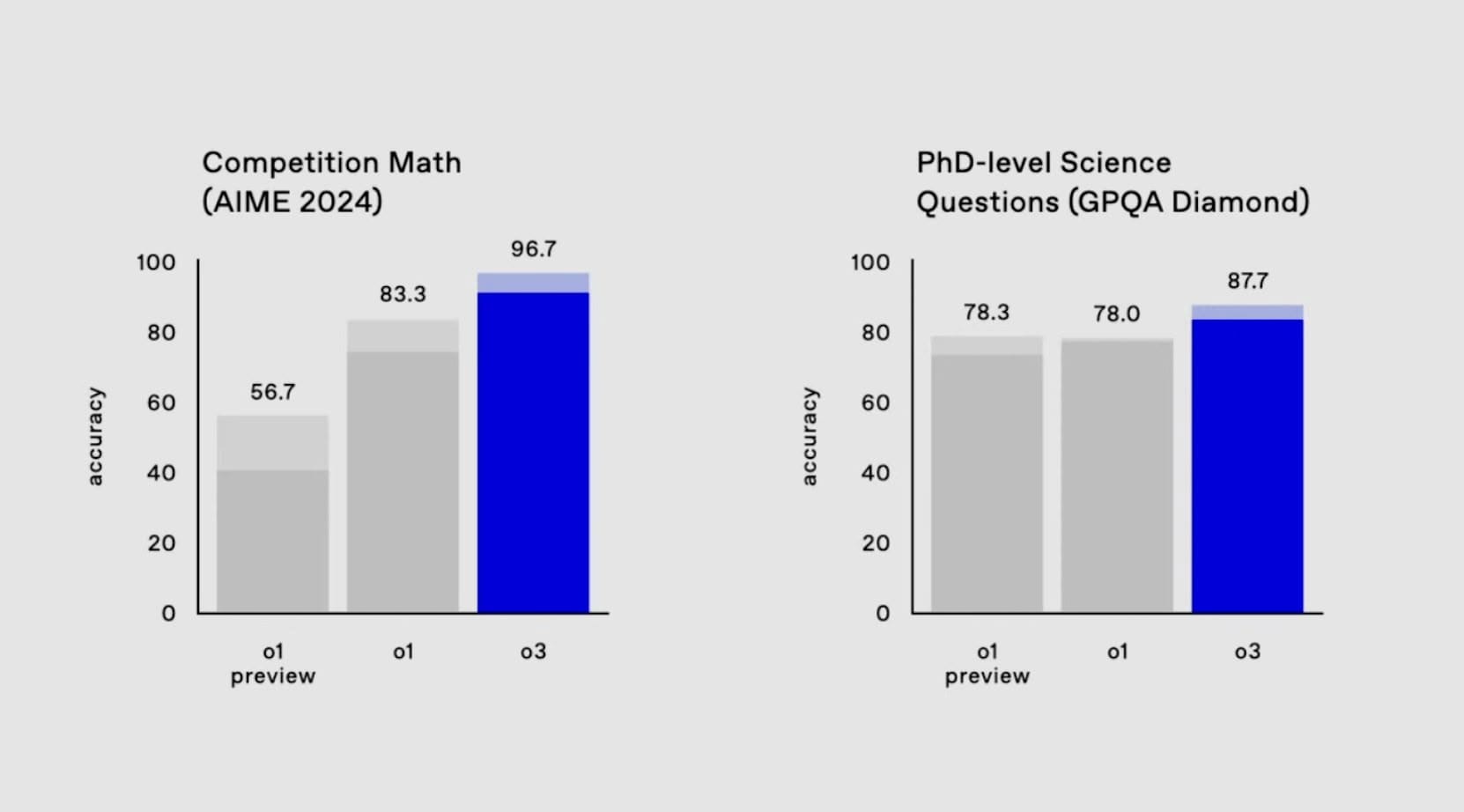
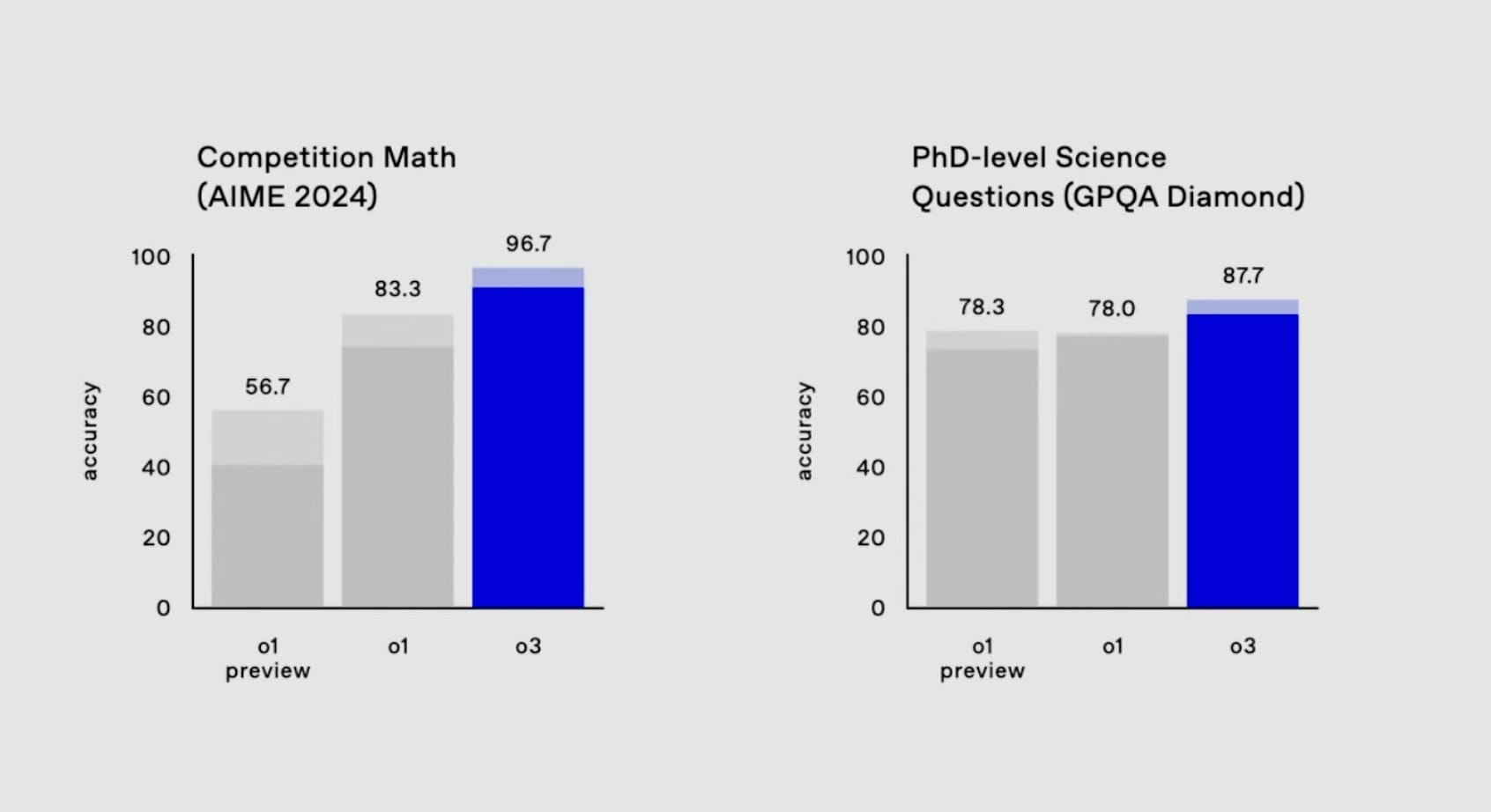
- AIME 2024:o3 獲得了 96.7% 的分數,僅錯了一個問題。
- GPQA Diamond:o3 獲得了 87.7% 的分數。
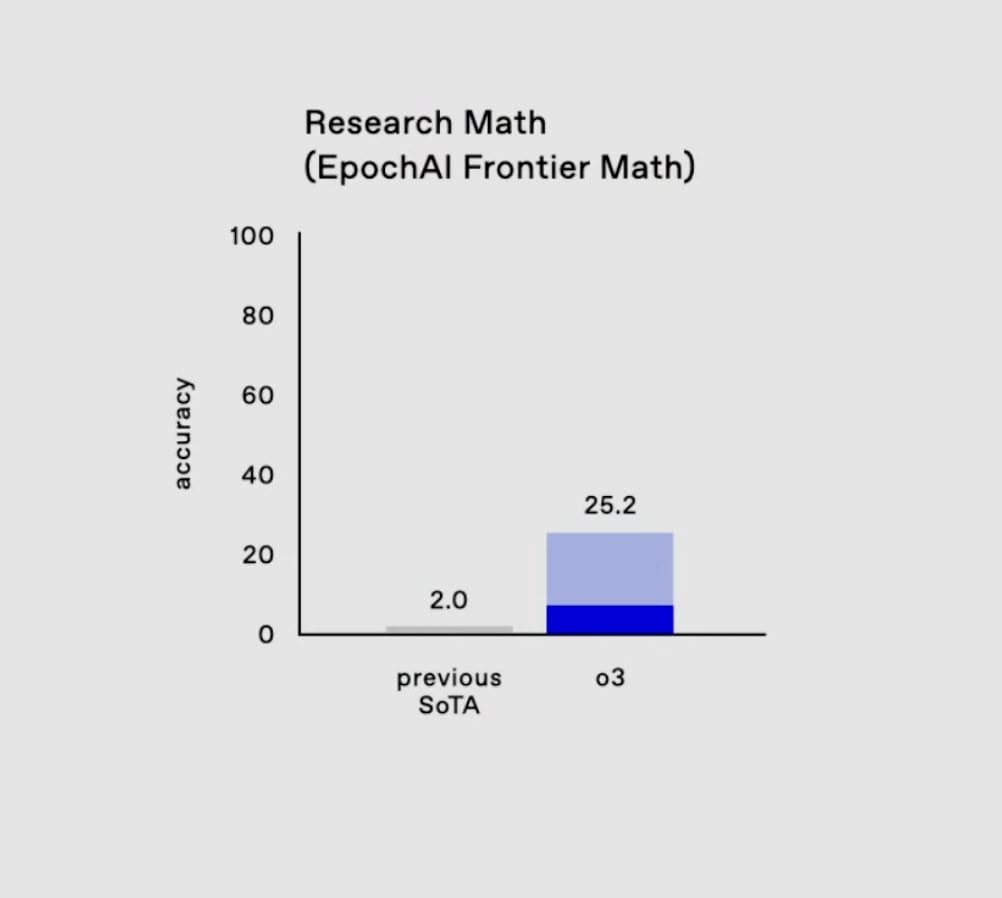
- EpochAI 的 Frontier Math:o3 解決了 25.2% 的問題,無其他模型超過 2%。
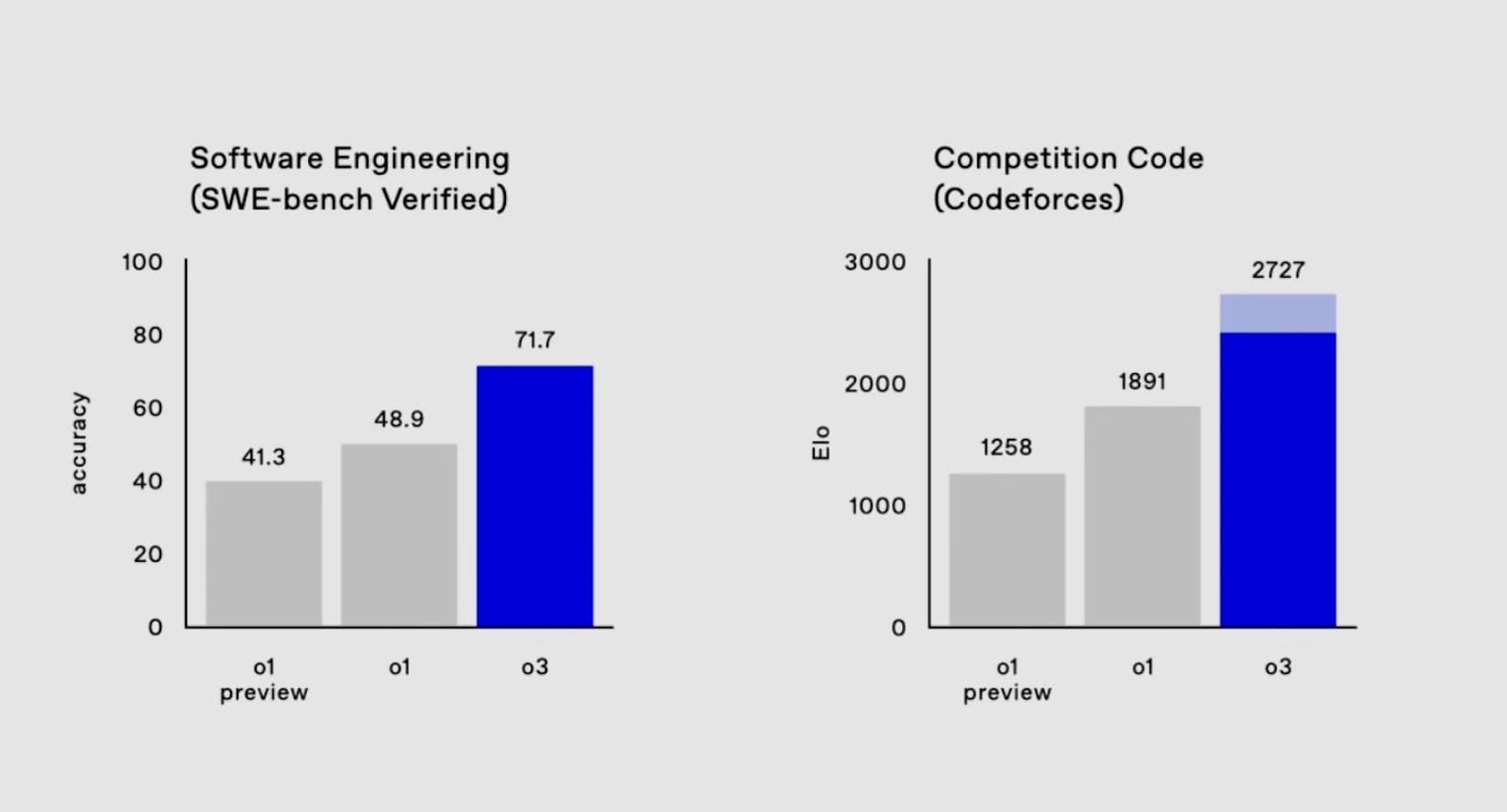
這些數據顯示,o3 在已知的最困難評估中創下了新紀錄,展示了其卓越的推理和解決問題的能力。然而,這些結果來自 OpenAI 的內部評估,尚需等待外部客戶和組織的基準測試來進一步驗證。
推理模型的未來趨勢
自 OpenAI 發布其首系列推理模型以來,競爭對手的 AI 公司紛紛推出了大量的推理模型,包括 Google。11 月初,由量化交易員資助的 AI 研究公司 DeepSeek 發布了其首個推理模型 DeepSeek-R1 的預覽版。同月,阿里巴巴 的 Qwen 團隊 公布了據稱是 o1 的首個「開放」挑戰者。
推理模型的開發動力
推理模型的興起,主要源於尋找改進生成式 AI 的新方法。這些模型能夠更有效地處理複雜的問題,提供更精確的解答。然而,並非所有人都相信推理模型是前進的最佳道路。一方面,運行這些模型需要大量的計算能力,導致其成本較高;另一方面,雖然目前它們在基準測試中表現出色,但尚不清楚推理模型能否持續保持這種進展速度。
o3 發布時的其他新聞
有趣的是,o3 的發布恰逢 OpenAI 最有成就的科學家之一 Alec Radford 離職之際。Radford 是 OpenAI「GPT 系列」生成式 AI 模型(如 GPT-3、GPT-4 等) 的主要作者,本週宣布將離開 OpenAI,轉而進行獨立研究。這一變動無疑為 OpenAI 的未來發展增添了新的變數。
結語
o3 發布時間
- o3-mini 預計將於 2024 年 1 月底推出
- 完整版 o3 的具體發布日期尚未公布,但會在 o3-mini 之後推出
成本資訊
- 低運算模式下,每個任務的成本約為 $17-20
- 高運算模式(比標準版本高 172 倍的運算能力)的成本尚未公開
主要性能提升
- 在常見程式設計任務中,準確率比 o1 提升超過 20%
- 在 ARC-AGI 評估中,低運算版本達到 75.7%,高運算版本達到 87.5% 的分數
- 在 AIME 2024 數學測驗中,準確率達到 96.7%,相比 o1 的 83.3%
新功能特點
- 可調整推理時間:提供低、中、高三種運算模式,使用者可根據需求調整思考時間
- 程式搜尋能力:採用深度學習引導的程式搜尋方式,能在執行時重組知識
- 適應性思維:能夠處理前所未見的任務,接近人類水平的表現
模型變體
- o3-mini:
- 性能略優於 o1
- 延遲和回應時間與標準模型相當
- 預計於 2024 年 1 月推出
安全性改進
- 採用深思熟慮的對齊訓練方式
- 在處理惡意提示和良性提示方面都有所改進
目前狀態
- 模型現正進行公共安全評估階段
- 安全和安全研究人員可以註冊申請預覽和評估這些模型
測試表現
• ARC-AGI 測試:o3 以低運算資源達成超越 o1 三倍以上的分數,總分突破 87%
• EpochAI 前沿數學:創下 25.2% 的解題紀錄,而其他模型均未超過 2%
• SWE-Bench 程式驗證:比 o1 提升了 22.8 個百分點
• Codeforces 競賽:達到 2727 分,超越了 OpenAI 首席科學家的 2665 分
• AIME 2024 數學競賽:驚人的 96.7% 正確率,僅錯一題
• GPQA Diamond 測試:達成 87.7% 的成績,遠超人類專家水平
OpenAI 推出的 o3 模型 無疑是人工智能領域的一大突破。其強大的推理能力、靈活的應用選項以及在多項基準測試中的優異表現,展示 OpenAI 在追求更高層次智能方面的決心與實力。
Learn more
OpenAI O3模型常見問題
- Q: O3模型與之前的模型有什麼主要區別?
- A: O3模型是OpenAI推出的最新推理模型,包含O3和O3-mini兩個子系列。相比前代模型,O3具有更強大的推理能力,可調整的推理時間,並且在多項基準測試中展現出優異的表現。
- Q: 為什麼模型命名為O3而不是O2?
- A: OpenAI選擇跳過O2的命名,直接使用O3,主要是為了避免與英國電信供應商O2可能發生的商標衝突問題。
- Q: O3模型的推理能力如何體現?
- A: O3模型通過「私有思考鏈」技術,能在回答問題前進行深度思考和推理。用戶可以根據需求將模型設定為低、中或高思考時間,思考時間越長,表現通常越好。
- Q: O3模型在基準測試中的表現如何?
- A: O3模型在多項測試中表現出色,例如在ARC-AGI測試中最高達到87.5%的分數,在AIME 2024中獲得96.7%的分數,在GPQA Diamond中達到87.7%的分數。
- Q: O3模型目前的可用性如何?
- A: O3和O3-mini目前尚未全面開放給大眾使用,但安全研究人員可以註冊預覽版本。完整版本的推出時間表尚未確定,需要等待進一步的安全測試和評估。