

這是一篇詳細介紹我用來運行 SaaS 的設置的文章。從負載平衡到 cron 作業監控再到支付和訂閱。有很多地面要覆蓋,所以係好安全帶!
儘管這篇文章的標題聽起來很宏大,但我應該澄清一下,我們談論的是一家壓力較小的單人公司,我在德國的公寓裡經營這家公司。完全自籌資金,我喜歡慢慢來。當我說“科技創業公司”時,這可能不是大多數人想像的那樣。
如果沒有大量開源軟件和託管服務供我使用,我將無法做到這一點。我覺得我站在巨人的肩膀上,他們在我之前做了所有的艱苦工作,對此我非常感激。
對於上下文,我運行一個單人 SaaS,這是我關於我使用的技術堆棧的帖子的更詳細版本。在聽從我的建議之前,請考慮您自己的情況,在技術選擇方面,您自己的情況很重要,沒有聖杯。
我在 AWS 上使用 Kubernetes,但不要陷入認為你需要它的陷阱。在一個非常耐心的團隊的指導下,我花了幾年時間學習了這些工具。我的工作效率很高,因為這是我最了解的,而且我可以專注於運送東西。你的旅費可能會改變。
順便說一句,我從方文斌的博文中獲得了這篇文章格式的靈感。我真的很喜歡閱讀他的文章,您可能也想看看!
話雖如此,讓我們直接進入遊覽。
目錄
- 鳥瞰圖
- 自動 DNS、SSL 和負載平衡
- 自動推出和回滾
- 讓它崩潰
- 橫向自動縮放
- CDN緩存的靜態資源
- 應用程序數據緩存
- 每個端點速率限制
- 應用管理
- 運行預定作業
- 應用配置
- 保守秘密
- 關係數據:Postgres
- 柱狀數據:ClickHouse
- 基於 DNS 的服務發現
- 版本控制的基礎設施
- 雲資源的 Terraform
- 用於應用程序部署的 Kubernetes 清單
- 訂閱和付款
- 記錄
- 監控告警
- 錯誤追踪
- 分析和其他好東西
- 這就是所有人
鳥瞰圖
我的基礎設施一次處理多個項目,但為了說明事情,我將使用我最近的 SaaS,一種網絡性能和流量分析工具,作為此設置的實際示例。
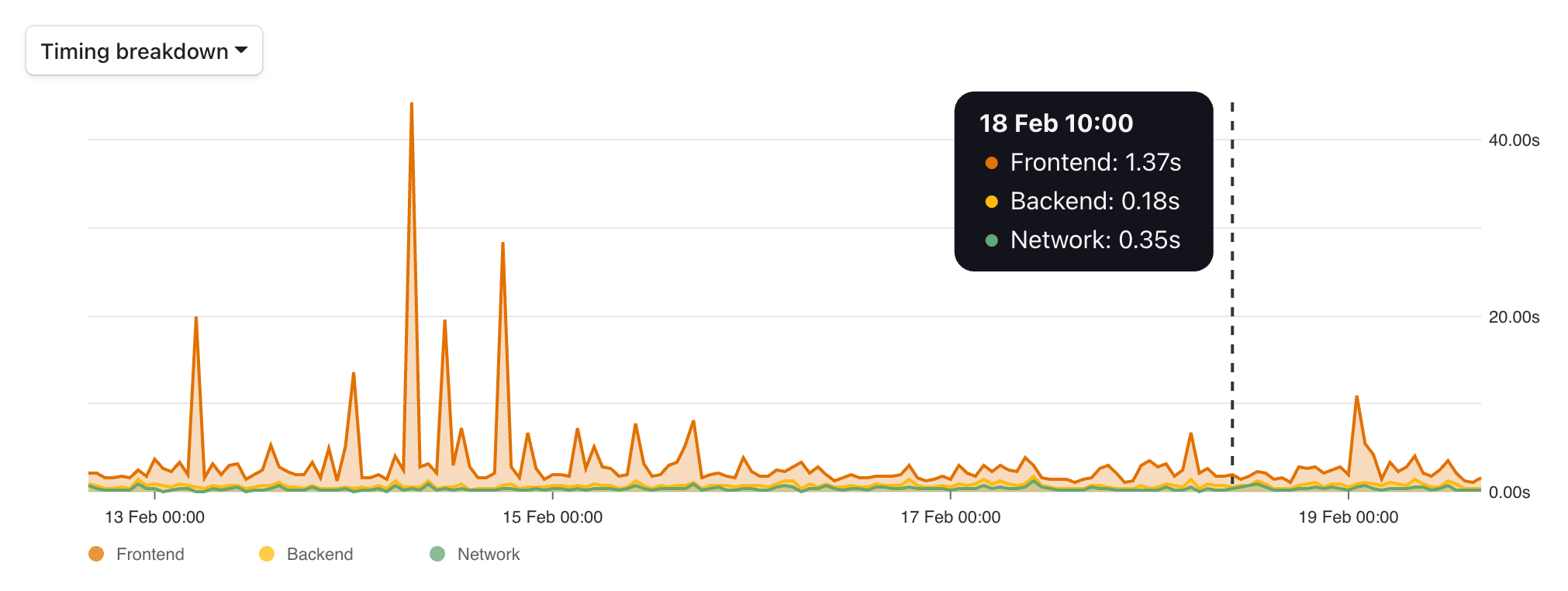 Panelbear 中的瀏覽器計時圖表,我將在本次導覽中使用的示例項目。
Panelbear 中的瀏覽器計時圖表,我將在本次導覽中使用的示例項目。
從技術的角度來看,這個 SaaS 每秒處理來自世界任何地方的大量請求,並以高效的格式存儲數據以供實時查詢。
在商業方面,它仍處於起步階段(我在六個月前推出),但它的發展速度相當快,符合我自己的期望,尤其是當我最初將它作為 Django 應用程序在單個小型 VPS 上使用 SQLite 構建時。對於我當時的目標,它工作得很好,我可能會把這個模型推得更遠。
然而,我越來越沮喪,不得不重新實現我非常習慣的許多工具:零停機部署、自動縮放、健康檢查、自動 DNS/TLS/入口規則,等等。Kubernetes 寵壞了我,我習慣於處理更高級別的抽象,同時保持控制和靈活性。
快進六個月,幾次迭代,即使我當前的設置仍然是 Django 單體,我現在使用 Postgres 作為應用程序數據庫,ClickHouse 用於分析數據,Redis 用於緩存。我還將 Celery 用於計劃任務,並使用自定義事件隊列來緩衝寫入。我在託管 Kubernetes 集群 (EKS) 上運行其中的大部分內容。
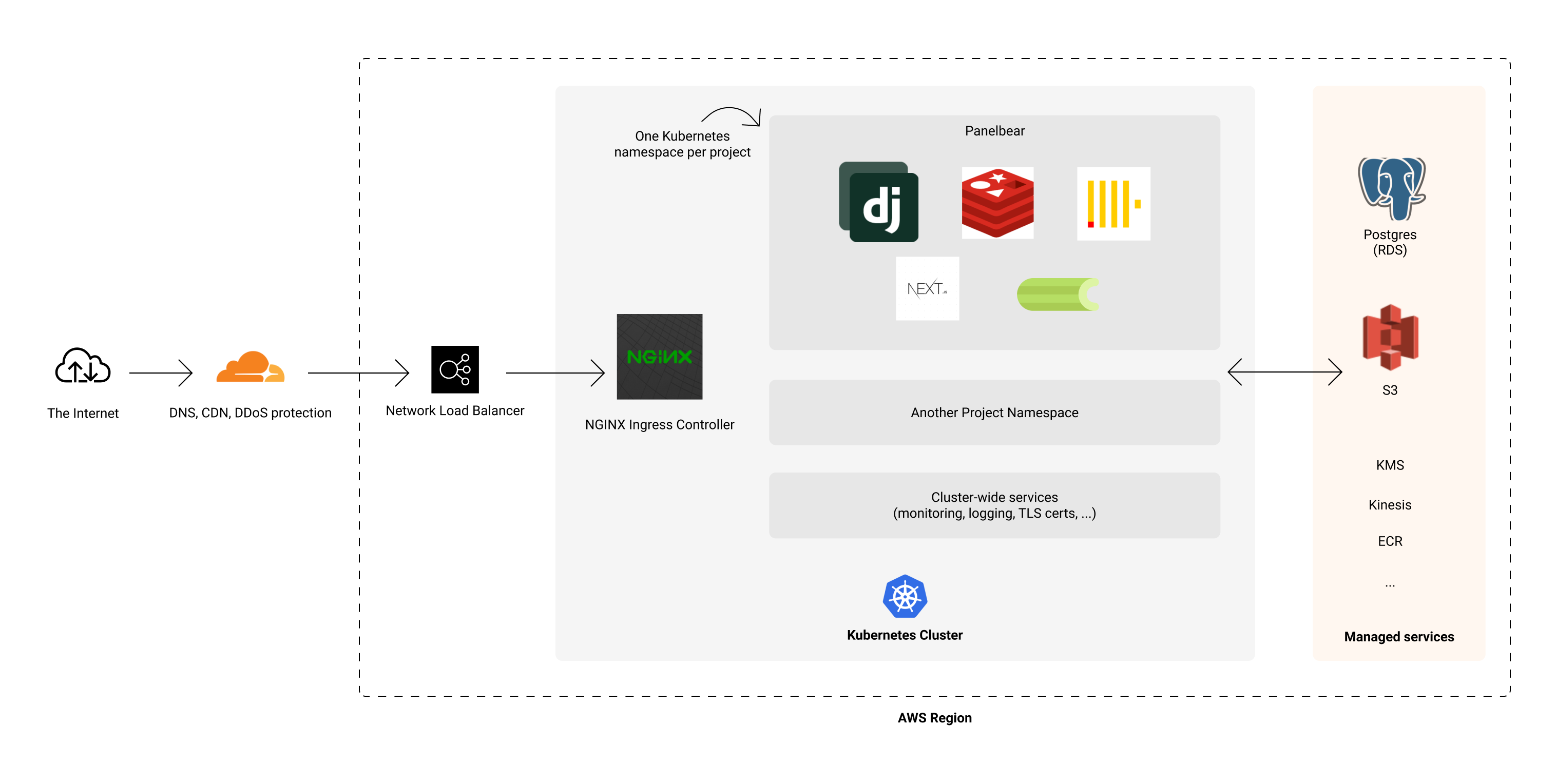 架構的高級概述。
架構的高級概述。
這聽起來可能很複雜,但它實際上是一個運行在 Kubernetes 上的老式單體架構。用 Rails 或 Laravel 替換 Django,你就會明白我在說什麼。有趣的部分是一切如何粘合在一起並實現自動化:自動縮放、入口、TLS 證書、故障轉移、日誌記錄、監控等。
值得注意的是,我在多個項目中使用此設置,這有助於降低成本並真正輕鬆地啟動實驗(編寫 Dockerfile 和 git push)。因為我經常被問到這個問題:與你的想法相反,我實際上很少花時間管理基礎設施,通常每月總共 0-2 小時。我的大部分時間都花在開發功能、提供客戶支持和發展業務上。
也就是說,這些是我多年來一直使用的工具,我對它們非常熟悉。我認為我的設置就其功能而言很簡單,但在我的日常工作中經歷了多年的生產大火才到達這裡。所以我不會說這一切都是陽光和玫瑰。
我不知道是誰先說的,但我告訴我的朋友們的是:“Kubernetes 使簡單的東西變得複雜,但它也使復雜的東西變得更簡單”。
自動 DNS、SSL 和負載平衡
既然您知道我在 AWS 上有一個託管的 Kubernetes 集群,並且我在其中運行了各種項目,那麼讓我們開始旅程的第一站:如何將流量引入集群。
我的集群位於專用網絡中,因此您無法直接從公共互聯網訪問它。在控制訪問和負載平衡集群流量之間有幾個部分。
本質上,我讓 Cloudflare 將所有流量代理到 NLB(AWS L4 網絡負載均衡器)。這個負載均衡器是公共互聯網和我的私人網絡之間的橋樑。收到請求後,它會將其轉發到 Kubernetes 集群節點之一。這些節點位於分佈在 AWS 中多個可用區的私有子網中。順便說一下,這一切都是管理的,但稍後會詳細介紹。
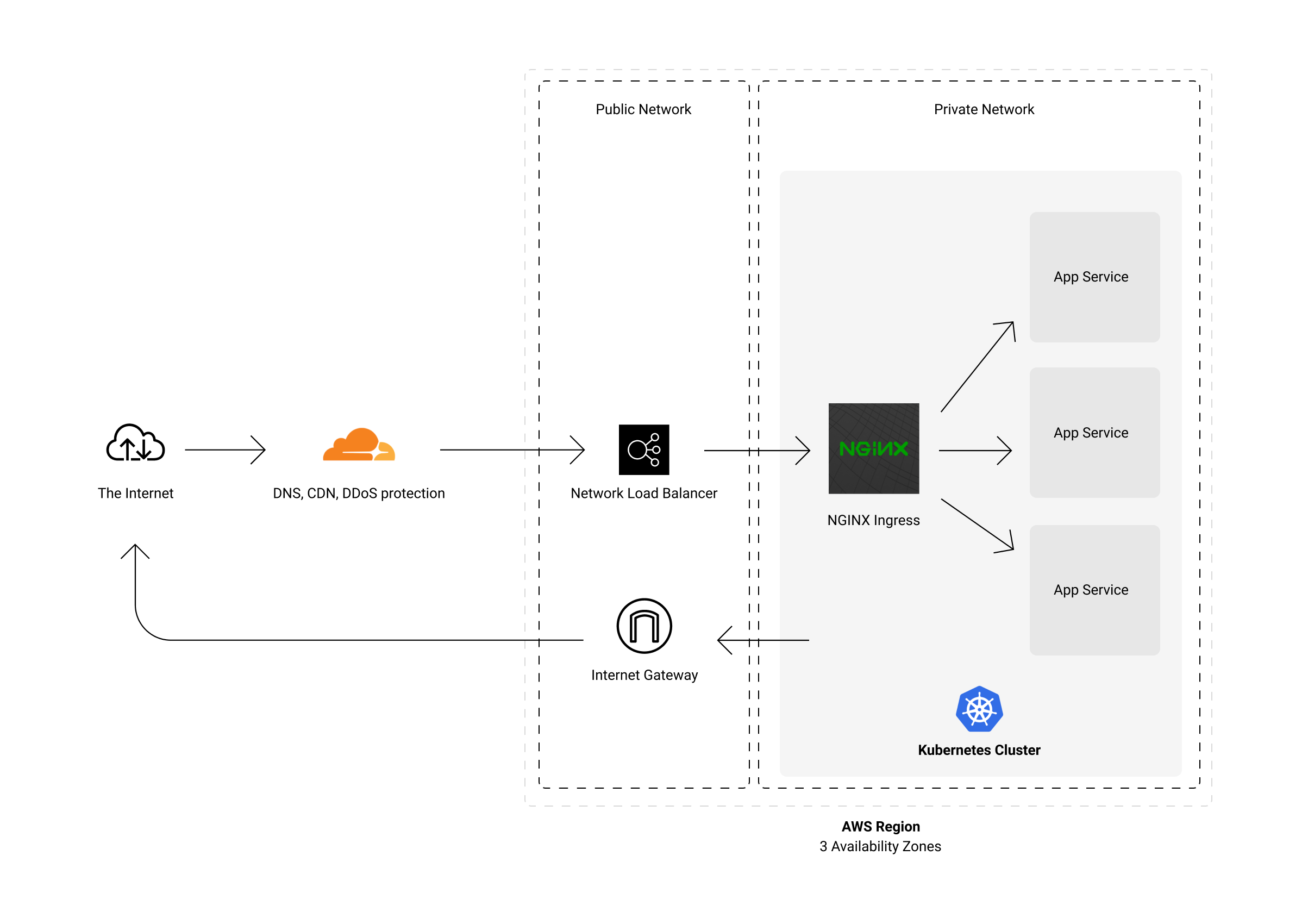 流量在邊緣緩存,或轉發到我運營的 AWS 區域。
流量在邊緣緩存,或轉發到我運營的 AWS 區域。
“但是 Kubernetes 如何知道將請求轉發到哪個服務?” – 這就是ingress-nginx 的用武之地。簡而言之:它是一個由 Kubernetes 管理的 NGINX 集群,它是集群內所有流量的入口點。
NGINX 在將請求發送到相應的應用程序容器之前應用我定義的速率限制和其他流量整形規則。在 Panelbear 的例子中,應用程序容器是由Uvicorn提供服務的 Django 。
它與 VPS 方法中的傳統 nginx/gunicorn/Django 沒有太大區別,具有額外的水平擴展優勢和自動 CDN 設置。它也是一種“設置一次就忘記”的東西,主要是 Terraform/Kubernetes 之間的一些文件,並且由所有已部署的項目共享。
當我部署一個新項目時,它基本上是 20 行入口配置,僅此而已:
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
namespace: example
name: example-api
annotations:
kubernetes.io/ingress.class: "nginx"
nginx.ingress.kubernetes.io/limit-rpm: "5000"
cert-manager.io/cluster-issuer: "letsencrypt-prod"
external-dns.alpha.kubernetes.io/cloudflare-proxied: "true"
spec:
tls:
- hosts:
- api.example.com
secretName: example-api-tls
rules:
- host: api.example.com
http:
paths:
- path: /
backend:
serviceName: example-api
servicePort: http這些註釋描述了我想要一個 DNS 記錄,流量由 Cloudflare 代理,一個通過 letsencrypt 的 TLS 證書,並且它應該在將請求轉發到我的應用程序之前通過 IP 限制每分鐘請求的速率。
Kubernetes 負責進行這些基礎設施更改以反映所需狀態。它有點冗長,但在實踐中效果很好。
自動推出和回滾
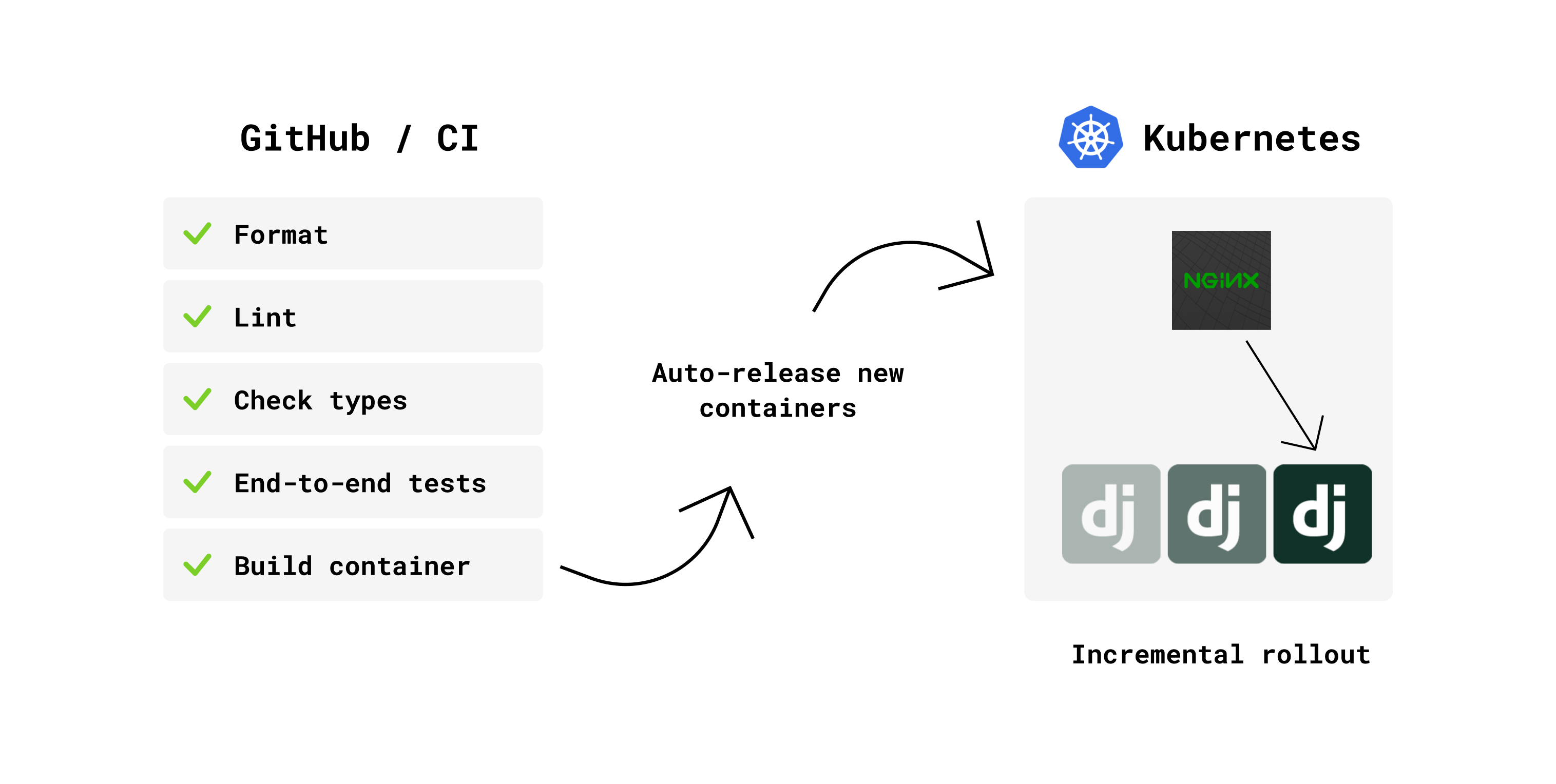 推送新提交時發生的一系列操作。
推送新提交時發生的一系列操作。
每當我推動掌握我的一個項目時,它就會在 GitHub Actions 上啟動一個 CI 管道。該管道運行一些代碼庫檢查、端到端測試(使用 Docker 組合來設置一個完整的環境),一旦這些檢查通過,它就會構建一個新的 Docker 映像,該映像被推送到 ECR(AWS 中的 Docker 註冊表)。
就應用程序 repo 而言,新版本的應用程序已經過測試,可以作為 Docker 映像部署:
panelbear/panelbear-webserver:6a54bb3“那麼接下來會發生什麼?有一個新的 Docker 鏡像,但沒有部署?” – 我的 Kubernetes 集群有一個名為flux的組件。它會自動使集群中當前運行的內容與我的應用程序的最新映像保持同步。
 Flux 自動跟踪我的基礎架構 monorepo 中的新版本。
Flux 自動跟踪我的基礎架構 monorepo 中的新版本。
當有新的 Docker 鏡像可用時,Flux 會自動觸發增量部署,並在“Infrastructure Monorepo”中記錄這些操作。
我想要版本控制的基礎設施,這樣每當我在 Terraform 和 Kubernetes 之間對這個 repo 進行新的提交時,他們就會在 AWS、Cloudflare 和其他服務上進行必要的更改,以使我的 repo 狀態與部署的內容同步。
這一切都是版本控制的,每次部署的線性歷史記錄。這意味著這些年來我要記住的東西更少了,因為我沒有通過在一些晦澀的 UI 上通過 clicky-clicky 配置的魔術設置。
將此 monorepo 視為可部署的文檔,但稍後會詳細介紹。
讓它崩潰
幾年前,我在各種公司項目中使用並發的 Actor 模型,並愛上了圍繞其生態系統的許多想法。一件事導致另一件事,很快我就開始閱讀有關 Erlang 的書籍,以及它關於讓事情崩潰的哲學。
我可能把這個想法延伸得太多了,但在 Kubernetes 中,我喜歡將活躍度探測和自動重啟視為實現類似效果的一種手段。
來自Kubernetes 文檔:“kubelet 使用活性探測來了解何時重啟容器。例如,活性探測可能會發現應用程序正在運行但無法取得進展的死鎖。在這種狀態下重新啟動容器有助於使應用程序更可用,儘管存在錯誤。”
在實踐中,這對我來說效果很好。容器和節點注定要來來去去,而 Kubernetes 將優雅地將流量轉移到健康的 pod,同時治愈不健康的 pod(更像是殺死)。殘酷,但有效。
橫向自動縮放
我的應用程序容器根據 CPU/內存使用情況自動縮放。Kubernetes 將嘗試為每個節點打包盡可能多的工作負載以充分利用它。
如果集群中每個節點的 Pod 過多,它將自動生成更多服務器以增加集群容量並減輕負載。同樣,當沒有太多事情發生時,它會縮小。
下面是 Horizontal Pod Autoscaler 的樣子:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: panelbear-api
namespace: panelbear
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: panelbear-api
minReplicas: 2
maxReplicas: 8
targetCPUUtilizationPercentage: 50panelbear-api在此示例中,它會根據 CPU 使用率自動調整 pod 的數量,從 2 個副本開始,但上限為 8 個。
CDN緩存的靜態資源
在為我的應用程序定義入口規則時,註釋cloudflare-proxied: "true"告訴 Kubernetes 我想使用 Cloudflare 進行 DNS,並通過它的 CDN 和 DDoS 保護代理所有請求。
從那時起,使用它就非常容易了。我只是在我的應用程序中設置標準的 HTTP 緩存標頭,以指定可以緩存哪些請求以及緩存多長時間。
# Cache this response for 5 minutes
response["Cache-Control"] = "public, max-age=300"Cloudflare 將使用這些響應標頭來控制邊緣服務器的緩存行為。對於如此簡單的設置,它的效果非常好。
我使用Whitenoise直接從我的應用程序容器提供靜態文件。這樣我就不需要在每次部署時將靜態文件上傳到 Nginx/Cloudfront/S3。到目前為止,它工作得非常好,大多數請求將在 CDN 被填充時被緩存。它具有高性能,並使事情變得簡單。
我也將 NextJS 用於一些靜態網站,例如Panelbear的登陸頁面。我可以通過 Cloudfront/S3 甚至 Netlify 或 Vercel 為它提供服務,但很容易將它作為我的集群中的容器運行,並讓 Cloudflare 在請求時緩存靜態資產。這樣做對我來說是零附加成本,而且我可以重新使用所有工具進行部署、日誌記錄和監控。
應用程序數據緩存
除了靜態文件緩存之外,還有應用程序數據緩存(例如繁重計算的結果、Django 模型、限速計數器等…)。
一方面,我利用內存中的最近最少使用 (LRU) 緩存將經常訪問的對象保存在內存中,並且我將從零網絡調用中受益(純 Python,不涉及 Redis)。
但是,大多數端點僅使用集群內的 Redis 進行緩存。它仍然很快,緩存的數據可以由所有 Django 實例共享,即使在重新部署之後,內存中的緩存也會被擦除。
這是一個真實的例子:
我的定價計劃基於每月的分析事件。為此,需要某種計量來了解在當前計費周期內消耗了多少事件並強制執行限制。但是,當客戶超過限制時,我不會立即中斷服務。相反,系統會自動發送“容量耗盡”電子郵件,並在 API 開始拒絕新數據之前為客戶提供寬限期。
這是為了讓客戶有足夠的時間來決定升級是否對他們有意義,同時確保沒有數據丟失。例如,在流量高峰期間,以防他們的內容傳播開來,或者如果他們只是享受週末而不查看電子郵件。如果客戶決定保留當前計劃而不升級,則不會受到任何處罰,一旦使用量回到計劃限制內,一切都會恢復正常。
因此,對於此功能,我有一個應用上述規則的函數,它需要多次調用 DB 和 ClickHouse,但緩存 15 分鐘以避免在每次請求時重新計算。它足夠好而且簡單。值得注意的是:緩存在計劃更改時失效,否則升級可能需要 15 分鐘才能生效。
@cache(ttl=60 * 15)
def has_enough_capacity(site: Site) -> bool:
"""
Returns True if a Site has enough capacity to accept incoming events,
or False if it already went over the plan limits, and the grace period is over.
"""每個端點速率限制
雖然我在 Kubernetes 上的 nginx-ingress 強制執行全局速率限制,但有時我希望在每個端點/方法的基礎上進行更具體的限制。
為此,我使用優秀的Django Ratelimit庫來輕鬆聲明每個 Django 視圖的限制。它被配置為使用 Redis 作為後端來跟踪向每個端點發出請求的客戶端(它存儲基於客戶端密鑰的哈希值,而不是 IP)。
例如:
class MySensitiveActionView(RatelimitMixin, LoginRequiredMixin):
ratelimit_key = "user_or_ip"
ratelimit_rate = "5/m"
ratelimit_method = "POST"
ratelimit_block = True
def get():
...
def post():
...在上面的示例中,如果客戶端每分鐘嘗試 POST 到此特定端點超過 5 次,則後續調用將被拒絕並返回HTTP 429 Too Many Requests狀態代碼。
 速率受限時收到的友好錯誤消息。
速率受限時收到的友好錯誤消息。
應用管理
Django 為我的所有模型免費提供了一個管理面板。它是內置的,對於在旅途中檢查客戶支持工作的數據非常方便。
 Django 的內置管理面闆對於隨時隨地提供客戶支持非常有用。
Django 的內置管理面闆對於隨時隨地提供客戶支持非常有用。
我添加了操作來幫助我從 UI 管理事物。諸如阻止對可疑帳戶的訪問、發送公告電子郵件和批准完整帳戶刪除請求(首先是軟刪除,然後在 72 小時內完全銷毀)之類的事情。
安全方面:只有員工用戶才能訪問面板(我),我計劃添加 2FA 以提高所有帳戶的安全性。
此外,每次用戶登錄時,我都會向該帳戶的電子郵箱發送一封自動安全電子郵件,其中包含有關新會話的詳細信息。現在我會在每次新登錄時發送它,但將來我可能會更改它以跳過已知設備。這不是一個非常“MVP 功能”,但我關心安全性並且添加起來並不復雜。至少如果有人登錄我的帳戶,我會收到警告。
當然,加固應用程序的方法遠不止於此,但這超出了本文的範圍。
 您在登錄時可能會收到的示例安全活動電子郵件。
您在登錄時可能會收到的示例安全活動電子郵件。
運行預定作業
另一個有趣的用例是我運行許多不同的計劃作業作為我的 SaaS 的一部分。這些事情包括為我的客戶生成每日報告、每 15 分鐘計算一次使用情況統計數據、向員工發送電子郵件(我每天都會收到一封包含最重要指標的電子郵件)等等。
我的設置實際上非常簡單,我只有幾個 Celery worker 和一個 Celery beat 調度程序在集群中運行。它們被配置為使用 Redis 作為任務隊列。我花了一個下午來設置一次,幸運的是到目前為止我沒有遇到任何問題。
當計劃任務未按預期運行時,我想通過 SMS/Slack/Email 收到通知。例如,當每週報告任務卡住或明顯延遲時。為此,我使用Cronitor.io。
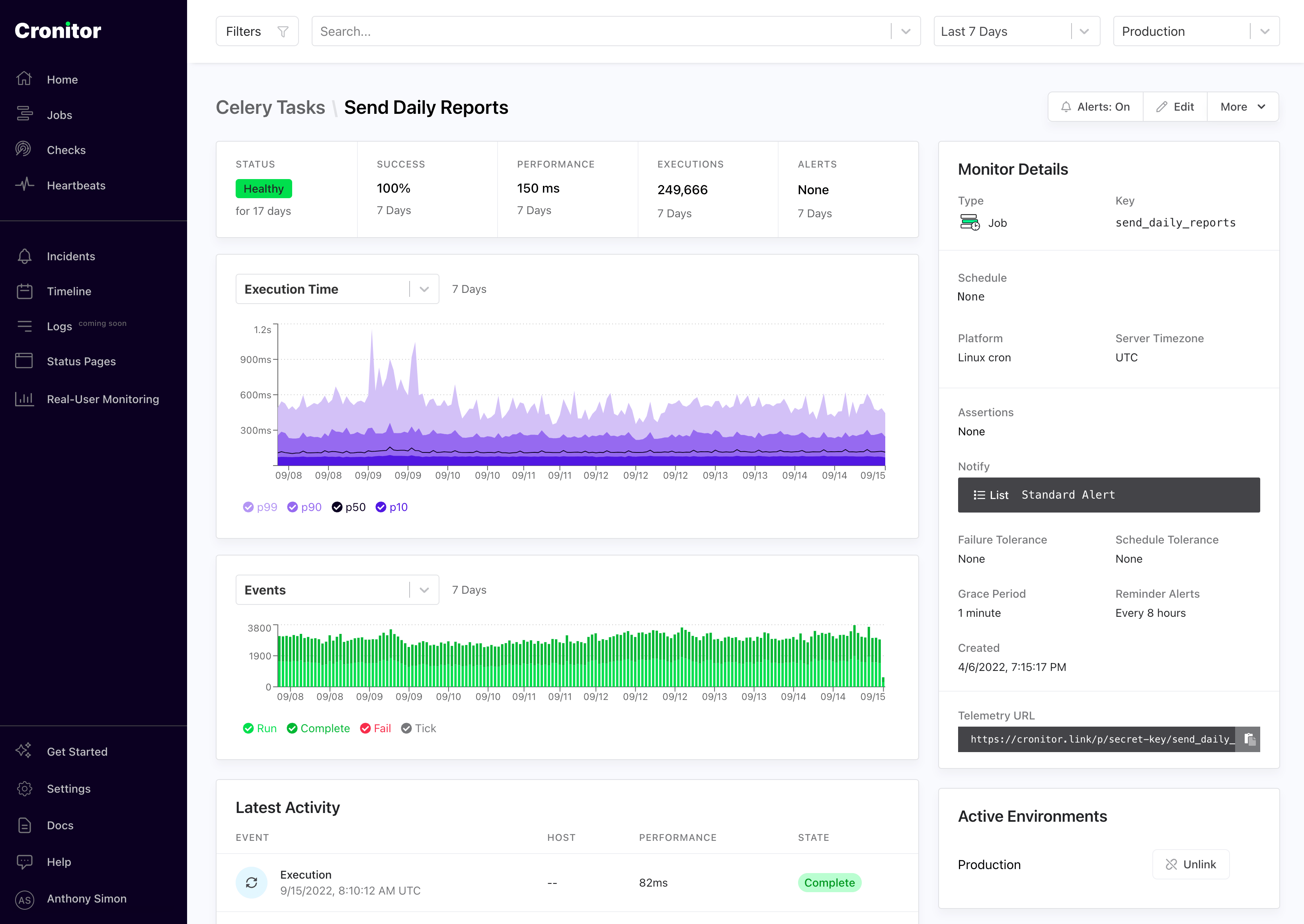 來自 Cronitor.io 的 cron 作業監控儀表板
來自 Cronitor.io 的 cron 作業監控儀表板
celery監控集成使得檢測我的計劃任務變得非常容易:
# Auto-discovers celery beat tasks
import cronitor.celery
from celery import Celery
app = Celery()
cronitor.celery.initialize(app, api_key="super-secret", celerybeat_only=True)應用配置
我所有的應用程序都是通過環境變量配置的,老派但便攜且支持良好。例如,在我的 Django 中,settings.py我設置了一個具有默認值的變量:
INVITE_ONLY = env.str("INVITE_ONLY", default=False)並在我的代碼中的任何地方使用它,如下所示:
from django.conf import settings
# If invite-only, then disable account creation endpoints
if settings.INVITE_ONLY:
...我可以覆蓋我的 Kubernetes 中的環境變量configmap:
apiVersion: v1
kind: ConfigMap
metadata:
namespace: panelbear
name: panelbear-webserver-config
data:
INVITE_ONLY: "True"
DEFAULT_FROM_EMAIL: "The Panelbear Team "
SESSION_COOKIE_SECURE: "True"
SECURE_HSTS_PRELOAD: "True"
SECURE_SSL_REDIRECT: "True" 保守秘密
處理機密的方式非常有趣:我還想將它們與其他配置文件一起提交到我的基礎設施存儲庫,但機密應該加密。
為此,我在 Kubernetes 中使用了kubeseal。該組件使用非對稱加密來加密我的秘密,只有授權訪問解密密鑰的集群才能解密它們。
例如,您可能會在我的基礎架構回購中找到以下內容:
apiVersion: bitnami.com/v1alpha1
kind: SealedSecret
metadata:
name: panelbear-secrets
namespace: panelbear
spec:
encryptedData:
DATABASE_CONN_URL: AgBy3i4OJSWK+PiTySYZZA9rO43cGDEq...
SESSION_COOKIE_SECRET: oi7ySY1ZA9rO43cGDEq+ygByri4OJBlK...
...集群會自動解密secret,並作為環境變量傳遞給對應的容器:
DATABASE_CONN_URL='postgres://user:pass@my-rds-db:5432/db'
SESSION_COOKIE_SECRET='this-is-supposed-to-be-very-secret'為了保護集群內的秘密,我通過KMS使用 AWS 管理的加密密鑰,這些密鑰會定期輪換。這是創建 Kubernetes 集群時的單一設置,並且是完全託管的。
從操作上講,這意味著我將機密作為環境變量寫入 Kubernetes 清單中,然後在提交之前運行命令對其進行加密,並推送我的更改。
這些秘密在幾秒鐘內部署完畢,集群將在運行我的容器之前自動解密它們。
關係數據:Postgres
為了進行實驗,我在集群中運行了一個 vanilla Postgres 容器,以及一個每天備份到 S3 的 Kubernetes cronjob。這有助於降低我的成本,而且對於剛開始的人來說非常簡單。
然而,隨著項目的增長,比如 Panelbear,我將數據庫從集群中移出到 RDS 中,並讓 AWS 負責加密備份、安全更新和所有其他不會搞砸的事情。
為了增加安全性,AWS 管理的數據庫仍然部署在我的私有網絡中,因此無法通過公共互聯網訪問它們。
柱狀數據:ClickHouse
我依靠ClickHouse對 Panelbear 中的分析數據進行高效存儲和(軟)實時查詢。這是一個很棒的列式數據庫,速度快得令人難以置信,而且當您很好地構建數據時,您可以獲得高壓縮比(更少的存儲成本 = 更高的利潤)。
我目前在我的 Kubernetes 集群中自行託管一個 ClickHouse 實例。我使用帶有由 AWS 管理的加密卷密鑰的 StatefulSet。我有一個 Kubernetes CronJob,它以高效的柱狀格式定期將所有數據備份到 S3。在災難恢復的情況下,我有幾個腳本可以手動備份和恢復 S3 中的數據。
到目前為止,ClickHouse 一直堅如磐石,是一款令人印象深刻的軟件。這是我開始使用 SaaS 時唯一不熟悉的工具,但多虧了他們的文檔,我才能夠快速啟動和運行。
我認為如果我想獲得更多性能(例如,優化字段類型以獲得更好的壓縮、預計算物化表和調整實例類型),有很多容易實現的目標,但現在已經足夠了。
基於 DNS 的服務發現
除了 Django,我還為 Redis、ClickHouse、NextJS 等運行容器。這些容器必須以某種方式相互通信,而這就是通過 Kubernetes 中內置的服務發現實現的。
非常簡單:我為容器定義一個服務資源,Kubernetes 自動管理集群內的 DNS 記錄,以將流量路由到相應的服務。
例如,給定集群中公開的 Redis 服務:
apiVersion: v1
kind: Service
metadata:
name: redis
namespace: weekend-project
labels:
app: redis
spec:
type: ClusterIP
ports:
- port: 6379
selector:
app: redis我可以通過以下 URL 從我的集群的任何地方訪問這個 Redis 實例:
redis://redis.weekend-project.svc.cluster:6379請注意,服務名稱和項目名稱空間是 URL 的一部分。這使得所有集群服務之間的通信變得非常容易,無論它們在集群中的哪個位置運行。
例如,下面是我如何通過環境變量配置 Django 以使用我的集群內 Redis:
apiVersion: v1
kind: ConfigMap
metadata:
name: panelbear-config
namespace: panelbear
data:
CACHE_URL: "redis://redis.panelbear.svc.cluster:6379/0"
ENV: "production"
...Kubernetes 會自動保持 DNS 記錄與健康的 pod 同步,即使容器在自動縮放期間跨節點移動也是如此。這在幕後的工作方式非常有趣,但超出了本文的範圍。如果您覺得有趣,這裡有一個很好的解釋。
版本控制的基礎設施
我想要版本控制的、可複制的基礎設施,我可以用一些簡單的命令創建和銷毀它。
為實現這一目標,我在包含所有基礎設施的單一存儲庫中使用 Docker、Terraform 和 Kubernetes 清單,甚至跨多個項目。對於每個應用程序/項目,我使用一個單獨的 git 存儲庫,但這段代碼不知道它將運行的環境。
如果您熟悉十二因素應用程序,這種分離可能會敲響一兩下鐘。本質上,我的應用程序並不知道它將在其上運行的確切基礎設施,而是通過環境變量進行配置的。
通過在 git 存儲庫中描述我的基礎設施,我不需要跟踪一些晦澀的 UI 中的每一個小資源和配置設置。這使我能夠在災難恢復的情況下使用單個命令恢復我的整個堆棧。
這是您可能會在 infra monorepo 上找到的示例文件夾結構:
# Cloud resources
terraform/
aws/
rds.tf
ecr.tf
eks.tf
lambda.tf
s3.tf
roles.tf
vpc.tf
cloudflare/
projects.tf
# Kubernetes manifests
manifests/
cluster/
ingress-nginx/
external-dns/
certmanager/
monitoring/
apps/
panelbear/
webserver.yaml
celery-scheduler.yaml
celery-workers.yaml
secrets.encrypted.yaml
ingress.yaml
redis.yaml
clickhouse.yaml
another-saas/
my-weekend-project/
some-ghost-blog/
# Python scripts for disaster recovery, and CI
tasks/
...
# In case of a fire, some help for future me
README.md
DISASTER.md
TROUBLESHOOTING.md這種設置的另一個優點是所有移動的部件都在一個地方描述。我可以配置和管理可重複使用的組件,例如集中式日誌記錄、應用程序監控和加密機密等。
雲資源的 Terraform
我使用Terraform來管理大部分底層雲資源。這有助於我記錄並跟踪構成我的基礎架構的資源和配置。在災難恢復的情況下,我可以使用單個命令啟動和回滾資源。
例如,這是我的 Terraform 文件之一,用於為 30 天后過期的加密備份創建私有 S3 存儲桶:
resource "aws_s3_bucket" "panelbear_app" {
bucket = "panelbear-app"
acl = "private"
tags = {
Name = "panelbear-app"
Environment = "production"
}
lifecycle_rule {
id = "backups"
enabled = true
prefix = "backups/"
expiration {
days = 30
}
}
server_side_encryption_configuration {
rule {
apply_server_side_encryption_by_default {
sse_algorithm = "AES256"
}
}
}
}用於應用程序部署的 Kubernetes 清單
同樣,我所有的 Kubernetes 清單都在基礎設施 monorepo 中的 YAML 文件中進行了描述。我將它們分成兩個目錄:cluster和apps.
在目錄中cluster,我描述了所有集群範圍的服務和配置,例如 nginx-ingress、加密的秘密、prometheus scrapers 等。本質上是可重用的位。
另一方面,該apps目錄包含每個項目一個命名空間,描述部署它所需的內容(入口規則、部署、機密、卷等)。
Kubernetes 的一個很酷的事情是,您可以自定義堆棧的幾乎所有內容。因此,例如,如果我想使用可以調整大小的加密 SSD 卷,我可以在集群中定義一個新的“StorageClass”。Kubernetes 和在這種情況下的 AWS 將協調並為我實現奇蹟。例如:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: encrypted-ssd
provisioner: kubernetes.io/aws-ebs
parameters:
type: gp2
encrypted: "true"
reclaimPolicy: Retain
allowVolumeExpansion: true
volumeBindingMode: WaitForFirstConsumer我現在可以繼續為我的任何部署附加這種類型的持久存儲,Kubernetes 將為我管理請求的資源:
# Somewhere in the ClickHouse StatefulSet configuration
...
storageClassName: encrypted-ssd
resources:
requests:
storage: 250Gi
...訂閱和付款
我使用Stripe Checkout來省去處理付款、創建結賬屏幕、處理信用卡的 3D 安全要求,甚至是客戶賬單門戶的所有工作。
我無法訪問支付信息本身,這讓我鬆了一口氣,使我能夠專注於我的產品,而不是信用卡處理和欺詐預防等高度敏感的話題。
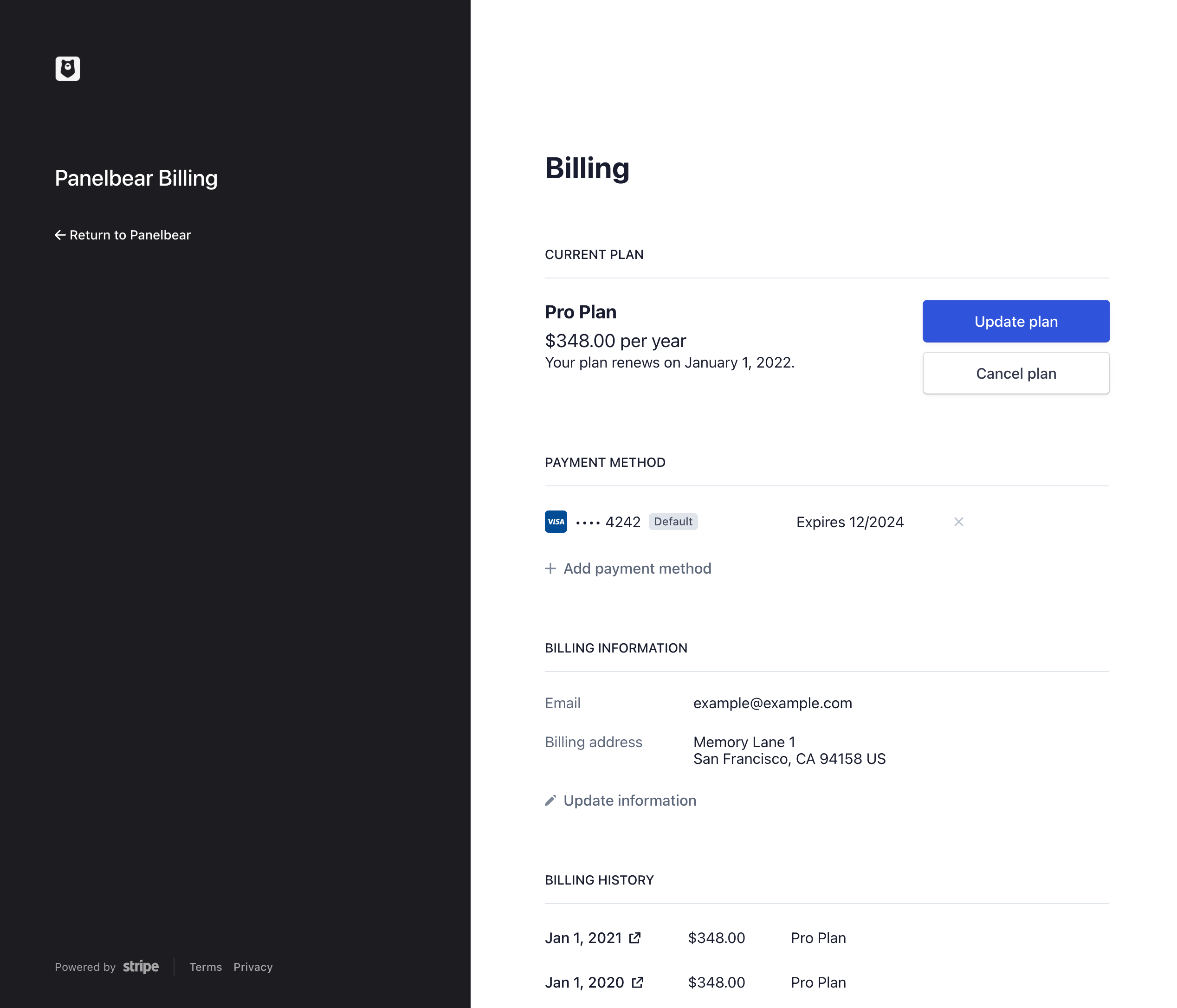 Panelbear 中的示例客戶計費門戶。
Panelbear 中的示例客戶計費門戶。
我所要做的就是創建一個新的客戶會話並將客戶重定向到 Stripe 的託管頁面之一。然後我監聽關於客戶是否升級/降級/取消的 webhooks 並相應地更新我的數據庫。
當然還有一些重要的部分,比如驗證 webhook 是否真的來自 Stripe(你必須使用秘密驗證請求籤名),但 Stripe 的文檔很好地涵蓋了所有要點。
我只有幾個計劃,所以我很容易在我的代碼庫中管理它們。我基本上有類似的東西:
# Plan constants
FREE = Plan(
code='free',
display_name='Free Plan',
features={'abc', 'xyz'},
monthly_usage_limit=5e3,
max_alerts=1,
stripe_price_id='...',
)
BASIC = Plan(
code='basic',
display_name='Basic Plan',
features={'abc', 'xyz'},
monthly_usage_limit=50e3,
max_alerts=5,
stripe_price_id='...',
)
PREMIUM = Plan(
code='premium',
display_name='Premium Plan',
features={'abc', 'xyz', 'special-feature'},
monthly_usage_limit=250e3,
max_alerts=25,
stripe_price_id='...',
)
# Helpers for easy access
ALL_PLANS = [FREE, BASIC, PREMIUM]
PLANS_BY_CODE = {p.code: p for p in ALL_PLANS}然後我可以在任何 API 端點、cron 作業和管理任務中使用它來確定哪些限制/功能適用於給定客戶。plan_code給定客戶的當前計劃是在模型上調用的列BillingProfile。我將用戶與賬單信息分開,因為我計劃在某個時候添加組織/團隊,這樣我就可以輕鬆地將 BillingProfile 遷移到帳戶所有者/管理員用戶。
當然,如果您在電子商務商店中提供數千種單獨的產品,則此模型不會擴展,但它對我來說效果很好,因為 SaaS 通常只有幾個計劃。
記錄
我不需要使用任何日誌記錄代理或類似的東西來檢測我的代碼。我只需登錄到 stdout,Kubernetes 就會自動為我收集和輪換日誌。我還可以使用FluentBit自動將這些日誌發送到 Elasticsearch/Kibana 之類的東西,但為了簡單起見,我還沒有這樣做。
為了檢查日誌,我使用了stern,這是一個用於 Kubernetes 的小型 CLI 工具,可以非常輕鬆地跨多個 pod 跟踪應用程序日誌。例如,stern -n ingress-nginx即使跨多個節點,也會跟踪我的 nginx pod 的訪問日誌。
監控告警
一開始我使用自託管的 Prometheus / Grafana 來自動監控我的集群和應用程序指標。但是,我不太願意自行託管我的監控堆棧,因為如果集群出現問題,我的警報系統也會隨之崩潰(不太好)。
如果有一件事永遠不應該發生故障,那就是您的監控系統,否則您基本上是在沒有儀表的情況下飛行。這就是為什麼我用託管服務 ( New Relic ) 交換了我的監控/警報系統。
我所有的服務都有一個 Prometheus 集成,可以自動記錄指標並將其轉發到兼容的後端,例如 Datadog、New Relic、Grafana Cloud 或自託管的 Prometheus 實例(我過去就是這麼做的)。要遷移到 New Relic,我所要做的就是使用他們的 Prometheus Docker 鏡像,並關閉自託管監控堆棧。
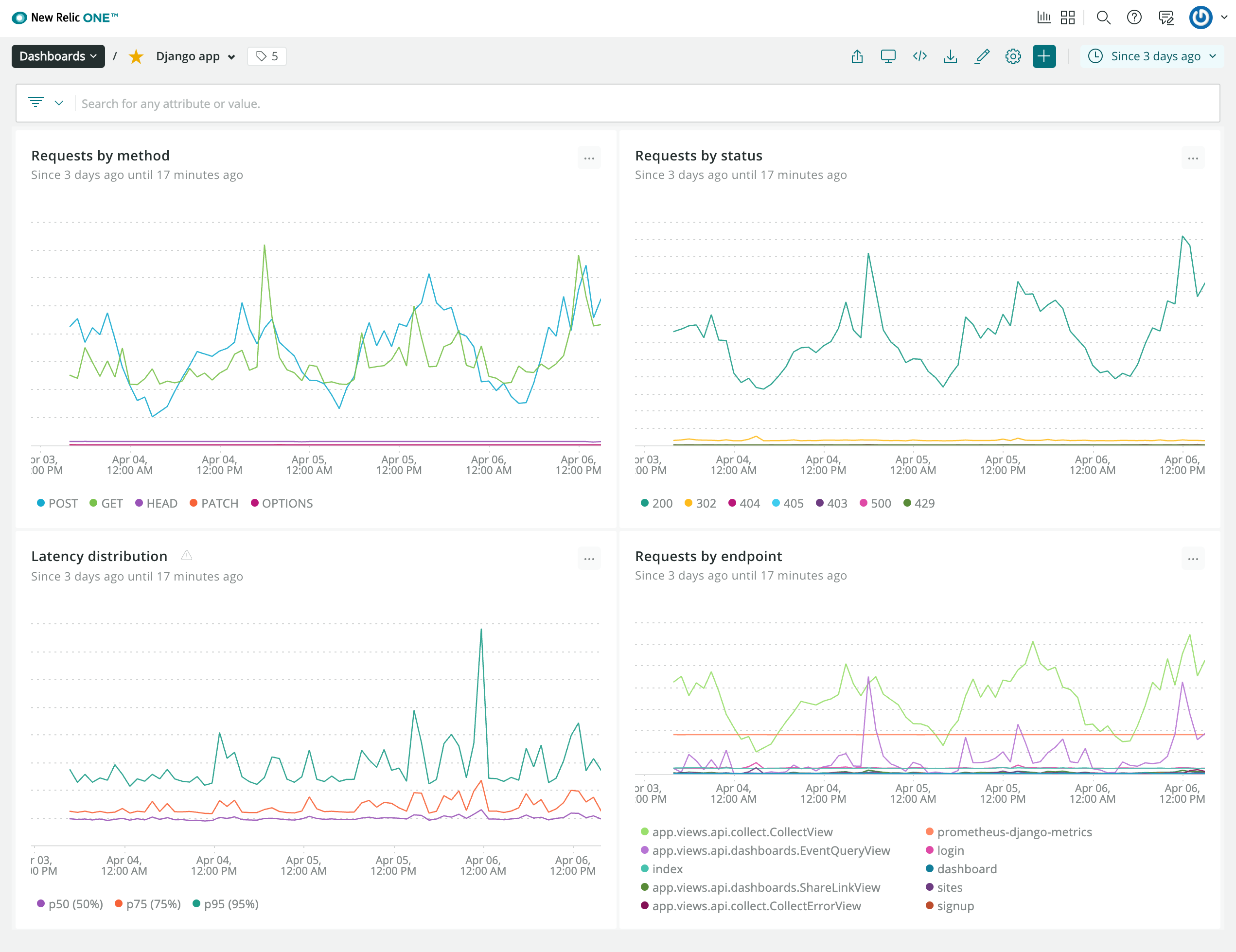 示例 New Relic 儀表板,其中包含最重要的統計數據摘要。
示例 New Relic 儀表板,其中包含最重要的統計數據摘要。
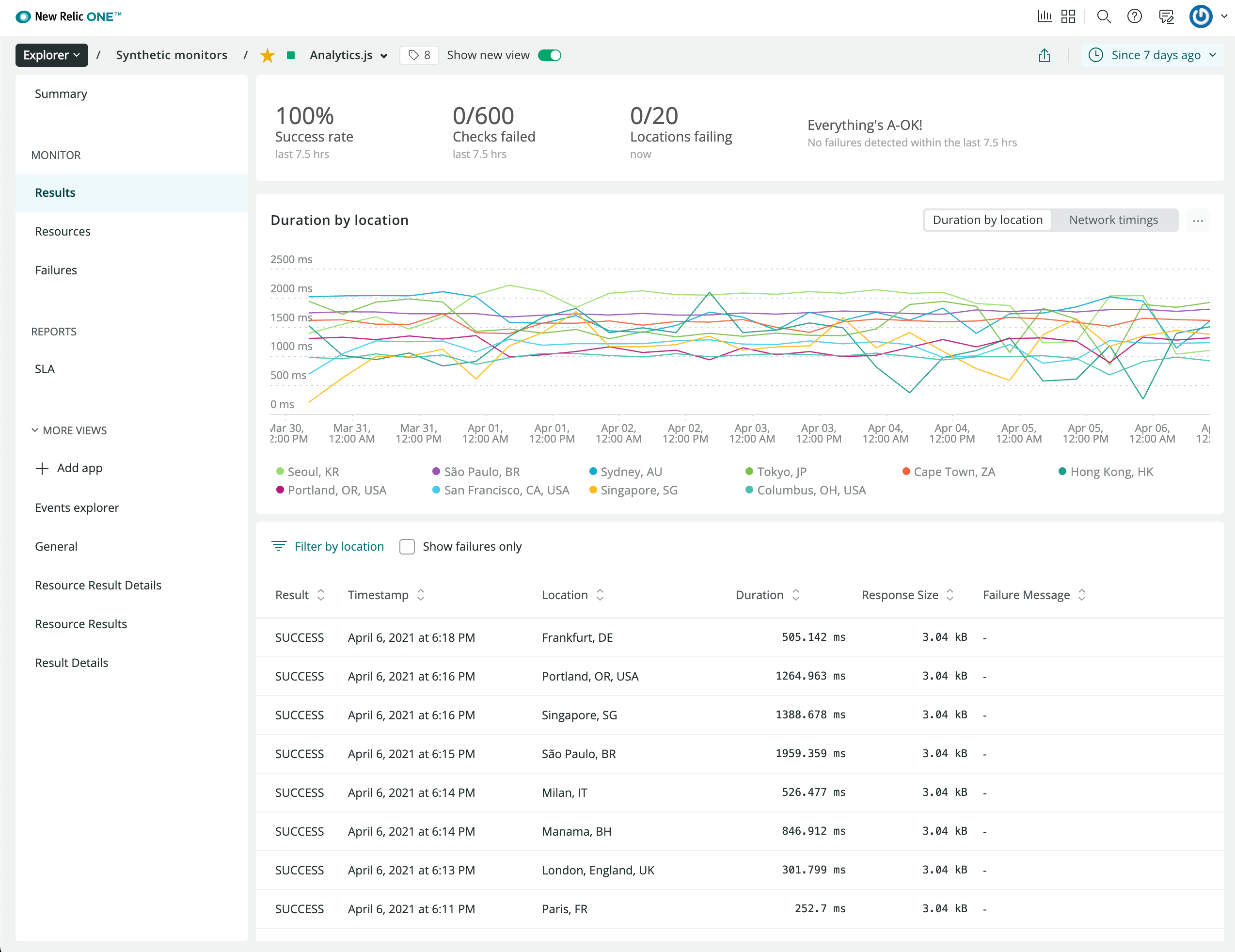 我還使用 New Relic 的探測器監控世界各地的正常運行時間。
我還使用 New Relic 的探測器監控世界各地的正常運行時間。
從自託管的 Grafana/Loki/Prometheus 堆棧遷移到 New Relic 減少了我的操作面。更重要的是,即使我的 AWS 區域出現故障,我仍然會收到警報。
您可能想知道我如何公開我的 Django 應用程序的指標。我利用優秀的django-prometheus庫,並在我的應用程序中簡單地註冊一個新的計數器/儀表:
from prometheus_client import Counter
EVENTS_WRITTEN = Counter(
"events_total",
"Total number of events written to the eventstore"
)
# We can increment the counter to record the number of events
# being written to the eventstore (ClickHouse)
EVENTS_WRITTEN.incr(count)它會在我的服務器端點公開這個指標和其他指標/metrics(只能在我的集群中訪問)。Prometheus 將每分鐘自動抓取此端點並將指標轉發給 New Relic。
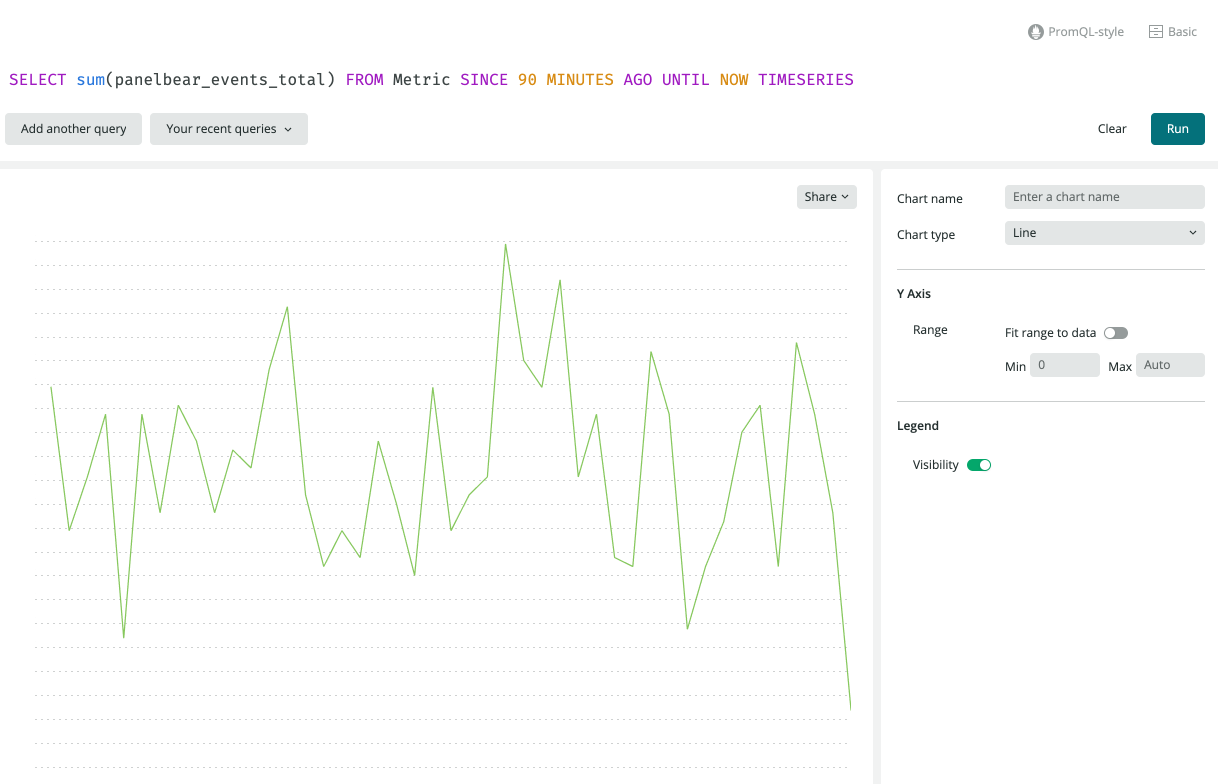 由於 Prometheus 集成,該指標會自動顯示在 New Relic 中。
由於 Prometheus 集成,該指標會自動顯示在 New Relic 中。
錯誤追踪
在開始錯誤跟踪之前,每個人都認為他們的應用程序中沒有錯誤。異常很容易在日誌中丟失,或者更糟的是您知道它但由於缺乏上下文而無法重現問題。
我使用Sentry匯總並通知我有關我的應用程序的錯誤。檢測我的 Django 應用程序非常簡單:
SENTRY_DSN = env.str("SENTRY_DSN", default=None)
# Init Sentry if configured
if SENTRY_DSN:
sentry_sdk.init(
dsn=SENTRY_DSN,
integrations=[DjangoIntegration(), RedisIntegration(), CeleryIntegration()],
# Do not send user PII data to Sentry
# See also inbound rules for special patterns
send_default_pii=False,
# Only sample a small amount of performance traces
traces_sample_rate=env.float("SENTRY_TRACES_SAMPLE_RATE", default=0.008),
)它非常有用,因為它會自動收集一堆關於異常發生時發生的情況的上下文信息:
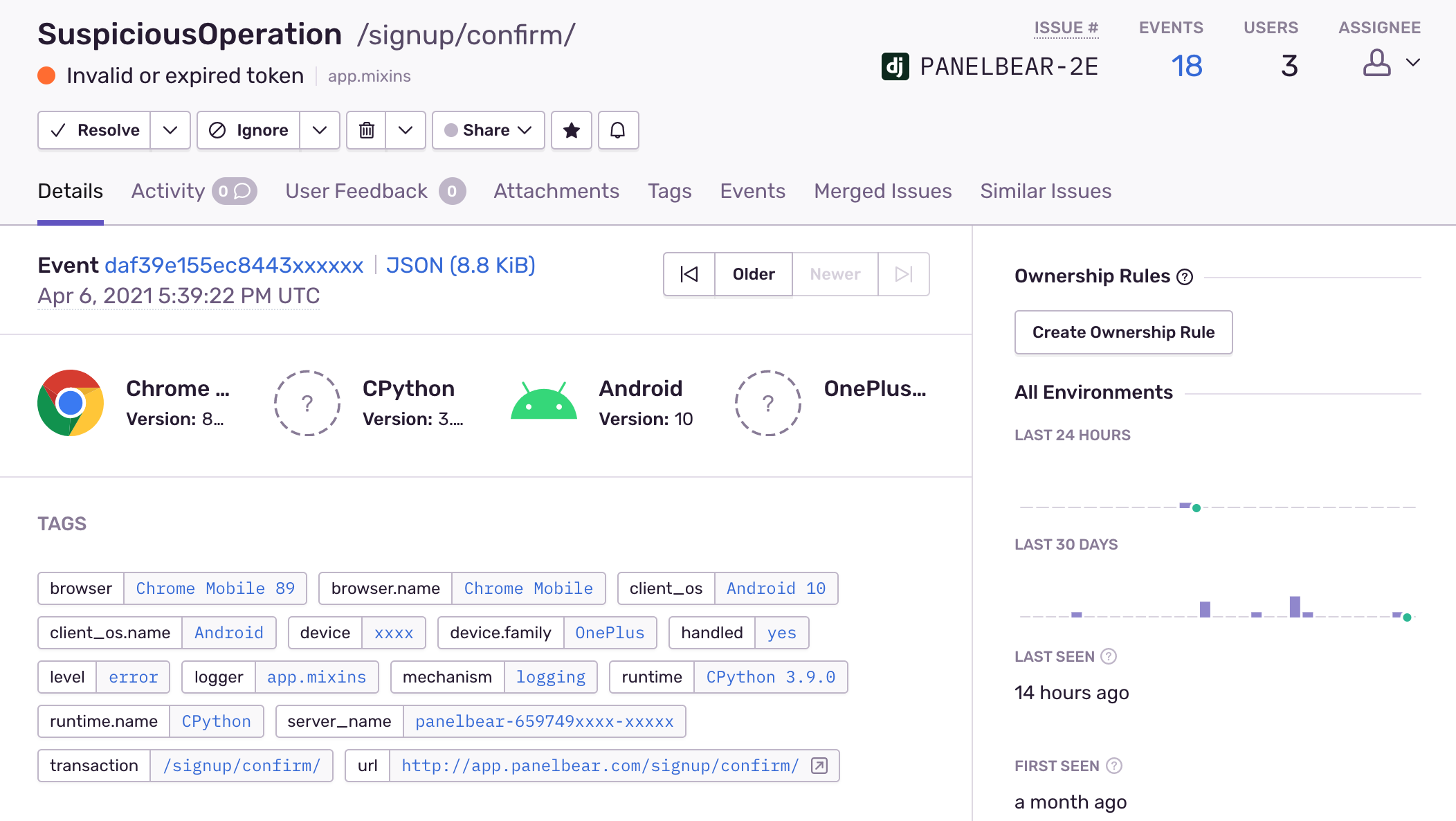 哨兵聚合併在出現異常時通知我。
哨兵聚合併在出現異常時通知我。
我使用 Slack#alerts通道來集中所有警報:停機、cron 作業失敗、安全警報、性能回歸、應用程序異常等等。這很棒,因為當多個服務同時向我發出看似無關的問題時,我經常可以將問題關聯起來。
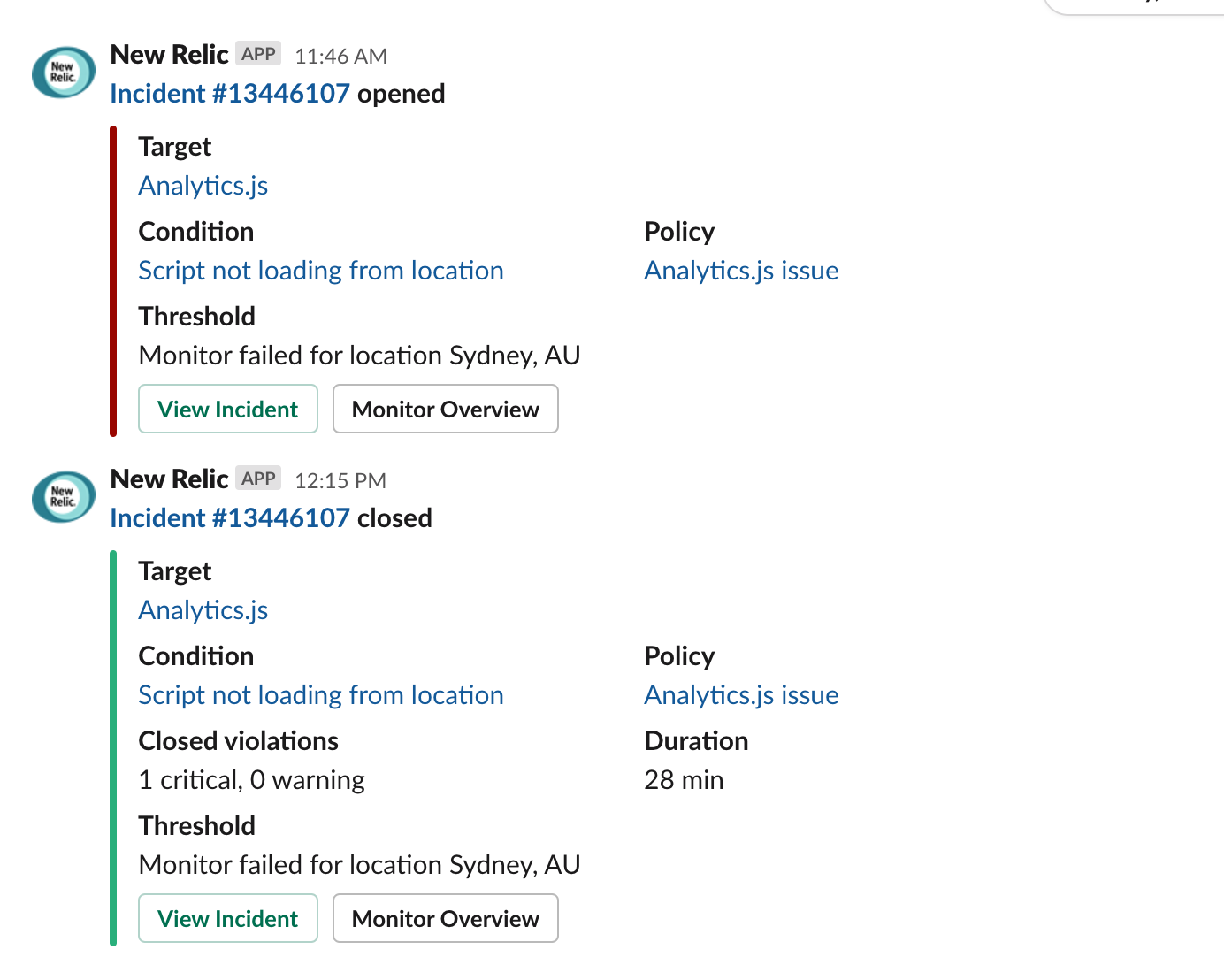 由於 CDN 端點在澳大利亞悉尼關閉而導致的 Slack 警報示例。
由於 CDN 端點在澳大利亞悉尼關閉而導致的 Slack 警報示例。
分析和其他好東西
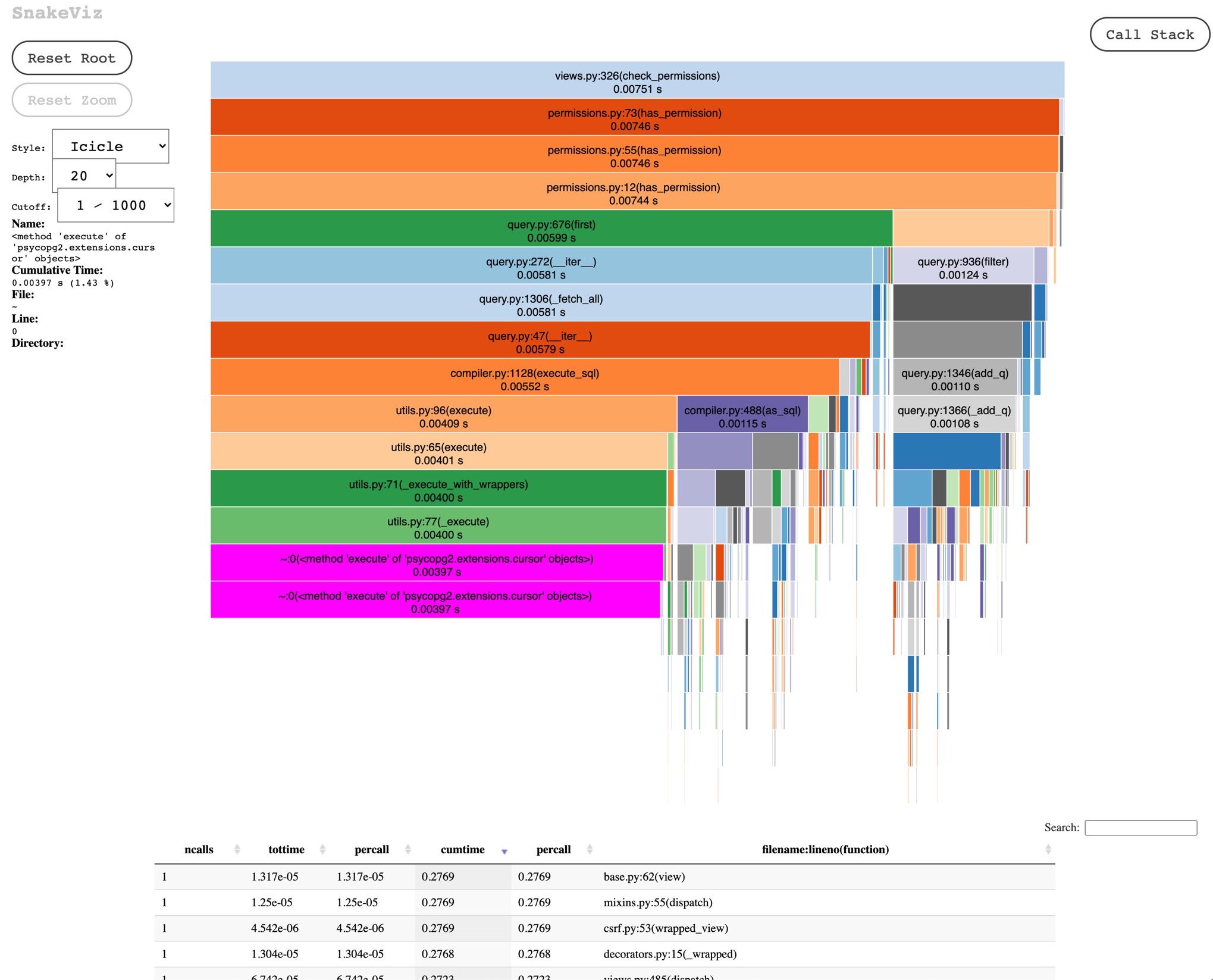
當我需要深入研究時,我還會使用cProfile和snakeviz等工具來更好地了解分配、調用次數和有關我的應用程序性能的其他統計數據。聽起來很花哨,但它們是非常易於使用的工具,並且在過去幫助我發現了各種問題,這些問題使我的儀表板因看似無關的代碼而變慢。
我還在本地計算機上使用Django 調試工具欄來輕鬆檢查視圖觸發的查詢、在開發過程中預覽外發電子郵件以及許多其他好東西。
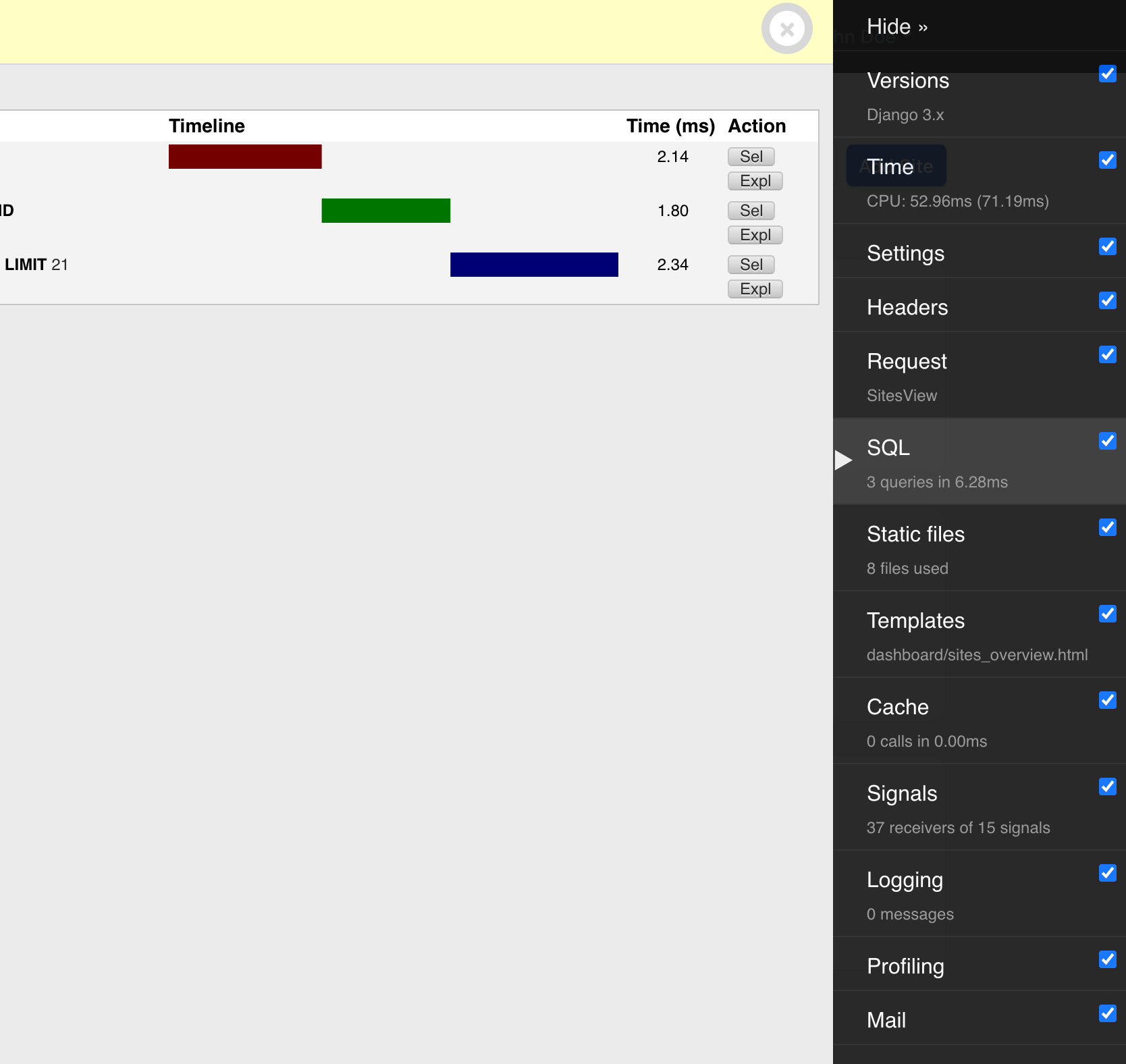 Django 的調試工具欄非常適合在本地開發人員中檢查內容,以及預覽交易電子郵件。
Django 的調試工具欄非常適合在本地開發人員中檢查內容,以及預覽交易電子郵件。
這就是所有人
如果你已經讀到這裡,我希望你喜歡這篇文章。它最終比我原先預期的要長很多,因為有很多地方需要覆蓋。
如果您還不熟悉這些工具,請考慮先使用託管平台,例如Render或 DigitalOcean 的App Platform(不隸屬於,只是聽說過這兩者的好消息)。它們將幫助您專注於您的產品,並且仍然可以獲得我在這裡談到的許多好處。
“你什麼都用 Kubernetes 嗎?” – 不,不同的項目,不同的需求。例如,此博客託管在Vercel上。
也就是說,我確實打算寫更多關於具體提示和技巧的後續帖子,並分享更多在此過程中學到的經驗教訓。尤其是作為一名工程師經營企業,因為我還有很多東西要學。





