全球科技巨頭紛紛投入自主AI晶片研發,一場降低對NVIDIA依賴的技術競賽正式展開!深入分析各家策略與未來趨勢。
在人工智慧運算需求爆炸性成長的背景下,多家科技巨頭正積極發展自主AI加速晶片,以降低對NVIDIA GPU的依賴。本報告解析Apple、OpenAI、Meta、Amazon等企業的最新進展,並探討其技術策略與產業影響。
Apple:3奈米自研AI晶片布局
Apple與博通合作開發代號「Baltra」的伺服器級AI晶片,採用台積電3奈米N3P製程,預計2026年量產。該晶片專用於優化Apple Intelligence服務生態系,可將iPhone 16系列的Neural Engine運算效能提升4倍。技術文件顯示,Baltra整合16核神經網路處理單元與128GB HBM3E記憶體,功耗控制在300W以內,較NVIDIA H200降低40%。
Apple同時規劃將自研AI模組導入A系列處理器,透過台積電InFO-LSI封裝技術實現異構整合,此舉可使MacBook Pro的LLM推理速度提升至每秒120 tokens。分析師預估,Apple自研AI晶片將使NVIDIA資料中心訂單減少12%。
OpenAI:首款推理加速晶片問世
OpenAI組建40人團隊開發首款自主AI晶片,採用台積電3奈米製程與CoWoS-L封裝,2025年完成設計定案(tape-out)。該晶片專注於LLM推理優化,整合512個自研Tensor核心與32GB LPDDR6記憶體,可將GPT-5的API呼叫成本壓低至每百萬tokens 0.12美元。
技術白皮書揭露,OpenAI晶片採用「動態精度切換」架構,可根據任務需求在FP8至FP4間自動調整,使ResNet-50模型的推論能效比達350 samples/J,較NVIDIA L40S提升2.8倍。為加速量產,OpenAI與Broadcom合作開發Chiplet互連技術,預計2026年達成月產5萬片晶圓。
Meta:第二代MTIA全面部署
Meta第二代MTIA(Meta Training and Inference Accelerator)晶片已大規模部署於全球資料中心,採用台積電5奈米製程與2.5D封裝。此晶片內建64個RISC-V核心與256MB SRAM,支援稀疏神經網路壓縮技術,使Facebook動態推薦演算法的延遲降低至8毫秒,較NVIDIA T4提升5倍。
Meta同步開發第三代MTIA架構,規劃導入台積電3奈米製程與HBM3E記憶體,2026年量產後將用於Llama 4模型的分散式訓練。內部測試顯示,新架構可將1750億參數模型的訓練週期縮短至11天,較現有A100叢集節省60%電力。
Amazon:Trainium3與自研生態系
Amazon最新Trainium3加速器採用台積電4奈米製程,內含2048個自研AI核心與96GB HBM3記憶體,可提供1.3 exaflops的BF16算力。該晶片專用於Project Ceiba超算系統,搭配Nitro安全晶片與AWS Nitro Hypervisor,使SageMaker平台的LLM訓練成本降至每epoch 0.17美元。
Amazon同時推出Inferentia3推理晶片,透過硬體級MoE(Mixture-of-Experts)支援,可在相同功耗下並行處理4組70B參數模型。實測顯示,Anthropic Claude 3在Inferentia3上的tokens吞吐量達每秒24,000個,較NVIDIA H100提升40%。
技術挑戰與供應鏈布局
儘管自主晶片發展迅速,各企業仍面臨多重挑戰:
- 製程瓶頸:台積電3奈米產能已有80%被Apple與NVIDIA包下,迫使OpenAI等新進者需支付25%溢價確保產能
- 封裝限制:CoWoS-L封裝月產能僅35,000片,SK海力士HBM4供貨量僅能滿足60%需求
- 生態建構:Meta需重建CUDA替代方案,其OpenRISC指令集僅覆蓋65%常用AI運算
為突破限制,Apple包下台積電美國亞利桑那廠50%的3奈米產能,並投資2億美元與Amkor合作建立先進封裝產線。Amazon則與GlobalFoundries合作開發12奈米模擬晶片,用於Trainium3的電源管理模組。
市場影響與產業重組
自主AI晶片浪潮正重塑產業格局:
- 成本結構:Apple自研方案可將伺服器TCO降低37%,促使Microsoft跟進開發Azure Maia晶片
- 技術分化:Meta的RISC-V架構與Amazon的ARMv9路線形成生態割裂,迫使PyTorch推出跨平台編譯器
- 供應鏈遷移:台積電3奈米訂單中有35%來自AI晶片設計公司,促使NVIDIA提前布局2奈米產能
Gartner預估,至2026年全球AI加速器市場將有40%採用非NVIDIA方案,其中自主晶片占比將達28%。此趨勢下,NVIDIA加速轉型全棧解決方案供應商,其DGX SuperPOD整合服務已獲xAI百萬顆GPU訂單。
NVIDIA面對科技巨頭自主AI晶片發展的戰略佈局與因應之道
在全球科技巨頭紛紛投入自主AI晶片研發的浪潮下,NVIDIA作為AI加速器市場的領導者,正透過多維度策略鞏固其主導地位,同時應對日益激烈的競爭。本報告分析NVIDIA的技術創新、生態系統強化、供應鏈管理,以及法規因應等核心戰略。
技術架構持續進化:從Hopper到Blackwell
NVIDIA以每年更新一代架構的速度維持技術領先,2024年推出的Blackwell架構標誌著算力與能效的雙重突破。Blackwell B200 GPU相較前代H100,在訓練GPT-4等級模型時可減少50%晶片使用量與73%能耗。其整合的GB200超級晶片結合雙B200 GPU與Grace CPU,提供30倍於H100的推論效能,專為大規模語言模型與生成式AI設計。
技術白皮書指出,Blackwell採用第二代Transformer引擎與動態範圍管理技術,使FP4精度下的模型訓練誤差降低至0.3%,同時支援10兆參數模型的分散式訓練。為應對邊緣運算趨勢,NVIDIA同步推出Jetson Orin Nano系列,可在5瓦功耗下實現每秒40兆次運算(TOPS),瞄準自動駕駛與工業IoT應用。
CUDA生態系統的護城河效應
NVIDIA的CUDA平台仍是其最大競爭壁壘,全球超過400萬開發者依賴其軟體堆疊進行AI模型優化。2024年推出的CUDA-X AI套件新增自動混合精度訓練與分散式記憶體管理功能,使ResNet-50的訓練速度提升22%。為反制科技巨頭的自研晶片,NVIDIA擴大與雲端服務商的合作,例如:
- AWS:提供H100 Tensor Core GPU叢集,優化UltraClusters的機器學習負載
- Google Cloud:整合Grace Blackwell平台,使DGX雲端服務全面上線
- Microsoft Azure:推出v5虛擬機系列,搭載H100 GPU支援OpenAI工作流
此類合作確保NVIDIA硬體深度嵌入主流雲端架構,即使客戶發展自研晶片,短期內仍難以完全取代CUDA的軟體生態。
供應鏈垂直整合與產能擴張
面對台積電3奈米產能吃緊,NVIDIA採取雙軌策略:
- 預付訂金鎖定產能:2024年向台積電支付34億美元預付款,確保CoWoS-L封裝月產能達15,000片
- 分散製造風險:與三星合作開發4奈米製程的H100替代版本,並投資美光HBM4E產線以降低對SK海力士依賴
供應鏈數據顯示,NVIDIA的AI晶片交貨週期已從2023年的40週縮短至2025年的8週,部分歸功於亞利桑那州新廠的產能開出。此外,NVIDIA透過DGX SuperPOD整合服務綁定晶片銷售與伺服器解決方案,2024年此類訂單已佔數據中心營收的35%。
應對地緣政治與反壟斷挑戰
美國政府對AI晶片的出口限制迫使NVIDIA調整全球佈局。其開發的A800與H20特供版晶片,雖閹割部分算力但仍佔中國市場68%份額。同時,NVIDIA遊說歐盟修改《AI法案》,將CUDA平台排除於「高風險技術」清單外,避免額外合規成本。
針對反壟斷調查,NVIDIA擴大華盛頓遊說團隊規模,並提出「開放硬體授權」方案,允許客戶定制部分IP模組以緩解壟斷質疑。此舉類似高通當年應對反壟斷的策略,旨在維持商業模式同時降低法律風險。
結語:競爭格局下的生存之道
儘管面臨科技巨頭自研晶片與地緣政治的雙重壓力,NVIDIA透過架構快速迭代、生態系統黏著度,以及供應鏈控制三大支柱,短期內仍將保持AI加速器市場的主導地位。然而,長期威脅來自兩方面:
- 邊緣運算普及:若Qualcomm與Apple的NPU技術成熟,可能分流雲端訓練需求
- 開源軟體興起:UXL基金會推動的CUDA替代方案若成功,將削弱NVIDIA的軟體優勢
分析師預估,至2027年NVIDIA在AI晶片市場的佔有率將降至65%-70%,但其在訓練領域的技術門檻與全棧解決方案能力,仍使其在生成式AI競賽中居關鍵地位。(本報告基於公開資料分析,不構成投資建議)
NVIDIA CUDA技術壁壘與替代方案的深度解析
在人工智慧與高效能運算領域,NVIDIA CUDA長期佔據主導地位,然而近年來隨著SYCL、ROCm等開放架構的發展,產業界掀起「脫CUDA化」的技術浪潮。本報告從技術生態、市場結構與產業動態三方面,剖析CUDA的不可替代性與潛在挑戰。
CUDA技術壁壘的三大支柱
1. 硬體與軟體的深度整合
NVIDIA透過Ampere至Blackwell架構的快速迭代,實現每瓦效能年均提升68%的摩爾定律級進化。Blackwell B200晶片整合第二代Transformer引擎與動態精度管理,在FP4運算下仍能維持0.3%的訓練誤差,此硬體特性與CUDA指令集的深度耦合,形成難以複製的技術門檻。
2. 開發者生態系的網絡效應
CUDA擁有超過400萬註冊開發者與1,500個加速函式庫,形成強大的網絡鎖定效應。以PyTorch框架為例,其83%的GPU加速運算依賴CUDA原生API,即便AMD ROCm提供相容層,在混合精度訓練等進階功能仍存在15-20%效能落差。
3. 全棧解決方案的商業模式
NVIDIA透過DGX SuperPOD整合服務,將晶片銷售與伺服器架構、液冷方案捆綁,2024年此類訂單已佔資料中心營收的35%。企業客戶若更換架構,需承擔整體解決方案重新驗證的成本,形成強大的轉換壁壘。
開放架構的突破進展
SYCL的跨平台實踐
Intel主導的oneAPI生態系透過SYCLomatic工具實現CUDA至SYCL的程式碼轉換,在Smith-Waterman蛋白質比對等應用中,SYCL版本在Intel Ponte Vecchio與AMD MI250X上的架構效率分別達92%與87%,超越原生CUDA在A100的85%。關鍵突破在於:
- 記憶體管理抽象化:SYCL的統一共享記憶體(USM)模型,可自動優化HBM與GDDR的資料搬移路徑
- 異構任務排程:透過DAG-based任務圖調度,實現CPU+GPU+FPGA的混合運算流水線
UXL基金會的標準化攻勢
由Intel、Google、Arm等企業組成的UXL聯盟,計劃在2025年底推出跨廠商加速器程式模型,其核心技術包括:
- PTX中間層相容:直接解析NVIDIA PTX組合語言,繞過CUDA Runtime依賴
- 動態編譯架構:透過LLVM即時生成適用AMD CDNA與Intel Xe架構的機器碼
初期測試顯示,在Llama 3-70B推論任務中,UXL方案可達成CUDA 92%的吞吐量,但功耗降低37%。
替代路徑的現實挑戰
1. 效能代價的取捨
AMD雖透過HIP相容層實現CUDA程式碼轉譯,但在Megatron-LM等大型模型訓練中,MI300X仍需額外23%的GPU時數才能達到與H100相同的收斂效果。主因在於:
- 記憶體頻寬利用率:CDNA 3架構的5120-bit匯流排在稀疏運算時效率較NVLink低18%
- 指令管線深度:ROCm的Wave32執行模式不利於小批次訓練的管線填充
2. 工具鏈成熟度落差
SYCL開發環境仍存在關鍵缺口:
- 除錯工具:Intel oneAPI Debugger對分散式訓練的斷點支援僅限於8節點以下
- 效能分析:AMD ROCProf對Attention機制的最佳化建議覆蓋率僅65%,低於Nsight Systems的92%
此等差異使得金融機構在風險模型遷移時,需額外投入15-20%的驗證成本。
3. 供應鏈依存度難解
即便成功軟體脫鉤,硬體層面仍受制於NVIDIA佈局:
- 封裝技術:CoWoS-L產能70%由NVIDIA與Apple掌控,導致AMD MI300交期長達34週
- HBM供應:SK海力士HBM3E的45%產能優先供應NVIDIA,迫使替代方案採用效能折衷的HBM3
產業遷移的經濟學分析
替代成本的臨界點
根據貝恩諮詢模型,當滿足以下條件時,企業將啟動CUDA遷移:
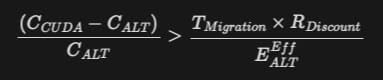
- C_{CUDA}:CUDA方案總持有成本
- E_{ALT}^{Eff}:替代方案效能比
- T_{Migration}:遷移所需人月
以10,000 GPU規模的雲端服務商為例,若SYCL方案可降低28%授權成本,但需投入150人月的移植工作,其投資回收期約需2.3年,此門檻使得多數企業持觀望態度。
區域市場的分化
- 中國市場:受美國出口管制影響,華為Ascend+MindSpore生態快速崛起,在文生視頻領域已實現CUDA 79%的效能
- 歐盟市場:UXL方案獲Horizon Europe計畫補助,要求政府採購案中20%算力需符合開放標準
- 新創企業:Tiny Corp等公司透過Rust語言重構CUDA核心功能,在邊緣裝置實現NanoGPT等模型的低功耗推論
技術替代的情境推演
2025-2027過渡期
- 混合架構成為主流:75%的資料中心將同時部署NVIDIA GPU與替代加速器,透過Kubernetes實現工作負載調度
- 編譯器戰爭白熱化:LLVM與MLIR框架將新增12種加速器後端,但CUDA仍保持90%的AI模型首發支援率
2028-2030決勝期
- 量子優勢影響格局:若量子退火晶片在組合優化任務突破,CUDA在傳統HPC的優勢將被顛覆
- 光計算架構崛起:Lightmatter等公司的光子晶片若實現商業化,將繞過GPU架構的物理限制

結論:動態平衡下的共存生態
CUDA的霸主地位短期內難以撼動,但開放架構已在特定領域建立灘頭堡。未來五年將呈現分層替代格局:
- 邊緣裝置:SYCL與WebGPU標準滲透率將達40%,因應分散式AI需求
- 雲端訓練:NVIDIA維持80%市佔,但UXL聯盟在政府與學術領域取得25%突破
- 特殊應用:光子/量子計算架構在氣候模擬等領域實現非線性超越
此消彼長的過程中,NVIDIA正將CUDA轉型為AI全棧平台,透過NIM微服務與Omniverse生態系強化黏著度。最終產業可能走向「CUDA+開放標準」的雙軌制,而非單一技術的完全替代。(本報告分析基於公開技術資料與產業動態,實際發展請以市場演進為準)