OpenAI 在春季更新活動中推出了其旗艦型號 GPT-4o 並向所有人免費開放。僅一天後,在 2024 年的 Google I/O 活動上,Google 通過 Gemini Advanced 推出了 Gemini 1.5 Pro 型號。現在兩款旗艦型號都可供消費者使用,讓我們來比較一下 ChatGPT 4o 和 Gemini 1.5 Pro,看看哪個表現更好。在這個背景下,讓我們開始吧。
注意:為了確保一致性,我們在 Google AI Studio 和 Gemini Advanced 上進行了所有測試。兩者均運行最新的 Gemini 1.5 Pro 型號。
AI 語言模型的演變正在革新我們與技術互動的方式。在最新的進展中,有 Google 的 Gemini 1.5 Pro 和 OpenAI 的 GPT-4 Turbo。本文深入比較了它們的功能、架構和潛在影響。
Gemini 1.5 Pro 採用專家混合(Mixture-of-Experts,MoE)架構以提高效率,使其能更熟練地處理複雜任務。GPT-4 Turbo 則繼續改進其變壓器架構,重點在於可擴展性和適應性。這兩種模型的架構選擇大大影響了它們的性能和應用範圍。
上下文窗口和長上下文理解
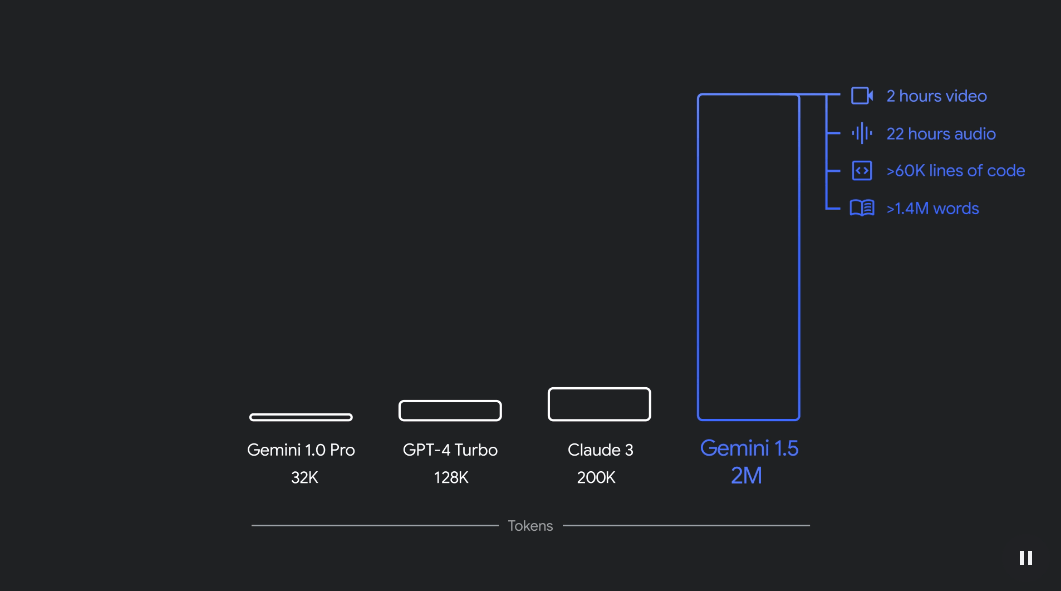
Gemini 1.5 Pro 的一個突出特點是其前所未有的 100 萬標記上下文窗口,遠遠超過 GPT-4 Turbo 的 128k 標記限制。這使得 Gemini 1.5 Pro 能夠處理和分析大量信息,提供詳細的見解和更長的上下文理解。
在分析大量文本數據集時,Gemini 1.5 Pro 展現了卓越的精確度,對 530,000 個標記保持 100% 的召回率。當擴展到 100 萬標記時,其精確度略微下降至 99.7%,對於高達 1000 萬標記的數據集,其精確度仍然保持在 99.2%。這展示了 Gemini 1.5 Pro 在準確識別和回憶跨越廣泛文本長度的特定信息方面的強大能力。
基準性能:Gemini 1.5 Pro vs GPT-4 Turbo
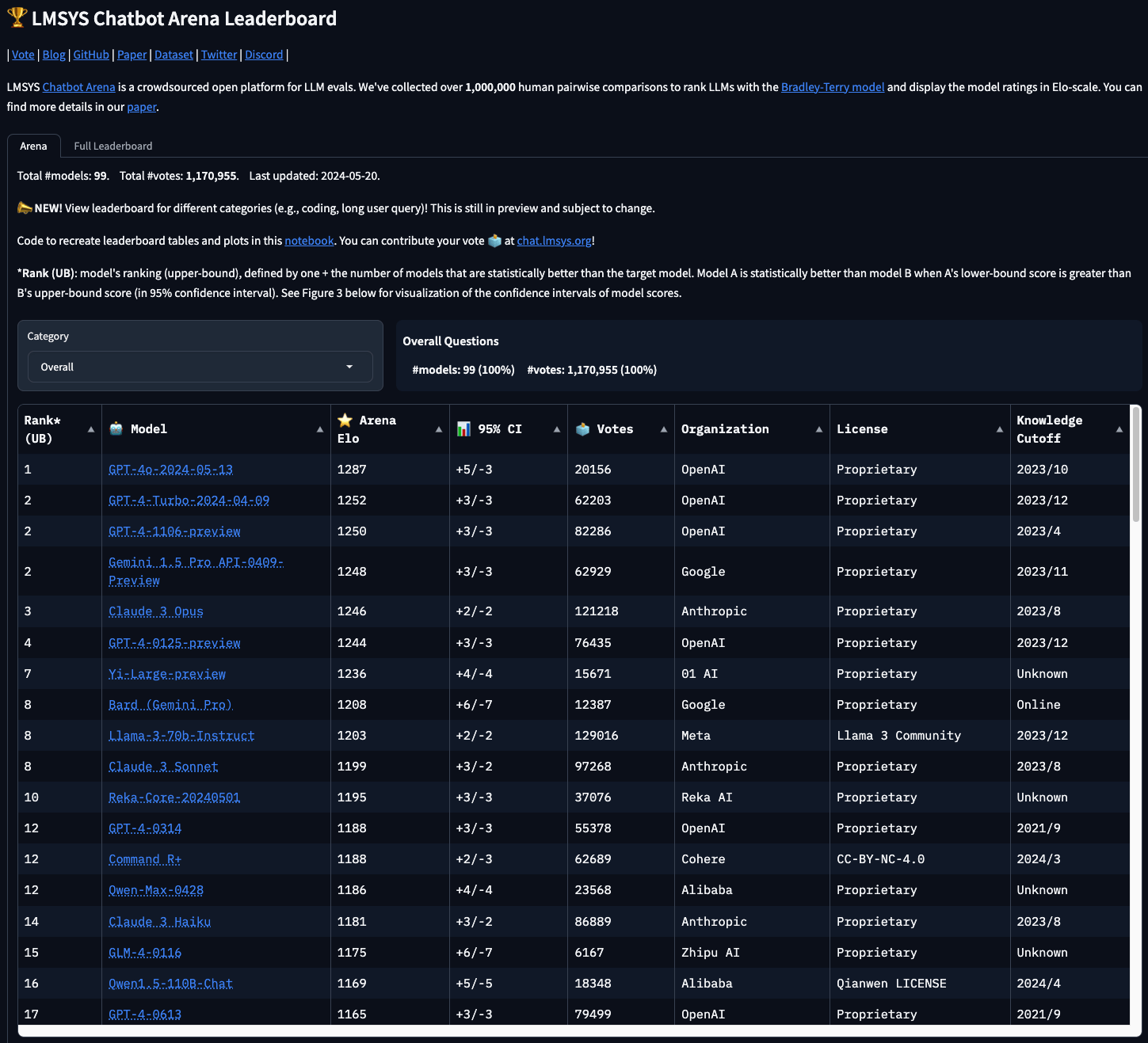
為了客觀比較 Gemini 1.5 Turbo vs GPT-4 Turbo,讓我們來看看一些主要的基準結果:
一般推理和理解
| 基準測試 | Gemini 1.5 Turbo | GPT-4 Turbo | 描述 |
|---|---|---|---|
| MMLU | 81.9% | 80.48% | 多任務語言理解 |
| Big-Bench Hard | 84.0% | 83.90% | 多步推理任務 |
| DROP | 78.9% | 83% | 閱讀理解 |
| HellaSwag | 92.5% | 96% | 日常任務的常識推理 |
數學推理
| 基準測試 | Gemini 1.5 Turbo | GPT-4 Turbo | 描述 |
|---|---|---|---|
| GSM8K | 91.7% | 92.95% | 基本算術和小學數學問題 |
| MATH | 58.5% | 54% | 高級數學問題 |
代碼生成
| 基準測試 | Gemini 1.5 Turbo | GPT-4 Turbo | 描述 |
|---|---|---|---|
| HumanEval | 71.9% | 73.17% | Python 代碼生成 |
| Natural2Code | 77.7% | 75% | Python 代碼生成,新數據集 |
圖像理解
| 基準測試 | Gemini 1.5 Turbo | GPT-4 Turbo | 描述 |
|---|---|---|---|
| VQAv2 | 73.2% | 77.2% | 自然圖像理解 |
| TextVQA | 73.5% | 78.0% | 自然圖像的 OCR |
| DocVQA | 86.5% | 88.4% | 文件理解 |
| MMMU | 58.5% | 56.8% | 多學科推理問題 |
視頻理解
| 基準測試 | Gemini 1.5 Turbo | GPT-4 Turbo | 描述 |
|---|---|---|---|
| VATEX | 63.0% | 56.0% | 英語視頻字幕 |
| Perception Test MCQA | 56.2% | 46.3% | 視頻問答 |
音頻處理
| 基準測試 | Gemini 1.5 Turbo | GPT-4 Turbo | 描述 |
|---|---|---|---|
| CoVoST 2 | 40.1% | 29.1% | 自動語音翻譯 |
| FLEURS | 6.6% | 17.6% | 自動語音識別 |
總體基準分析
一般推理和理解
- 一般推理和理解: Gemini 1.5 Pro 在一般推理和理解任務中略微超過 GPT-4 Turbo,表明其在多樣化數據集上的強大理解能力。
- 數學推理 在數學推理方面,GPT-4 Turbo 在解決複雜問題上略勝一籌,反映出其對高級數學概念的細緻理解。
- 代碼生成: GPT-4 Turbo 在代碼生成基準測試中領先,展示了其更準確地理解和生成代碼的能力,這對於開發者來說是至關重要的。
- 圖像理解: GPT-4 Turbo 在圖像理解任務中表現優越,表明其在解釋和回應視覺信息方面的先進能力。
- 視頻理解: Gemini 1.5 Pro 在視頻理解方面超越 GPT-4 Turbo,展示了其在分析和生成視頻數據內容方面的優勢。
- 音頻處理: Gemini 1.5 Pro 在音頻處理方面顯示出顯著進步,明顯超過 GPT-4 Turbo,突顯其在理解和翻譯口語語言方面的卓越能力。
從數據上來看: Gemini 1.5 Pro 比 GPT-4 Turbo 更好嗎?
Gemini 1.5 Pro 在處理大量數據集和理解複雜的多模態信息方面表現出色,這使其非常適合需要深入上下文見解的應用。而 GPT-4 Turbo 則在代碼生成、圖像理解以及需要高度精確的語言和視覺理解的任務中表現出色。這兩種模型都提供了卓越的功能,但它們的最佳應用取決於任務的具體需求。
功能和性能
GPT-4 Turbo 和 Gemini 1.5 Pro 的功能都很出色,但它們在不同的領域中各有優勢。
GPT-4 Turbo 在純文本應用中表現出色,提供細緻入微且上下文感知的文本生成,使其非常適合創意寫作、代碼協助以及複雜問題解決任務。其語言模型經過精細調整,能夠提供更準確和相關的回應,使其成為專業人士和創作者的理想工具。
Gemini 1.5 Pro 在理解和生成跨多種模態內容方面表現突出。其長上下文檢索能力具有突破性,使其能夠在更長的內容和不同類型的數據中保持連貫性。這使得 Gemini 1.5 Pro 特別適合教育環境,在這些環境中,它可以提供包含文本、圖表和視頻的解釋和教程,從而提供更全面的學習體驗。
Gemini 1.5 Pro 與 GPT-4o 應用和使用場景比較
GPT-4 Turbo 和 Gemini 1.5 Pro 的應用範圍廣泛且多樣,反映了它們各自的優勢。
- GPT-4 Turbo 已經在內容創建、客戶服務機器人和作為代碼和技術寫作助手方面部署,其文本生成能力可以顯著加快工作流程並提高輸出質量。
- Gemini 1.5 Pro 則在更複雜和細緻的應用中找到其位置,如跨模態教育平台、多語言翻譯服務需要理解文化細微差別,以及跨不同格式的大型數據集分析,用於研究目的。
1. 計算乾燥時間
我們在 ChatGPT 4o 和 Gemini 1.5 Pro 上進行了經典的推理測試,以測試它們的智慧。OpenAI 的 ChatGPT 4o 表現出色,而改進後的 Gemini 1.5 Pro 型號則在理解詭異問題時遇到了困難。它陷入了數學計算,得出了錯誤的結論。
如果在陽光下曬乾 15 條毛巾需要 1 小時,那曬乾 20 條毛巾需要多長時間?
獲勝者:ChatGPT 4o

2. 魔法電梯測試
在魔法電梯測試中,早期的 ChatGPT 4 型號未能正確猜出答案。然而這次,ChatGPT 4o 型號給出了正確的答案。Gemini 1.5 Pro 也生成了正確的答案。
有一棟高樓,裡面有一個魔法電梯。當停在偶數樓層時,這個電梯會改到一樓。從一樓開始,我乘坐魔法電梯上升 3 層。離開電梯後,我再用樓梯上升 3 層。請問我在哪一層樓?
獲勝者:ChatGPT 4o 和 Gemini 1.5 Pro

3. 找出蘋果
在這項測試中,Gemini 1.5 Pro 完全無法理解問題的細微差別。似乎 Gemini 型號不夠專注,忽略了問題的許多關鍵方面。另一方面,ChatGPT 4o 正確地說出蘋果在 地上的箱子裡。為 OpenAI 點贊!
有一個沒有底的籃子在一個箱子裡,箱子在地上。我把三個蘋果放進籃子裡,然後把籃子移到桌子上。蘋果在哪裡?
獲勝者:ChatGPT 4o

4. 哪個更重?
在這個常識推理測試中,Gemini 1.5 Pro 給出了錯誤的答案,說兩者重量相同。但 ChatGPT 4o 正確指出單位不同,因此任何材料的公斤重量都比磅重。看來改進的 Gemini 1.5 Pro 型號隨著時間的推移變得更愚笨了。
什麼更重,一公斤的羽毛還是一磅的鋼?
獲勝者:ChatGPT 4o

5. 遵循用戶指示
我要求 ChatGPT 4o 和 Gemini 1.5 Pro 生成 10 個以“芒果”結尾的句子。猜猜看?ChatGPT 4o 正確生成了所有 10 個句子,但 Gemini 1.5 Pro 只能生成 6 個這樣的句子。
在 GPT-4o 之前,只有 Llama 3 70B 能夠正確遵循用戶指示。早期的 GPT-4 型號也曾經困難重重。這意味著 OpenAI 確實改進了其型號。
生成 10 個以“芒果”結尾的句子
獲勝者:ChatGPT 4o

6. 多模態圖像測試
《深度學習小書》的作者 François Fleuret 在 ChatGPT 4o 上進行了一個簡單的圖像分析測試,並在 X(前稱 Twitter)上 分享 了結果。他現在已刪除該推文,以避免問題被過分渲染,因為他表示,這是視覺模型的一個普遍問題。

也就是說,我從我這邊在 Gemini 1.5 Pro 和 ChatGPT 4o 上進行了相同的測試,以重現結果。Gemini 1.5 Pro 表現得更差,對所有問題都給出了錯誤的答案。而 ChatGPT 4o 則給出了一個正確答案,但在其他問題上失敗了。

這表明多模態模型有許多需要改進的地方。我對 Gemini 的多模態能力特別失望,因為它的答案離正確答案很遠。
獲勝者:無
7. 字符識別測試
在另一個多模態測試中,我上傳了兩款手機(Pixel 8a 和 Pixel 8)的規格圖像。我沒有披露手機名稱,截圖中也沒有手機名稱。現在,我要求 ChatGPT 4o 告訴我應該買哪款手機。

它成功提取了截圖中的文本,比較了規格,並正確告訴我應該買 Phone 2,實際上是 Pixel 8。此外,我還要求它猜測手機,它又一次生成了正確答案——Pixel 8。

我在 Google AI Studio 上對 Gemini 1.5 Pro 進行了相同的測試。順便說一下,Gemini Advanced 尚不支持批量上傳圖像。說到結果,它完全無法提取兩個截圖中的文本,並不斷要求提供更多細節。在這樣的測試中,你會發現 Google 在實現無縫操作方面遠遠落後於 OpenAI。
獲勝者:ChatGPT 4o
8. 創建遊戲
現在來測試 ChatGPT 4o 和 Gemini 1.5 Pro 的編碼能力。我要求兩個模型創建一個遊戲。我上傳了一張 Atari Breakout 遊戲的截圖(當然,沒有透露名稱),並要求 ChatGPT 4o 用 Python 創建這個遊戲。僅僅幾秒鐘內,它就生成了整個代碼,並要求我安裝一個額外的“pygame”庫。

我用 pip 安裝了這個庫並運行了代碼。遊戲成功啟動,沒有任何錯誤。太棒了!不需要來回調試。事實上,我要求 ChatGPT 4o 改善體驗,添加一個恢復熱鍵,它很快就添加了這個功能。這真是太酷了。

接下來,我將相同的圖像上傳到 Gemini 1.5 Pro,並要求它生成這個遊戲的代碼。它生成了代碼,但運行時,窗口不停地關閉。我根本無法玩遊戲。簡而言之,在編碼任務中,ChatGPT 4o 比 Gemini 1.5 Pro 更可靠。
獲勝者:ChatGPT 4o
對 AI 未來的影響
GPT-4 Turbo 和 Gemini 1.5 Pro 所代表的進步強調了 AI 發展的快速步伐及其對人類語言和交流的日益複雜的理解能力。這些模型不僅推動了當今 AI 能夠實現的邊界,還為未來的研究和應用開辟了新的途徑。
特別是 Gemini 1.5 Pro 的多模態能力,預示著一個 AI 能夠無縫地與任何形式的信息互動的未來,打破不同類型內容之間的障礙,使數字信息對全球用戶更為易於訪問。與此同時,GPT-4 Turbo 精細的文本生成能力繼續提升我們創建和交流的能力,實現常規任務的自動化,並啟發新的創意形式。

結論
在比較 Gemini 1.5 Pro 和 GPT-4 Turbo 時,很明顯這兩個模型都代表了 AI 領域的重要成就。GPT-4 Turbo 繼續精進和提升基於文本的 AI 能力,而 Gemini 1.5 Pro 則以其多模態和長上下文理解開辟了新的前沿。這兩種模型不僅展示了當前 AI 技術的狀態,還暗示了其未來的發展方向,承諾在未來的數年中提供更加直觀、高效和多功能的 AI 工具。
從實際應用測試的結果中顯而易見,Gemini 1.5 Pro 遠遠落後於 ChatGPT 4o。即使在預覽期間改進了幾個月的 1.5 Pro 型號,仍無法與 OpenAI 的最新 GPT-4o 型號競爭。從常識推理到多模態和編碼測試,ChatGPT 4o 都表現得更加智能,並且能夠認真遵循指示。不容忽視的是,OpenAI 已經向所有人免費開放 ChatGPT 4o。
唯一對 Gemini 1.5 Pro 有利的是其龐大的上下文窗口,支持最多 100 萬個標記。此外,您還可以上傳視頻,這是一個優勢。然而,由於該模型並不十分智能,我不確定是否會有很多人僅僅因為上下文窗口更大而使用它。
在 2024 年的 Google I/O 活動上,Google 沒有宣布任何新的前沿模型。該公司仍停留在其增量的 Gemini 1.5 Pro 型號上。沒有關於 Gemini 1.5 Ultra 或 Gemini 2.0 的信息。如果 Google 想與 OpenAI 競爭,則需要實現實質性的飛躍。